This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apache Hive and Apache Spark are the two popular BigData tools available for complex data processing. To effectively utilize the BigData tools, it is essential to understand the features and capabilities of the tools. Hive is built on top of Hadoop and provides the measures to read, write, and manage the data.
Whether you are a data engineer, data scientist or a bigdata developer looking to automate your data workflows, this blog on Airflow vs Luigi will help you navigate the world of workflow management with ease. Learn more about real-world bigdata applications with unique examples of bigdata projects.
Large commercial banks like JPMorgan have millions of customers but can now operate effectively-thanks to bigdata analytics leveraged on increasing number of unstructured and structured data sets using the open source framework - Hadoop. JP Morgan has massive amounts of data on what its customers spend and earn.
One of the most substantial bigdata workloads over the past fifteen years has been in the domain of telecom network analytics. The Dawn of Telco BigData: 2007-2012. Suddenly, it was possible to build a data model of the network and create both a historical and predictive view of its behaviour.
BigDataHadoop skills are most sought after as there is no open source framework that can deal with petabytes of data generated by organizations the way hadoop does. 2014 was the year people realized the capability of transforming bigdata to valuable information and the power of Hadoop in impeding it.
News on Hadoop – November 2015 2nd Generation Hadoop has become the most critical cloud applications platform, Nov 2, 2015, TechRepublic.com Hadoop version of 1.0 Hadoop second generation is designed to support real time applications where Hadoop is used not just as a storage system but as an application platform.
Introduction . “Hadoop” is an acronym that stands for High Availability Distributed Object Oriented Platform. That is precisely what Hadoop technology provides developers with high availability through the parallel distribution of object-oriented tasks. What is Hadoop in BigData? .
With the demand for bigdata technologies expanding rapidly, Apache Hadoop is at the heart of the bigdata revolution. It is labelled as the next generation platform for data processing because of its low cost and ultimate scalable data processing capabilities. billion by 2020. billion by 2020.
News on Hadoop-April 2017 AI Will Eclipse Hadoop, Says Forrester, So Cloudera Files For IPO As A Machine Learning Platform. Apache Hadoop was one of the revolutionary technology in the bigdata space but now it is buried deep by Deep Learning. combines various online tools and data feeds from the banks pool of 1.2
"Bigdata is at the foundation of all of the megatrends that are happening today, from social to mobile to the cloud to gaming."- ”- Atul Butte, Stanford With the bigdata hype all around, it is the fuel of the 21 st century that is driving all that we do. .”- said Chris Lynch, the ex CEO of Vertica.
It’s also called a Parallel Data processing Engine in a few definitions. Spark is utilized for Bigdata analytics and related processing. Spark (and its RDD) was developed(earliest version as it’s seen today), in 2012, in response to limitations in the MapReduce cluster computing paradigm. Basic knowledge of SQL.
According to the Industry Analytics Report, hadoop professionals get 250% salary hike. Java developers have increased probability to get a strong salary hike when they shift to bigdata job roles. If you are a java developer, you might have already heard about the excitement revolving around bigdatahadoop.
Retail bigdata analytics is the future of retail as it separates the wheat from the chaff. Retail industry is rapidly adopting the data centric technology to boost sales. Below we present 5 most interesting use cases in bigdata and Retail Industry , which retailers implement to get the most out of data.
It takes in approximately $36 million dollars from across 4300 US stores everyday.This article details into Walmart BigData Analytical culture to understand how bigdata analytics is leveraged to improve Customer Emotional Intelligence Quotient and Employee Intelligence Quotient. How Walmart is tracking its customers?
It is difficult to believe that the first Hadoop cluster was put into production at Yahoo, 10 years ago, on January 28 th , 2006. Ten years ago nobody was aware that an open source technology, like Apache Hadoop will fire a revolution in the world of bigdata. Happy Birthday Hadoop With more than 1.7
You can check out the BigData Certification Online to have an in-depth idea about bigdata tools and technologies to prepare for a job in the domain. To get your business in the direction you want, you need to choose the right tools for bigdata analysis based on your business goals, needs, and variety.
News on Hadoop-May 2016 Microsoft Azure beats Amazon Web Services and Google for Hadoop Cloud Solutions. MSPowerUser.com In the competition of the best BigDataHadoop Cloud solution, Microsoft Azure came on top – beating tough contenders like Google and Amazon Web Services. May 3, 2016. May 10, 2016.
Hadoop has continued to grow and develop ever since it was introduced in the market 10 years ago. Every new release and abstraction on Hadoop is used to improve one or the other drawback in data processing, storage and analysis. Apache Hive is an abstraction on Hadoop MapReduce and has its own SQL like language HiveQL.
