This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Applying a clustering algorithm is much easier than selecting the best one. Each type offers pros and cons that must be considered if you’re striving for a tidy cluster structure.
However, as we expanded our set of personalization algorithms to meet increasing business needs, maintenance of the recommender system became quite costly. Incremental training : Foundation models are trained on extensive datasets, including every members history of plays and actions, making frequent retraining impractical. Zhai et al.,
While mature algorithms and extensive open-source libraries are widely available for machine learning practitioners, sufficient data to apply these techniques remains a core challenge. Discover how to leverage scikit-learn and other tools to generate synthetic data appropriate for optimizing and fine-tuning your models.
We will cover how you can use them to enrich and visualize your data, add value to it with powerful graph algorithms, and then send the result right back to Kafka. Step 2: Using graph algorithms to recommend potential friends. Link prediction algorithms. Common Neighbors algorithm.
According to the marketanalysis.com report forecast, the global Apache Spark market will grow at a CAGR of 67% between 2019 and 2022. billion (2019 – 2022). You can view the same data as both graphs and collections, transform and join graphs with RDDs efficiently, and write custom iterative graph algorithms using the Pregel API.
Comparing the performance of ORC and Parquet on spatial joins across 2 Billion rows on an old Nvidia GeForce GTX 1060 GPU on a local machine Photo by Clay Banks on Unsplash Over the past few weeks I have been digging a bit deeper into the advances that GPU data processing libraries have made since I last focused on it in 2019.
Practical use cases for speech & music activity Audio dataset preparation Speech & music activity is an important preprocessing step to prepare corpora for training. Nevertheless, noisy labels allow us to increase the scale of the dataset with minimal manual efforts and potentially generalize better across different types of content.
I was also very happy to find an AoC dataset on Hugging Face going all the way back to 2015. Failure modes For one of the years (2019) I took a closer look at the puzzles where o1-mini had failed to give the correct answer. They are instead following patterns from their training dataset.
This book's publisher is "No Starch Press," and the second edition was released on November 12, 2019. Let’s study them further below: Machine learning : Tools for machine learning are algorithmic uses of artificial intelligence that enable systems to learn and advance without a lot of human input.
Deep Learning, a subset of AI algorithms, typically requires large amounts of human annotated data to be useful. It aims to protect AI stakeholders from the effects of biased, compromised or skewed datasets. In 2019 OpenAI reported that the computational power used in the largest AI trainings has been doubling every 3.4
However, recommendations aren’t just about algorithms; it’s about helping our customers save time, find the right things, and curate the shopping experience they deserve. The ground truth was the final basket in the dataset for each customer. What do we have, what do we want?
But nothing is impossible for people armed with intellect and algorithms. Preparing airfare datasets. Read our article Preparing Your Dataset for Machine Learning to avoid common mistakes and handle your information properly. Public datasets. There are also free datasets — for instance, Flight Fare Prediction on Kaggle.
Data Scientists, also touted as the "sexiest job of the 21st century", have seen job postings for it rise by 256% over the year 2019. These streams basically consist of algorithms that seek to make either predictions or classifications by creating expert systems that are based on the input data.
There is no clear outline on how to study Machine Learning/Deep Learning due to which many individuals apply all the possible algorithms that they have heard of and hope that one of implemented algorithms work for their problem in hand.
Online fraud cases using credit and debit cards saw a historic upsurge of 225 percent during the COVID-19 pandemic in 2020 as compared to 2019. As per the NCRB report, the tally of credit and debit card fraud stood at 1194 in 2020 compared to 367 in 2019. Generally, these algorithms are known as anomaly detection.
Indexing vectors: Indexing algorithms can help to search across billions of vectors quickly and efficiently. Indexing algorithms for vectors do not natively support updates well. Indexing algorithms are designed to be large, static and monolithic making it difficult to run queries that join vectors and metadata efficiently.
