This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A few months ago I wrote a blog post about event skew and how dangerous it is for a stateful streaming job. Since it was a high-level explanation, I didn't cover Apache Spark Structured Streaming deeply at that moment. Now the watermark topic is back to my learning backlog and it's a good opportunity to return to the event skew topic and see the dangers it brings for Structured Streaming stateful jobs.
PDF files are one of the most popular file formats today. Because they can preserve the visual layout of documents and are compatible with a wide range of devices and operating systems, PDFs are used for everything from business forms and educational material to creative designs. However, PDF files also present multiple challenges when it… Read more The post What Is PDFMiner And Should You Use It – How To Extract Data From PDFs appeared first on Seattle Data Guy.
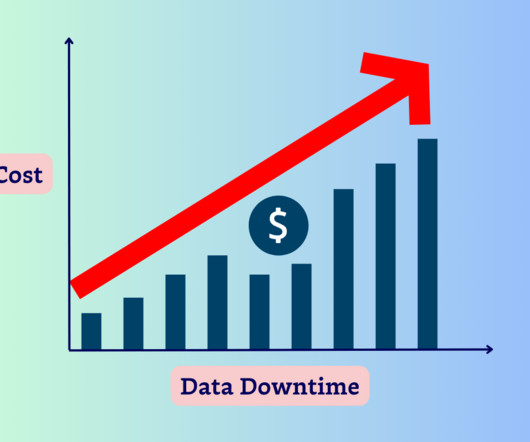
When data engineers tell scary stories around a campfire, its usually a cautionary tale about the cost of poor data quality. Data downtime can occur suddenly at any timeand often not when or where youre looking for it. And its cost is the scariest part of all. But just how much can data downtime actually cost your business? In this article, well learn from a real-life data downtime horror story to understand the cost of bad data, its impacts, and how to prevent it.
With over 30 million monthly downloads, Apache Airflow is the tool of choice for programmatically authoring, scheduling, and monitoring data pipelines. Airflow enables you to define workflows as Python code, allowing for dynamic and scalable pipelines suitable to any use case from ETL/ELT to running ML/AI operations in production. This introductory tutorial provides a crash course for writing and deploying your first Airflow pipeline.
Do types actually make developers more productive? Or is it just more typing on the keyboard? To answer that question were revisiting Diff Authoring Time (DAT) how Meta measures how long it takes to submit changes to a codebase. DAT is just one of the ways e measure developer productivity and this latest episode of the Meta Tech Podcast takes a look at two concrete use cases for DAT, including a type-safe mocking framework in Hack.
Do types actually make developers more productive? Or is it just more typing on the keyboard? To answer that question were revisiting Diff Authoring Time (DAT) how Meta measures how long it takes to submit changes to a codebase. DAT is just one of the ways e measure developer productivity and this latest episode of the Meta Tech Podcast takes a look at two concrete use cases for DAT, including a type-safe mocking framework in Hack.
A Deep Dive into Databricks Labs’ DQX: The Data Quality Game Changer for PySpark DataFrames Recently, a LinkedIn announcement caught my eyeand honestly, it had me on the edge of my seat. Databricks Labs has unveiled DQX, a Python-based Data Quality framework explicitly designed for PySpark DataFrames. Finally, a Dedicated Data Quality Tool for PySpark […] The post PySpark Data Quality on Databricks with DQX. appeared first on Confessions of a Data Guy.
Over the last three geospatial-centric blog posts, weve covered the basics of what geospatial data is, how it works in the broader world of data and how it specifically works in Snowflake based on our native support for GEOGRAPHY , GEOMETRY and H3. Those articles are great for dipping your toe in, getting a feel for the water and maybe even wading into the shallow end of the pool.
Rust is a systems programming language that offers high performance and safety. Python programmers will find Rust's syntax familiar but with more control over memory and performance.
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!
Electronic products are evolving at lightning speed, driven by an insatiable demand for new consumer devices, energy, transport, robotics, connectivity, data and beyond.
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? How does a self-driving car understand a chaotic street scene? The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. Unlike neatly organized rows and columns in spreadsheets, unstructured data—such as text, images, videos, and audio—requires advanced processing techniques to derive meaningful insights.
Y Combinator founder Paul Graham advises startup founders to live in the future, then build whats missing. I had the privilege of glimpsing the future through a series of interviews with investors on the bleeding edge of the AI landscape. Insights from these candid conversations laid the foundation for Startup 2025: Building a Business in the Age of AI, the AI startup report that Snowflake is publishing today.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
With the ever-growing focus on GenAI, many legacy BI tools have failed to invest in the analyst. By focusing solely on AI experiences for business teams, theyve alienated data teams, relegating analysts to disjointed tools and data silos. When in reality, businesses still need people who can help decision-makers assess messy data to diagnose and evaluate business problems.
