This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
News on Hadoop - February 2018 Kyvos Insights to Host Webinar on Accelerating Business Intelligence with Native Hadoop BI Platforms. PRNewswire.com, February 1, 2018. The leading big data analytics company Kyvo Insights is hosting a webinar titled “Accelerate Business Intelligence with Native Hadoop BI platforms.”
News on Hadoop - Janaury 2018 Apache Hadoop 3.0 goes GA, adds hooks for cloud and GPUs.TechTarget.com, January 3, 2018. The latest update to the 11 year old big data framework Hadoop 3.0 The latest update to the 11 year old big data framework Hadoop 3.0 This new feature of YARN federation in Hadoop 3.0
News on Hadoop - June 2018 RightShip uses big data to find reliable vessels.HoustonChronicle.com,June 15, 2018. The rating system gives one star rating to ships that are likely to experience an incident in the next year and a five star rating to ships which are least likely to do so. Zdnet.com, June 18, 2018.
HaaS will compel organizations to consider Hadoop as a solution to various big data challenges. Source - [link] ) Master Hadoop Skills by working on interesting Hadoop Projects LinkedIn open-sources a tool to run TensorFlow on Hadoop.Infoworld.com, September 13, 2018. September 24, 2018. from 2014 to 2020.With
News on Hadoop - March 2018 Kyvos Insights to Host Session "BI on Big Data - With Instant Response Times" at the Gartner Data and Analytics Summit 2018.PRNewswire.com, News on Hadoop - March 2018 Kyvos Insights to Host Session "BI on Big Data - With Instant Response Times" at the Gartner Data and Analytics Summit 2018.PRNewswire.com,
In 2018, the Wall Street Journal reported that every company is a tech company, suggesting that every company is likely to hire a tech co-founder for future growth. Learn to Interact with the DBMS Systems Many companies keep their data warehouses far from the stations where data can be accessed. are prevalent in the industry.
Preparing for a Hadoop job interview then this list of most commonly asked Apache Pig Interview questions and answers will help you ace your hadoop job interview in 2018. Research and thorough preparation can increase your probability of making it to the next step in any Hadoop job interview.
News on Hadoop - December 2017 Apache Impala gets top-level status as open source Hadoop tool.TechTarget.com, December 1, 2017. Apache Impala puts special emphasis on high concurrency and low latency , features which have been at times eluded from Hadoop-style applications. Source : [link] ) 4 Big Data Trends To Watch In 2018.
First, remember the history of Apache Hadoop. The two of them started the Hadoop project to build an open-source implementation of Google’s system. The two of them started the Hadoop project to build an open-source implementation of Google’s system. It staffed up a team to drive Hadoop forward, and hired Doug.
Hadoop has now been around for quite some time. But this question has always been present as to whether it is beneficial to learn Hadoop, the career prospects in this field and what are the pre-requisites to learn Hadoop? By 2018, the Big Data market will be about $46.34 billion dollars worth. between 2013 - 2020.
Professionals looking for a richly rewarded career, Hadoop is the big data technology to master now. Big Data Hadoop Technology has paid increasing dividends since it burst business consciousness and wide enterprise adoption. According to statistics provided by indeed.com there are 6000+ Hadoop jobs postings in the world.
The Data Lake architecture was proposed in a period of great growth in the data volume, especially in non-structured and semi-structured data, when traditional Data Warehouse systems start to become incapable of dealing with this demand. FULL DATA FROM 2018 df_acidentes_2018 = ( spark.read.format("csv").option("delimiter",
Big data and hadoop are catch-phrases these days in the tech media for describing the storage and processing of huge amounts of data. Over the years, big data has been defined in various ways and there is lots of confusion surrounding the terms big data and hadoop. Big Deal Companies are striking with Big Data Analytics What is Hadoop?
They are required to have deep knowledge of distributed systems and computer science. Building data systems and pipelines Data pipelines refer to the design systems used to capture, clean, transform and route data to different destination systems, which data scientists can later use to analyze and gain information.