It is possible today for organizations to store all the data generated by their business at an affordable price-all thanks to Hadoop, the Sirius star in the cluster of million stars. With Hadoop, even the impossible things look so trivial. So the big question is how is learning Hadoop helpful to you as an individual?
This is the reason why Data Science and bigdata analytics are at the cutting edge of every industry. The top companies that hire data engineers are as follows: Amazon It is the largest e-commerce company in the US founded by Jeff Bezos in 1944 and is hailed as a cloud computing business giant.
Think Python - How To Think Like a Computer Scientist The book "Think Python - How to Think Like a Computer Scientist" is the best python for data science book by Allen B. The first version was launched in August 2012, and the second edition was updated in December 2015 for Python 3. 1482 readers rated this book 4.36
That’s because Harvard Business School has named Data Scientist as the sexiest job of the 21st century. And, if you think this may not be true anymore because Harvard stated that in 2012, we have another interesting fact to share with you. Experience with Bigdata tools like Hadoop, Spark, etc.
Apache Hive and Apache Spark are the two popular BigData tools available for complex data processing. To effectively utilize the BigData tools, it is essential to understand the features and capabilities of the tools. Hive is built on top of Hadoop and provides the measures to read, write, and manage the data.
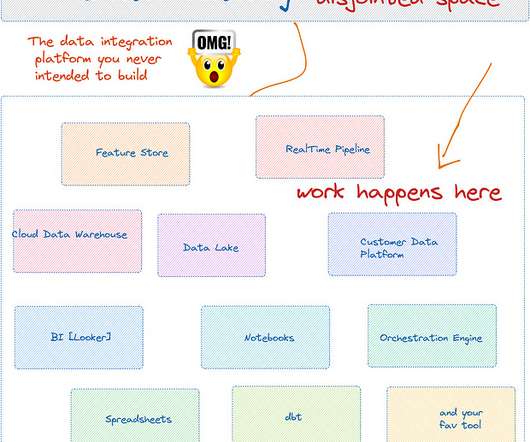
To understand better, Let’s step back and examine the data catalog of pre-modern-era and modern-era 1 Data Engineering. era of Data Catalog Let’s call the pre-modern era; as the state of Data Warehouses before the explosion of bigdata and subsequent cloud data warehouse adoption.
Acquire first-hand experience in learning Python packages for data processing and analysis. BigData: Principles and best practices of scalable real-time data systems BigData: Principles and Best Practices of Scalable Realtime Data Systems is an excellent resource for anyone who wants to learn the fundamentals of working with bigdata.
That’s because Harvard Business School has named Data Scientist as the sexiest job of the 21st century. And, if you think this may not be true anymore because Harvard stated that in 2012, we have another interesting fact to share with you. Experience with Bigdata tools like Hadoop, Spark, etc.
Amazon Redshift does the same for bigdata analytics and data warehousing. It contains columnar data store with billions of rows of data that are parallel placed with each other. This type of database management system uses sections of columns instead of rows to store the data. It is 10x faster than Hadoop.
Greg Rahn: Toward the end of that eight-year stint, I saw this thing coming up called Hadoop and an engine called Hive. It kind of was interesting to me that there were these big internet companies in the valley running this platform or a variation thereof of, based on Google research papers. Interesting times.
While traditional RDBMS databases served well the data storage and data processing needs of the enterprise world from their commercial inception in the late 1970s until the dotcom era, the large amounts of data processed by the new applications—and the speed at which this data needs to be processed—required a new approach.
Cracking a Hadoop Admin Interview becomes a tedious job if you do not spend enough time preparing for it.This article lists top Hadoop Admin Interview Questions and Answers which are likely to be asked when being interviewed for Hadoop Adminstration jobs. Table of Contents How to prepare for a Hadoop Admin Interview?
BigData is an immense amount of data that is constantly growing exponentially. Due to its vastness and complexity, no traditional data management system can adequately store or process this data. The New York Stock Exchange, which generates one terabyte of new trade data each day, is a classic example of bigdata.
Doug Cutting took those papers and created Apache Hadoop in 2005. They were the first companies to commercialize open source bigdata technologies and pushed the marketing and commercialization of Hadoop. Hadoop was hard to program, and Apache Hive came along in 2010 to add SQL. They eventually merged in 2012.
Cracking a Hadoop Admin Interview becomes a tedious job if you do not spend enough time preparing for it.This article lists top Hadoop Admin Interview Questions and Answers which are likely to be asked when being interviewed for Hadoop Adminstration jobs. Table of Contents How to prepare for a Hadoop Admin Interview?
As per McKinsey , 47% of organizations believe that data analytics has impacted the market in their respective industries. According to Forbes , in 2012 only 12% of Fortune 1000 companies reported having a CDO (Chief Data Officer). This number grew to 67.9% as of 2018, and is only increasing from there.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content