This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
dbt was born out of the analysis that more and more companies were switching from on-premise Hadoop data infrastructure to cloud data warehouses. Also dbt only does a pass-through to your underlying data compute technology, there is not any kind of processing within dbt. First let's understand why dbt exists.
Ten years ago, this data cluster was 300GB as a Hadoop cluster; that’s around a 100,000-fold increase in data stored! Decisions that come from ignorance are poor ones, such as “everyone else does it, so we should as well,” or “what we have works and I’m afraid of trying this new technology.”
The Dawn of Telco Big Data: 2007-2012. Advanced predictive analytics technologies were scaling up, and streaming analytics was allowing on-the-fly or data-in-motion analysis that created more options for the data architect. The Explosion in Telco Big Data: 2012-2017. Let’s examine how we got here.
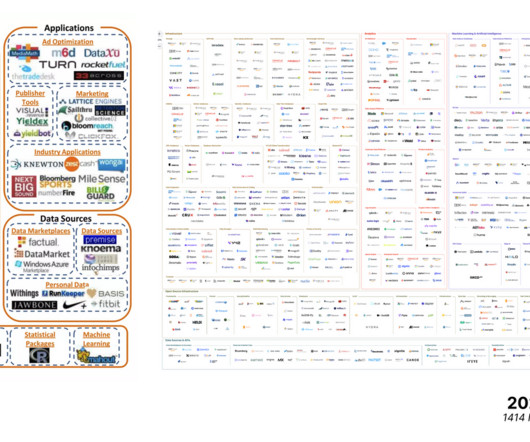
The MAD landscape The Machine learning, Artificial intelligence & Data (MAD) Landscape is a company index that has been initiated in 2012 by Matt Turck a Managing Director at First Mark. Evolution between 2012 and 2023. We jumped from 142 logos to 1414, the world changed but Pig remains.
Big Data Hadoop skills are most sought after as there is no open source framework that can deal with petabytes of data generated by organizations the way hadoop does. 2014 was the year people realized the capability of transforming big data to valuable information and the power of Hadoop in impeding it. million in 2012.
News on Hadoop – November 2015 2nd Generation Hadoop has become the most critical cloud applications platform, Nov 2, 2015, TechRepublic.com Hadoop version of 1.0 Hadoop second generation is designed to support real time applications where Hadoop is used not just as a storage system but as an application platform.
News on Hadoop-April 2017 AI Will Eclipse Hadoop, Says Forrester, So Cloudera Files For IPO As A Machine Learning Platform. Apache Hadoop was one of the revolutionary technology in the big data space but now it is buried deep by Deep Learning. Forbes.com, April 3, 2017. Hortonworks HDP 2.6 SiliconAngle.com, April 5, 2017.
According to the Industry Analytics Report, hadoop professionals get 250% salary hike. If you are a java developer, you might have already heard about the excitement revolving around big data hadoop. There are 132 Hadoop Java developer jobs currently open in London, as per cwjobs.co.uk
Spark (and its RDD) was developed(earliest version as it’s seen today), in 2012, in response to limitations in the MapReduce cluster computing paradigm. Spark installations can be done on any platform but its framework is similar to Hadoop and hence having knowledge of HDFS and YARN is highly recommended. Basic knowledge of SQL.
Snowflake was founded in 2012 around its data warehouse product, which is still its core offering, and Databricks was founded in 2013 from academia with Spark co-creator researchers, becoming Apache Spark in 2014. Snowflake is listed and had annual revenue of $2.8 billion , while Databricks achieved $2.4
It is difficult to believe that the first Hadoop cluster was put into production at Yahoo, 10 years ago, on January 28 th , 2006. Ten years ago nobody was aware that an open source technology, like Apache Hadoop will fire a revolution in the world of big data. Happy Birthday Hadoop With more than 1.7
Large commercial banks like JPMorgan have millions of customers but can now operate effectively-thanks to big data analytics leveraged on increasing number of unstructured and structured data sets using the open source framework - Hadoop. Hadoop allows us to store data that we never stored before.
News on Hadoop-May 2016 Microsoft Azure beats Amazon Web Services and Google for Hadoop Cloud Solutions. MSPowerUser.com In the competition of the best Big Data Hadoop Cloud solution, Microsoft Azure came on top – beating tough contenders like Google and Amazon Web Services. May 3, 2016. May 10, 2016. TheNewStack.io
Hadoop has continued to grow and develop ever since it was introduced in the market 10 years ago. Every new release and abstraction on Hadoop is used to improve one or the other drawback in data processing, storage and analysis. Apache Hive is an abstraction on Hadoop MapReduce and has its own SQL like language HiveQL.
