This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This blog is your complete guide to building Generative AI applications in Python. AI even de-aged actors in The Irishman (2019) using one of the popular generative models- Generative Adversarial Networks (GANs). The real question is: how do you build your own GenAI applications and tap into this power? Let’s get started!
Have you ever considered the challenges data professionals face when building complex AI applications and managing large-scale data interactions? Without the right tools and frameworks, developers often struggle with inefficient data validation, scalability issues, and managing complex workflows.
Building Artificial Intelligence projects not only improves your skillset as an AI engineer/ data scientist, but it also is a great way to display your artificial intelligence skills to prospective employers to land your dream future job. Project Idea: You can use the Resume Dataset available on Kaggle to build this model.
from 2014-2019. “Customers building their outward facing Web and mobile applications on public clouds while trying to build Hadoop applications on-premises should evaluate vendors offering it as-a-service. Data scientists should be able to run Hadoop jobs through Pig, Hive , Mahout and other data science programming tools.
Read on to find out what occupancy prediction is, why it’s so important for the hospitality industry, and what we learned from our experience building an occupancy rate prediction module for Key Data Dashboard — a US-based business intelligence company that provides performance data insights for small and medium-sized vacation rentals.
Building Python 3.10 Step 1: To ensure that the system is updated and the necessary packages are installed, open a terminal window and type the following commands: sudo apt update Step 2: Install the required dependencies to build Python 3.10 build process as below. system, download Python 3.10 with the single command below.
Windows Server 2019Data Centre, server 2019 standard, server 2016 standard, server 2016 datacenter. Data Source Connectivity Power BI requirements support a large range of data sources, which can be connected to an app to build a dataflow to aggregate, analyze, and visualize data. GHz or faster.
I’m going to refer to this role as the Data Science Engineer to differentiate from its current state. Datapreparation is a fundamental part of data science and heavily tied into the overall function. Some of them will work, some of them won’t but we should always be challenging and trying to improve.
In 2019, Facebook built a spam fighting engine that was responsible for taking down 6.6B Big tech companies have been able to bridge the gap between user demand and application capabilities because they have the time, money and resources to build and maintain on-premise data architectures.
This blog shows how text data representations can be used to build a classifier to predict a developer’s deep learning framework of choice based on the code that they wrote, via examples of TensorFlow and PyTorch projects.
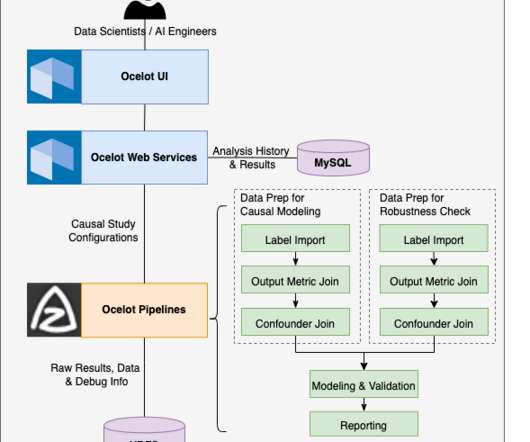
.�� The second component is the Ocelot pipelines, which are fully integrated data pipelines consisting of Java jobs, Spark jobs, and R jobs running on Azkaban (a LinkedIn open-source workflow manager), which both prepare modeling data according to the user configuration and executes causal modeling code.
Namely, AutoML takes care of routine operations within datapreparation, feature extraction, model optimization during the training process, and model selection. In the meantime, we’ll focus on AutoML which drives a considerable part of the MLOps cycle, from datapreparation to model validation and getting it ready for deployment.
Ritual started in 2016 with a single reimagined multivitamin for women and has since launched products for different stages of her life and seen tremendous growth, crossing the threshold of over 1M multivitamin bottle sales in 2019. Ritual’s data stack for serving personalized cart recommendations, email campaigns and banner ads.
Construction projects are hives of constant activity, sustained by steady incoming streams of building materials. Yet for every physical delivery made, many more exchanges of data occur in the background in order to seamlessly orchestrate supply chain operations.
Read this blog till the end to learn more about the roles and responsibilities, necessary skillsets, average salaries, and various important certifications that will help you build a successful career as an Azure Data Engineer. The big data industry is flourishing, particularly in light of the pandemic's rapid digitalization.
Data generated from various sources including sensors, log files and social media, you name it, can be utilized both independently and as a supplement to existing transactional data many organizations already have at hand. Talend is considered one of the most effective and easy-to-use data integration tools focusing on Big Data.
theme of the ML Platform meetup hosted at Netflix, Los Gatos on Sep 12, 2019. Finally, Elliot ended by talking about some of the challenges in building this Bandit framework. He also talked about common pitfalls of stream-processed data like out of order processing.
To build an effective learning model, it is must to understand the quality issues exist in data & how to detect and deal with it. In general, data quality issues are categories in four major sets.
from 2014-2019. “Customers building their outward facing Web and mobile applications on public clouds while trying to build Hadoop applications on-premises should evaluate vendors offering it as-a-service. Data scientists should be able to run Hadoop jobs through Pig, Hive , Mahout and other data science programming tools.
Read this blog till the end to learn more about the roles and responsibilities, necessary skillsets, average salaries, and various important certifications that will help you build a successful career as an Azure Data Engineer. The big data industry is flourishing, particularly in light of the pandemic's rapid digitalization.
Predictive modeling projects require historical data to identify patterns and trends. Predictions are essential for businesses today because they can find better ways to serve the market, build better products, and reduce operational costs. . Many data warehouses are not directly connected to systems that store user data.
billion in 2019, which is a high growth rate. Thus, it clearly shows that the industries will experience a rise in demand for data analysts, data scientists, and data engineers with decent ETL knowledge. Explain the data cleaning process. Mapplet: It organizes or builds transformation sets. to reach $22.3
theme of the ML Platform meetup hosted at Netflix, Los Gatos on Sep 12, 2019. Finally, Elliot ended by talking about some of the challenges in building this Bandit framework. He also talked about common pitfalls of stream-processed data like out of order processing.
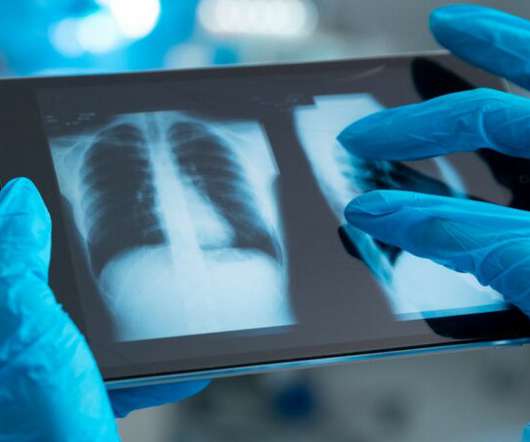
In this article, we’ll share key take-aways from our recent experience in building a prototype of a decision support tool that performs three tasks: lung segmentation, pneumothorax detection and localization, and. Otherwise, let’s proceed to the first and most fundamental step in building AI-fueled computer vision tools — datapreparation.
The “transaction-id” column in the events data file has a value only if a transaction is made by the user else it will be N/A. Download Freiburg Groceries Dataset Computer Vision Project Ideas using Freiburg Groceries Dataset You can build a computer vision model based on multi-class object classification for grocery products.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content