This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Google launched its Cloud Platform in 2008, six years after Amazon Web Services launched in 2002. But not long after Google launched GCP in 2008, it began gaining market traction. These EC2 instances come to EBS optimized by default and are powered by the AWS Nitro System. Launched in 2008.
And some sections which are the part of debate and undergoing experimentation and transformation by the pioneers who forged & nurture the systems. In which one system is a client which seeks the information and other system is a server who act and fulfil the request of the client. on our operating system.
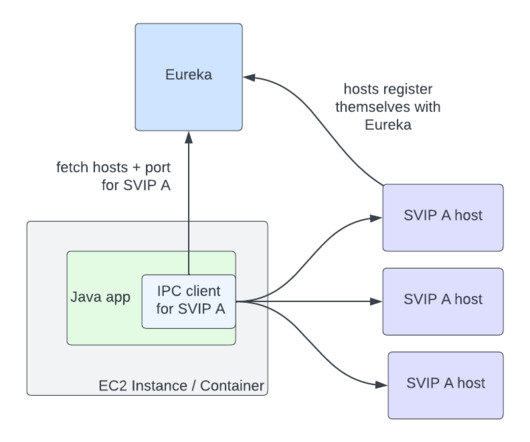
A brief history of IPC at Netflix Netflix was early to the cloud, particularly for large-scale companies: we began the migration in 2008, and by 2010, Netflix streaming was fully run on AWS. To improve availability, we designed systems where components could fail separately and avoid single points of failure.
Doug Cutting and Cafarella had only 5 machines to work with, requiring several manual steps to operate the system. With several Yahoo engineers and with the use of several thousand computers in 2007, Hadoop became a reliable and comparatively stable system for processing petabytes of data, using commodity hardware.
In 2008, two years after Cutting joined Yahoo, the company published Hadoop open source project. Hadoop is a Java-based Apache open source platform that enables the distributed processing of big datasets across computer clusters using simple programming techniques. Hadoop was split out from Nutch a few years later. Lack of talent .
Besides, it offers excellent managing and monitoring capabilities to help system admins and analysts increase productivity. Features The centralized data store integrates data from every system layer. Support is available for popular languages such as.NET, Java, and Node.js. Pros Supports all Azure PAAS services.
Also, don't forget to check out the Java Full Stack Developer syllabus to have an in-depth idea about the course curriculum and learning outcomes to get hired in the best companies. Contus Since its founding in 2008, Contus has been bringing a digital technology transformation to various businesses and industries.
Google launched its Cloud Platform in 2008, six years after Amazon Web Services launched in 2002. But not long after Google launched GCP in 2008, it began gaining market traction. These EC2 instances come to EBS optimized by default and are powered by the AWS Nitro System. Launched in 2008.
However, as the big data projects grow within an organization, there is a need to effectively operationalize these systems and maintain them. As MapReduce can run on low cost commodity hardware-it reduces the overall cost of a computing cluster but coding MapReduce jobs is not easy and requires the users to have knowledge of Java programming.
Did you know that Wes McKinney developed Python Pandas in 2008 and used it for Py data gathering? Pandas users can do things with a few code lines, which would take over ten or fifteen pieces of code in Java or C. The same holds for sophisticated deep learning systems like TensorFlow.
APACHE Hadoop Big data is being processed and stored using this Java-based open-source platform, and data can be processed efficiently and in parallel thanks to the cluster system. The Hadoop Distributed File System (HDFS) provides quick access. A public version of this best big data tool was created in 2008 by Facebook.
Additionally, they should have extensive knowledge of server-side technologies, such as Apache and NGINX, and database systems, such as MySQL and MongoDB. Your responsibilities at Shopify will include working on our merchants' stores, the Shopify Admin, and their EPOS system. The company is headquartered in Gurgaon, India.
The process of funnelling data into Hadoop systems is not as easy as it appears, because data has to be transferred from one location to a large centralized system. Decomposer - Contains large matrix decomposition algorithms implemented in Java. Access Job Recommendation System Project with Source Code PREVIOUS NEXT <
Also, don't forget to check out the Java Full Stack Developer syllabus to have an in-depth idea about the course curriculum and learning outcomes to get hired in the best companies. Contus Since its founding in 2008, Contus has been bringing a digital technology transformation to various businesses and industries.
Need for Commercial Hadoop Vendors Today, Hadoop is an open-source, catch-all technology solution with incredible scalability, low cost storage systems and fast paced big data analytics with economical server costs. Related Posts How much Java is required to learn Hadoop?
Google looked over the expanse of the growing internet and realized they’d need scalable systems. Cloudera was started in 2008, and HortonWorks started in 2011. Apache Pig in 2008 came too, but it didn’t ever see as much adoption. Apache HBase came in 2007, and Apache Cassandra came in 2008.
Blockchain technology initially became known when a person or group of people known as ‘Satoshi Nakamoto’ published a white paper titled “Bitcoin: A Peer-to-Peer Electronic Cash System” in 2008. Blockchain was developed in 2008 as a way to support Bitcoin, which was released a year later in 2009.
I’ve written an event sourcing bank simulation in Clojure (a lisp build for Java virtual machines or JVMs) called open-bank-mark , which you are welcome to read about in my previous blog post explaining the story behind this open source example. The schemas are also useful for generating specific Java classes. The bank application.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content