You can master several crucial Python data science technologies from the Python data science handbook, including Pandas, Matplotlib, NumPy, Scikit-Learn, Machine Learning, IPython, etc. The first version was launched in August 2012, and the second edition was updated in December 2015 for Python 3. 1482 readers rated this book 4.36
It is possible today for organizations to store all the data generated by their business at an affordable price-all thanks to Hadoop, the Sirius star in the cluster of million stars. With Hadoop, even the impossible things look so trivial. So the big question is how is learning Hadoop helpful to you as an individual?
Introduction . “Hadoop” is an acronym that stands for High Availability Distributed Object Oriented Platform. That is precisely what Hadooptechnology provides developers with high availability through the parallel distribution of object-oriented tasks. What is Hadoop in Big Data? .
With the demand for big data technologies expanding rapidly, Apache Hadoop is at the heart of the big data revolution. Here are top 6 big data analytics vendors that are serving Hadoop needs of various big data companies by providing commercial support. The Global Hadoop Market is anticipated to reach $8.74
According to reports by DICE Insights, the job of a Data Engineer is considered the top job in the technology industry in the third quarter of 2020. These data have been accessible to us because of the advanced and latest technologies which are used in the collection of data. However, earning a bachelor's degree is not just enough.
Retail industry is rapidly adopting the data centric technology to boost sales. 2) Trends in Retail are changing at a very rapid pace due to enhanced methods of communications, changing technologies and varying consumer tastes making it difficult for retailers to analyze the changing trends without Retail Analytics.
And, if you think this may not be true anymore because Harvard stated that in 2012, we have another interesting fact to share with you. Desire to work on performing challenging tasks and mastering new technologies. Experience with Big data tools like Hadoop, Spark, etc. Good problem solving, presentation, and analytical skills.
2014 Kaggle Competition Walmart Recruiting – Predicting Store Sales using Historical Data Description of Walmart Dataset for Predicting Store Sales What kind of big data and hadoop projects you can work with using Walmart Dataset? Its scale in terms of customers, its scale in terms of products and its scale in terms of technology.”-said
Data tracking is becoming more and more important as technology evolves. You can check out the Big Data Certification Online to have an in-depth idea about big data tools and technologies to prepare for a job in the domain. Some open-source technology for big data analytics are : Hadoop. Apache Spark. Apache Storm.
Author Name: Nathan Marz, James Warren Year of Release: 2012 Goodreads Rating: 3.84/5 It covers popular technologies such as Apache Kafka, Apache Storm, and Apache Hadoop, giving users practical advice on developing and executing effective data pipelines. You can learn about cloud technologies from AWS data engineer books.
And, if you think this may not be true anymore because Harvard stated that in 2012, we have another interesting fact to share with you. Desire to work on performing challenging tasks and mastering new technologies. Experience with Big data tools like Hadoop, Spark, etc. Good problem solving, presentation, and analytical skills.
On the fundamental level, it is a combination of two technologies – Column-oriented technologies (columnar data store) and MPP (massively parallel processing). In November 2012, a preview beta was released. It is 10x faster than Hadoop. It is the fastest-growing service offered by the AWS. ’s older version.
I would like to start off by asking you to tell us about your background and what kicked off your 20-year career in relational database technology? Greg Rahn: Toward the end of that eight-year stint, I saw this thing coming up called Hadoop and an engine called Hive. I decided to jump ship in May of 2012 joining Cloudera.
founded in 2012. The stack is built on top of Apache Lucene and Apache Hadoop. Experimentation You can use DevOps Monitoring to experiment with new technologies and processes without risking any downtime or service interruptions. A DevOps Certification ensures that you're well-equipped with industry requirements.
Doug Cutting took those papers and created Apache Hadoop in 2005. They were the first companies to commercialize open source big data technologies and pushed the marketing and commercialization of Hadoop. Hadoop was hard to program, and Apache Hive came along in 2010 to add SQL. They eventually merged in 2012.
Big Data: Concepts, Technology and Architecture For data scientists, engineers, and database managers, Big Data is the best book to learn big data. Leveraging Apache technologies like Hadoop, Cassandra, Avro, Pig, Mahout, Oozie, and Hive to encapsulate, split, and isolate Big Data and virtualize Big Data servers.
According to Forbes , in 2012 only 12% of Fortune 1000 companies reported having a CDO (Chief Data Officer). Data analytics projects for practice help one identify their strengths and weaknesses with various big data tools and technologies. This number grew to 67.9% as of 2018, and is only increasing from there.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content