This blog post gives an overview on the big data analytics job market growth in India which will help the readers understand the current trends in big data and hadoop jobs and the big salaries companies are willing to shell out to hire expert Hadoop developers. It’s raining jobs for Hadoop skills in India.
Initially, network monitoring and service assurance systems like network probes tended not to persist information: they were designed as reactive, passive monitoring tools that would allow you to see what was going on at a point in time, after a network problem had occurred, but the data was never retained. Let’s examine how we got here.
This proactive approach improves operational efficiency and enhances IT systems' reliability and performance. At its core, AIOps aims to automate and optimize IT operations by leveraging AI techniques to analyze and interpret vast amounts of data generated by various IT systems and applications. billion in 2017 to USD 11.02
This is useful to get a dump of the data, but very batchy and not always so appropriate for actually integrating source database systems into the streaming world of Kafka. So far we’ve just pulled entire tables into Kafka on a scheduled basis. So it must be something that Kafka Connect is doing when it executes it. Pretty innocuous, right?
But this data is all over the place: It lives in the cloud, on social media platforms, in operational systems, and on websites, to name a few. If the server is down, you risk leaving all operational systems without any data feeding. While they work, such structures produce several challenges. No support for batch data.
Apache Kafka ® is a distributed system. His career has always involved data, from the old worlds of COBOL and DB2, through the worlds of Oracle and Hadoop and into the current world with Kafka. His particular interests are analytics, systems architecture, performance testing and optimization. Is anyone listening?
Many open-source data-related tools have been developed in the last decade, like Spark, Hadoop, and Kafka, without mention all the tooling available in the Python libraries. You probably already saw Matt Turck’s 2021 Machine Learning, AI and Data (MAD) Landscape. And the bad part — the instructions manual is not included. 2] What is BigQuery?
Forrester describes Big Data Fabric as, “A unified, trusted, and comprehensive view of business data produced by orchestrating data sources automatically, intelligently, and securely, then preparing and processing them in big data platforms such as Hadoop and Apache Spark, data lakes, in-memory, and NoSQL.”.
Let’s revisit how several of those key table formats have emerged and developed over time: Apache Avro : Developed as part of the Hadoop project and released in 2009, Apache Avro provides efficient data serialization with a schema-based structure.
Software Development and Integration- Create software applications and integrate ML models into existing systems. Mathematical Expertise- Strong understanding of statistics, linear algebra, and probability to make sense of structured/unstructured data, algorithms, and machine learning systems. billion in 2023 to $92.7
Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets. Job Opportunities Surge: The demand for data engineers is surging, the job growth rate for Data Engineers is expected to be 21% from 2018-2088.
Preparing for a Hadoop job interview then this list of most commonly asked Apache Pig Interview questions and answers will help you ace your hadoop job interview in 2018. Research and thorough preparation can increase your probability of making it to the next step in any Hadoop job interview.
He specializes in distributed systems and data processing at scale, regularly working on data pipelines and taking complex analyses authored by data scientists/analysts and keeping them running in production. Francesco recently founded Amethix, a European software company that specializes in big data analytics and critical systems.
Traditional Frameworks of Big data like Apache Hadoop and all the tools within its ecosystem are Java-based, and hence using java opens up the possibility of utilizing a large ecosystem of tools in the big data world. JVM is a foundation of Hadoop ecosystem tools like Map Reduce, Storm, Spark, etc.
The practice of designing, building, and maintaining the infrastructure and systems required to collect, process, store, and deliver data to various organizational stakeholders is known as data engineering. Data engineers are experts who specialize in the design and execution of data systems and infrastructure. Who are Data Engineers?
Greg Rahn: I first got introduced to SQL relational database systems while I was in undergrad. I was a student system administrator for the campus computing group and at that time they were migrating the campus phone book to a new tool, new to me, known as Oracle. Michael Moreno: That’s great.
a recommendation system) to data engineers for actual implementation. They are the first people to tackle the influx of structured and unstructured data that enters a company’s systems. Business Insider reports that there will be more than 64 billion IoT devices by 2025, up from about 10 billion in 2018, and 9 billion in 2017″.