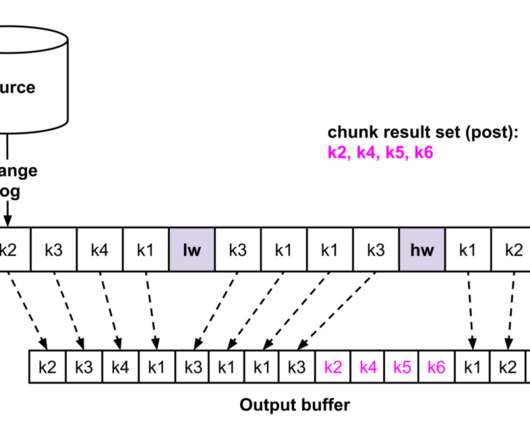
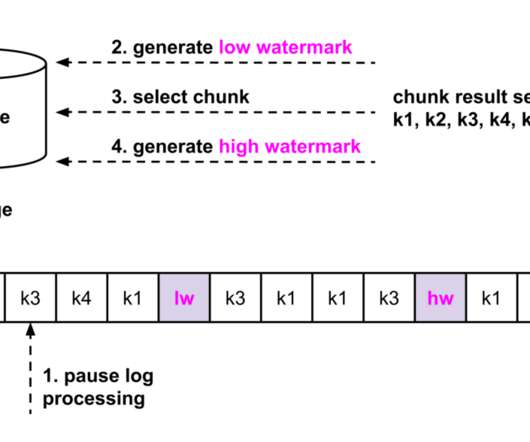
Dump Processing Dumps are needed as transaction logs have limited retention, which prevents their use for reconstituting a full source dataset. Figures 2a and 2b are illustrating the chunk selection algorithm. The watermark algorithm for chunk selection (steps 1–4). The watermark algorithm for chunk selection (steps 5–7).
Dump Processing Dumps are needed as transaction logs have limited retention, which prevents their use for reconstituting a full source dataset. Figures 2a and 2b are illustrating the chunk selection algorithm. The watermark algorithm for chunk selection (steps 1 to 4). The watermark algorithm for chunk selection (steps 5–7).
The ai and machine learning job opportunities have grown by 32% since 2019, according to Linkedin’s ‘ Jobs on the Rise ’ list in 2021. Machine learning, a subdomain of artificial intelligence, uses algorithms and data to imitate how humans learn and steadily improve.
On the surface, ML algorithms take the data, develop their own understanding of it, and generate valuable business insights and predictions — all without human intervention. It boosts the performance of ML specialists relieving them of repetitive tasks and enables even non-experts to experiment with smart algorithms.
First of all, this is an increase of around 5 percent over the summer of 2019: It’s already an indicator that things are going pretty well. Dataset preparation and construction. As of now, we’ll focus on such steps as finding the right data and constructing the dataset to build an ML-powered occupancy rate prediction module.
There is a wide range of open-source machine learning algorithms and tools that fit exceptionally with financial data. You can start the stock price prediction project by applying simple ML algorithms like Averaging and Linear Regression. Also, remove all missing and NaN values from the dataset, as incomplete data is unnecessary.
Projects help you create a strong foundation of various machine learning algorithms and strengthen your resume. Each project explores new machine learning algorithms, datasets, and business problems. In this ML project, you will learn to implement the random forest regressor and Xgboost algorithms to train the model.
Data scientists had three times as many available opportunities in 2020 as in 2019. These projects should include working with various datasets, and each one should present intriguing insights you found. Several machine learning initiatives, each centered on a different algorithm, can be what you need.
Neural networks are used t0 provide solutions using different types of image text and audio datasets. A deep learning engineer uses the algorithms and techniques developed by the researchers and applies them to real-world problems, which help create solutions. Because of these numerous hidden layers, we call this neural network "deep."
The bureau’s report also suggests that we are likely to witness an increase in the jobs of management analysts by 11% between 2019 and 2029. Additionally, you will learn how to implement Apriori and Fpgrowth algorithms over the given dataset. The rate is pretty higher than the average for other occupations.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. As per a 2020 report by DICE, data engineer is the fastest-growing job role and witnessed 50% annual growth in 2019. as they effectively summarise and label the data.