Large language models (LLMs) are at the heart of generative AI transformations, driving solutions across industries from efficient customer support to simplified data analysis. Enterprises need performant, cost-effective and low-latency inference to scale their gen AI solutions. Yet, the complexity and computational demands of LLM inference present a challenge.
Large enterprises face unique challenges in optimizing their Business Intelligence (BI) output due to the sheer scale and complexity of their operations. Unlike smaller organizations, where basic BI features and simple dashboards might suffice, enterprises must manage vast amounts of data from diverse sources. What are the top modern BI use cases for enterprise businesses to help you get a leg up on the competition?
PodPrep AI, an AI-powered research assistant, leverages EDA and real-time streaming data using Confluent and Flink, in order to help its author with podcast preparation.
Questions that guide architectural decisions to balance functional requirements with non-functional ones, like latency and scalability Continue reading on Towards Data Science
Angel Vargas | Software Engineer, API Platform; Swati Kumar | Software Engineer, API Platform; Chris Bunting | Engineering Manager, APIPlatform The inside of the Pinterest lobby in Mexico City, showing a patterned ceiling, a receptionist deck with a plant on it, a light above it, and a gallery of images of pins youd find on Pinterest, behind it. To the left, a glowing Pinterest P sign hovers in front of a glasswall.
Whether you’re creating complex dashboards or fine-tuning large language models, your data must be extracted, transformed, and loaded. ETL and ELT pipelines form the foundation of any data product, and Airflow is the open-source data orchestrator specifically designed for moving and transforming data in ETL and ELT pipelines. This eBook covers: An overview of ETL vs.
AI is proving that its here to stay. While 2023 brought wonder, and 2024 saw widespread experimentation, 2025 will be the year that manufacturing enterprises get serious about AI's applications. But its complicated: AI proofs of concept are graduating from the sandbox to production, just as some of AIs biggest cheerleaders are turning a bit dour. How to navigate such a landscape is top of mind for me and top executives such as Snowflakes CEO, Sridhar Ramaswamy; Snowflakes Distinguished AI Engine
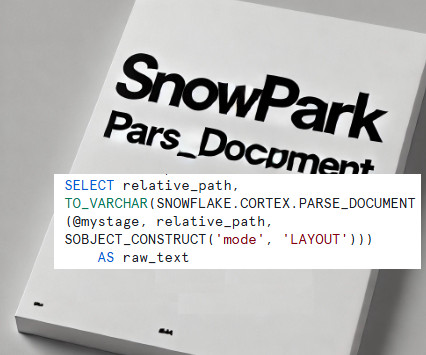
Read Time: 2 Minute, 33 Second Snowflakes PARSE_DOCUMENT function revolutionizes how unstructured data, such as PDF files, is processed within the Snowflake ecosystem. Traditionally, this function is used within SQL to extract structured content from documents. However, Ive taken this a step further, leveraging Snowpark to extend its capabilities and build a complete data extraction process.
Speaker: Jay Allardyce, Deepak Vittal, Terrence Sheflin, and Mahyar Ghasemali
As we look ahead to 2025, business intelligence and data analytics are set to play pivotal roles in shaping success. Organizations are already starting to face a host of transformative trends as the year comes to a close, including the integration of AI in data analytics, an increased emphasis on real-time data insights, and the growing importance of user experience in BI solutions.
Twenty years ago, data was little more than fuel for forecasting. A few marketing insights here. A couple financial reports there. Today, data doesnt simply support your productsmore often than not, it is the product. In the age of AI, data isnt just another cost centerits a value creator. Data teams arent service providerstheyre essential technology partners.
DareData will close 2024 with a 5% revenue growth compared to 2023. At first glance, given the rapid growth in our market, one might be tempted to classify this year as underwhelming. However, 2024 has been a transformative year for us. We started the year as a 100% consulting business. Consulting is highly dependent on people, and in small boutique firms like ours, this often means being heavily reliant on the partners.
Cloud Development Environments (CDEs) are changing how software teams work by moving development to the cloud. Our Cloud Development Environment Adoption Report gathers insights from 223 developers and business leaders, uncovering key trends in CDE adoption. With 66% of large organizations already using CDEs, these platforms are quickly becoming essential to modern development practices.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content