This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In the past decade, the amount of structured data created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructureddata, cloud data, and machine data – another 50 ZB.
1997 -The term “BIG DATA” was used for the first time- A paper on Visualization published by David Ellsworth and Michael Cox of NASA’s Ames Research Centre mentioned about the challenges in working with large unstructureddata sets with the existing computing systems. In 2011, it took only 2 days to generate 1.8
Data Store Another significant change from 2021 to 2024 lies in the shift from “Data Warehouse” to “Data Store,” acknowledging the expanding database horizon, including the rise of Data Lakes. Stream transformations represent a less mature area in comparison.
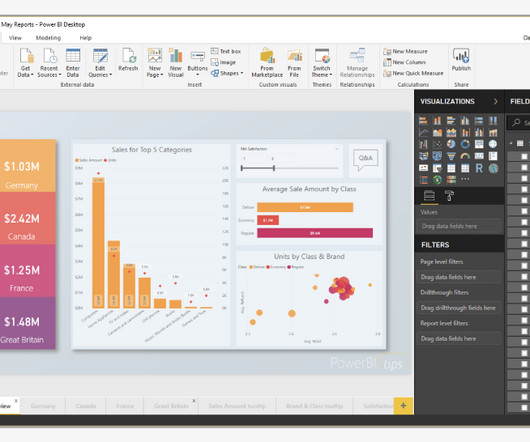
Power BI, originally called Project Crescent, was launched in July 2011, bundled with SQL Server. It was released as a standalone product in July 2015 after adding more features including enterprise-level data connectivity and security options, apart from its original Excel features like Power Query, Power Pivot, and Power View.
Table of Contents Statistics on Online Dating Big Data Analytics in Online Dating How Online Dating Alogirthms work? According to Juniper Research, the market for dating through mobile apps is expected to rise from $1 billion in 2011 to $2.3 billion by 2016. since 2008 and the Canadian dating industry amounts to $153 million.
The company was established in 2011, and as of right now, they employ about 250 people. Tata Consultancy Services Tata Consultancy Services is known among the big data companies in India. This strategy includes a partnership with Hortonworks, a big data company. The USA serves as the company's home base.
Let’s take a look at how Amazon uses Big Data- Amazon has approximately 1 million hadoop clusters to support their risk management, affiliate network, website updates, machine learning systems and more. Amazon launched a promotional offer in 2011 – “Amazon pays shoppers $5 if they walk out of the store without any purchases.”
5 Data pipeline architecture designs and their evolution The Hadoop era , roughly 2011 to 2017, arguably ushered in big data processing capabilities to mainstream organizations. Data then, and even today for some organizations, was primarily hosted in on-premises databases with non-scalable storage.
Using the company’s iWay DataMigrator, Information Builders customers can pull data into Jethro irrespective of where the data is stored. Then through the IB’s connector, users can index, build dynamic cubes and query for structured as well unstructureddata resulting faster response time.
MongoDB-NoSQL Database of the Developers and for the Developers “Big Data” is revolutionizing the world and an SQL solution is very expensive to tackle the evolving business demands.With 80% of data being unstructured, data management requirements cannot be effectively met with expensive relational database management systems quickly.
In emerging technologies, UNext Jigsaw has been an industry leader since 2011 when it first began offering courses in the field. This program will teach Data Science and Analytics from both a technical and business perspective. Career Support: As long as we can, we will continue supporting you in your career aspirations! .
Google BigQuery Data Analysis Workflows Google BigQuery Architecture- A Detailed Overview Google BigQuery Datatypes BigQuery Tutorial for Beginners: How To Use BigQuery? Since its public release in 2011, BigQuery has been marketed as a unique analytics cloud data warehouse tool that requires no virtual machines or hardware resources.
With 3 billion people online and 247 billion emails sent every day, a research estimates that 8 zettabytes of big data will be created in 2015. Image Credit : hortonworks As per big data industry trends , the hype of Big Data had just begun in 2011. In 2015, big data has evolved beyond the hype.
This data was mostly generated by various regulatory requirements, record keeping, compliance and patient care. Thus, the computing technology and infrastructure must be able to render a cost efficient implementation of: Parallel Data Processing that is unconstrained. Fault tolerance along with high avaiability of the system.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content