Choosing the Right Clustering Algorithm for your Dataset; DeepMind Has Quietly Open Sourced Three New Impressive Reinforcement Learning Frameworks; A European Approach to Masters Degrees in Data Science; The Future of Analytics and Data Science. Also: How AI will transform healthcare (and can it fix the US healthcare system?);
Between 2019-02-01 and 2019-05-01, find the customer with the highest overall order cost. Also, assume that each first name in the dataset is distinct. Suppose a company has created a search algorithm that will scan through user comments and display the search results to the user.
A Converged Index allows analytical queries on large datasets to return in milliseconds. A query can efficiently fetch exactly the columns that it needs, which makes it great for analytical queries over wide datasets. You can learn more in this great article: Algorithms Behind Modern Storage Systems. We are also hiring.
Candidates are aware of the keyword matching algorithm, and many of them insert as many keywords as possible into their resumes to get shortlisted by the company. You can use the Resume Dataset available on Kaggle to build this model. This dataset contains only two columns — job title and the candidate’s resume information.
According to marketanalysis.com survey, the Apache Spark market worldwide will grow at a CAGR of 67% between 2019 and 2022. billion (2019 - 2022). It achieves this using abstraction layer called RDD (Resilient Distributed Datasets) in combination with DAG, which is built to handle failures of tasks or even node failures.
For example, quantum computers could be used to crack highly secure encryption algorithms. However, with advancements in technology and huge datasets to analyze, the field is making big strides in how it can be used. They could also be used to break advanced cybersecurity protection measures, like antivirus software.
theme of the ML Platform meetup hosted at Netflix, Los Gatos on Sep 12, 2019. As with other traditional machine learning and deep learning paths, a lot of what the core algorithms can do depends upon the support they get from the surrounding infrastructure and the tooling that the ML platform provides.
“Data Scientist” job was ranked as the best job in America for four consecutive years in a row ( 2016-2019). Knowledge of machine learning algorithms and deep learning algorithms. Experience in handling large datasets and drawing meaningful conclusions from them. Strong statistical and mathematical skills.
That’s why, for now, smart algorithms see fewer restrictions and wider adoption in the drug discovery phase that happens prior to tests on people. When applied to drug discovery, smart algorithms have already proved their ability. Among deep learning algorithms employed for de novo design are. Real-life examples.
Netflix has built content recommendation algorithms that are responsible for 80% of the content streamed on their platform, saving the company $1B annually ( Dataconomy ). In 2019, Facebook built a spam fighting engine that was responsible for taking down 6.6B Third-party datasets enrich the customer profile.
billion in 2019 to $230.80 Data Science is an interdisciplinary field that consists of numerous scientific methods, tools, algorithms, and Machine Learning approaches that attempt to identify patterns in the provided raw input data and derive practical insights from it. . The market is expected to expand from $37.9 billion by 2026.
An analytics engineer is a modern data team member that is responsible for modeling data to provide clean, accurate datasets so that different users within the company can work with them. One of the core responsibilities of an analytics engineer is to model raw data into clean, tested, and reusable datasets. Data modeling.
Optimize the implementation of the machine learning and deep learning algorithms for tasks like Image Classification , Object Recognition, and reduce processing time. Deep understanding of Data Structures and algorithms. Must be able to draw insightful conclusions from the dataset and present them in an organized manner.
The purpose of data visualization projects is to identify patterns, trends, and anomalies or deviations in large datasets/big data (the main data for visualization projects); that otherwise would have been impossible. The reason is, visualizing complex algorithms is a lot easier to understand than numerical outputs.
We want these items to fit you perfectly, so a different set of algorithms is at work to give you the best size recommendations. These requirements include secure and privacy-respecting access to large datasets, reproducibility, high performance, scalability, documentation, and observability (logging, monitoring, debugging).
Likewise, big companies whose business units are storing large volumes of data from separate systems in different formats, thus creating Big Data silos resulting in large datasets that must be integrated manually and consequently erode corporate Big Data investments, should care about Big Data Fabric. What are the Benefits of Big Data Fabric?
A survey conducted by Gartner revealed in 2019 that 37% of the surveyed companies have started implementing AI in their day-to-day tasks, thus signifying a 270% increase in the last four years (w.r.t. If a machine learning algorithm falsely predicts a negative outcome as positive, then the result is labeled as a false negative.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content