

Snowflake Ventures Invests in Anomalo for Advanced Data Quality
Snowflake
MARCH 12, 2025
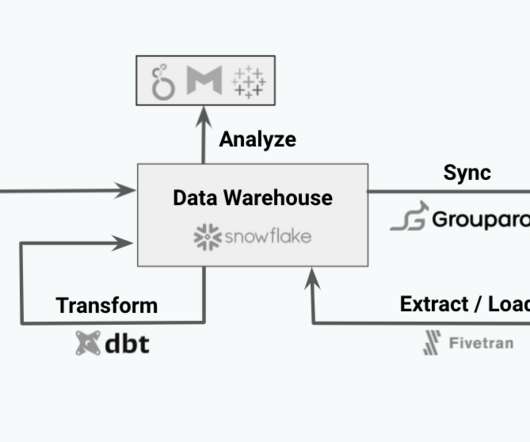
Anomalo was founded in 2018 by two Instacart alumni, Elliot Shmukler and Jeremy Stanley. While working together, they bonded over their shared passion for data. After experiencing numerous data quality challenges, they created Anomalo, a no-code platform for validating and documenting data warehouse information.













































Let's personalize your content