1997 -The term “BIG DATA” was used for the first time- A paper on Visualization published by David Ellsworth and Michael Cox of NASA’s Ames Research Centre mentioned about the challenges in working with large unstructured data sets with the existing computing systems. Truskowski. zettabytes. Zettabytes of information.
Estimates vary, but the amount of new data produced, recorded, and stored is in the ballpark of 200 exabytes per day on average, with an annual total growing from 33 zettabytes in 2018 to a projected 169 zettabytes in 2025. With that said, these systems tend to be less flexible and lack operational transparency.
Let’s explore the stages where current AutoML systems already show or at least promise the best results. Google entered the automated machine learning area in 2018. Besides tabular data, the system performs text and image processing. DataBricks AutoML: a smart system revolving around Spark and Big Data.
For a great overview on the need for these new database designs, I highly recommend watching the presentation, Stanford Seminar - Big Data is (at least) Four Different Problems , that database guru Michael Stonebraker delivered for Stanford’s Computer Systems Colloquium.
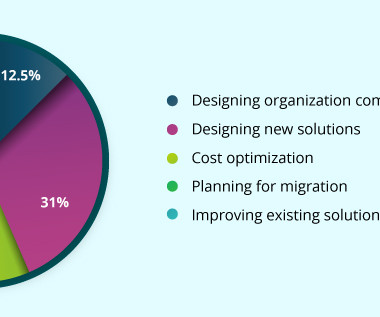
Planning for migration – 15% Improving existing solutions – 29% AWS Certified Solutions Architect – Associate learning path Learning path to become an AWS Certified Solutions Architect – Associate is designed in such a way that anyone can learn designing systems and applications on the AWS platform. will be covered.
According to an Indeed Jobs report, the share of cloud computing jobs has increased by 42% per million from 2018 to 2021. On the non-functional side, you must prioritize security, usability, and availability as the primary system qualities. have cloud-based systems implemented for managing the campus activities.
Adaptable pricing system When opposed to AWS, the pricing structure is less adaptable. AWS’s core analytics offering EMR ( a managed Hadoop, Spark, and Presto solution) helps set up an EC2 cluster and integrates various AWS services. Connection with the open-source community is strained.
Hive partitions are represented, effectively, as directories of files on a distributed file system. For example, if your partition key is date, a range could could be (Min: “2018-01-01”, Max: “2019–01–01”). A common stack for Spark, one we use at Airbnb, is to use Hive tables stored on HDFS as your input and output datastore.
Table of Contents Hadoop Hive Interview Questions and Answers Scenario based or Real-Time Interview Questions on Hadoop Hive Other Interview Questions on Hadoop Hive Hadoop Hive Interview Questions and Answers 1) What is the difference between Pig and Hive ? Usually used on the server side of the hadoop cluster.
Google looked over the expanse of the growing internet and realized they’d need scalable systems. Doug Cutting took those papers and created Apache Hadoop in 2005. They were the first companies to commercialize open source big data technologies and pushed the marketing and commercialization of Hadoop.
The capability of adapting to new software systems and technologies. Bureau of Labor Statistics (BLS)*, where business analyst jobs are expected to grow 14% from 2018 to 2028. Experts of specific subjects who use the new project or system. Business Analysts use it to describe the requirements and outline of software systems.
as of 2018, and is only increasing from there. 10+ Real-Time Azure Project Ideas for Beginners to Practice Access Job Recommendation System Project with Source Code Why Should Students Work on Big Data Analytics Projects ? billion in 2018 and is estimated to reach $201.2 This number grew to 67.9% billion in 2025.
Table of Contents Hadoop Hive Interview Questions and Answers Scenario based or Real-Time Interview Questions on Hadoop Hive Other Interview Questions on Hadoop Hive Hadoop Hive Interview Questions and Answers 1) What is the difference between Pig and Hive ? Usually used on the server side of the hadoop cluster.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content