This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. It involves building pipelines that can fetch data from the source, transform it into a usable form, and analyze variables present in the data. What is Data Engineering?
From 2015 to 2019, AI service adoption surged by 270% , showcasing how quickly organisations leverage AI to improve operations and customer engagement. Project Idea: To build a customer support chatbot in Python , you can leverage LangChain and LangGraph. Source Code: How to Build an LLM-Powered Data Analysis Agent?
This blog is your complete guide to building Generative AI applications in Python. AI even de-aged actors in The Irishman (2019) using one of the popular generative models- Generative Adversarial Networks (GANs). The real question is: how do you build your own GenAI applications and tap into this power? Let’s get started!
This created an opportunity to build job sites which collect this data, make it easy to browse, and allow job seekers to apply to jobs paying at or above a certain level. He shared: “I'd preface everything by saying that this is very much a v1 of our jobs product and we plan to iterate and build a lot more as we get feedback.
Building Artificial Intelligence projects not only improves your skillset as an AI engineer/ data scientist, but it also is a great way to display your artificial intelligence skills to prospective employers to land your dream future job. Project Idea: You can use the Resume Dataset available on Kaggle to build this model.
Worried about building a great data engineer resume ? We also have a few tips and guidelines for beginner-level and senior data engineers on how they can build an impressive resume. We have seven expert tips for building the ideal data engineer resume. 180 zettabytes- the amount of data we will likely generate by 2025!
These insights have shaped the design of our foundation model, enabling a transition from maintaining numerous small, specialized models to building a scalable, efficient system. It enables large-scale semi-supervised learning using unlabeled data while also equipping the model with a surprisingly deep understanding of world knowledge.
Have you ever considered the challenges data professionals face when building complex AI applications and managing large-scale data interactions? These obstacles usually slow development, increase the likelihood of errors and make it challenging to build robust, production-grade AI applications that adapt to evolving business requirements.
Similarly, companies with vast reserves of datasets and planning to leverage them must figure out how they will retrieve that data from the reserves. Additionally, the website reported that the number of job positions was almost similar in 2019 and 2020. Imagine you are planning to start a small convenience store.
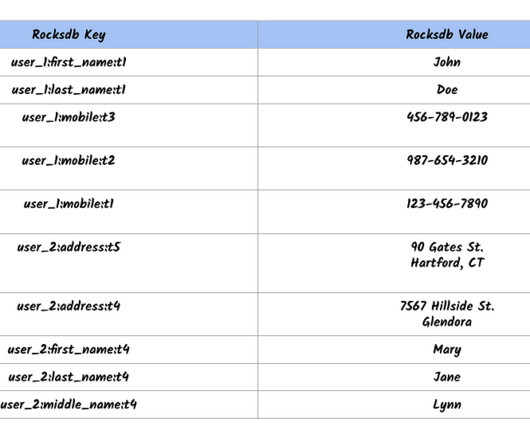
In order to build a distributed and replicated service using RocksDB, we built a real time replicator library: Rocksplicator. Motivation As explained in this blog post , in 2019, Pinterest had four different key-value services with different storage engines including RocksDB, HBase, and HDFS. Individual rows constitute a dataset.
Transfer Learning Examples Keras Transfer Learning Implementation in Python Build exciting Deep Learning Systems with ProjectPro! In traditional machine learning, models are trained from scratch on specific datasets, requiring large amounts of labeled data and computational resources. FAQs What is Transfer Learning in Deep Learning?
In fact, as per a report by Dice Insights in 2019, companies are hungry for data engineers as the job role ranked at the top of the list of trending jobs. Build, Design, and maintain data architectures using a systematic approach that satisfies business needs. In 2021, LinkedIn named it one of the jobs on the rise in the United States.
we suggest you keep in mind this helpful tip on building computer vision project by Timpthy Goebel. Well, you can build your Similar Image Finder too. Thus, building a system that can automatically detect who is not wearing a mask is the need of the hour. It is possible to build such a system with deep learning models.
This project, although simple, is intended entirely towards understanding the various features available and configurable using the matplotlib library for a simple scatter plot, which is generally used to observe the relations between two attributes in the dataset. NOTE: The plots generated here are, however, Matplotlib objects.
Also, remove all missing and NaN values from the dataset, as incomplete data is unnecessary. You can use the Huge Stock Market Dataset or the NY Stock Exchange Dataset to implement this machine learning for finance project. To start this machine learning project , download the Credit Risk Dataset. Our data is imbalanced.
This insight led us to build Edgar: a distributed tracing infrastructure and user experience. Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs. The following sections describe our journey in building these components.
Skills Required to Become a Deep Learning Engineer Deep Learning Engineer Toolkit Becoming a Deep Learning Engineer - Next Steps Deep Learning Engineer Jobs Growth Deep learning is the driving force of artificial intelligence that is helping us build applications with high accuracy levels.
FAQs on Data Mining Projects 15 Top Data Mining Projects Ideas Data Mining involves understanding the given dataset thoroughly and concluding insightful inferences from it. Often, beginners in Data Science directly jump to learning how to apply machine learning algorithms to a dataset.
2019: Users can view their activity off Meta-technologies and clear their history. Current design Finally, we considered whether it would be possible to build a system that relies on amortizing the cost of expensive full table scans by batching individual users requests into a single scan. feature on Facebook.
This blog explores the various aspects of building a Hadoop-based BI solution and offers a few Hadoop-BI project ideas for practice. Business intelligence OLAP is a powerful technology used in BI to perform complex analyses of large datasets. Hadoop-based BI solutions can be scaled up or down to handle large and complex datasets.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These formats are transforming how organizations manage large datasets. 2019 - Delta Lake Databricks released Delta Lake as an open-source project. Why are They Essential?
Online fraud cases using credit and debit cards saw a historic upsurge of 225 percent during the COVID-19 pandemic in 2020 as compared to 2019. As per the NCRB report, the tally of credit and debit card fraud stood at 1194 in 2020 compared to 367 in 2019. lakh crore being syphoned off.
Superset shines in the following areas: Customizability: Superset offers flexibility for customization and extension, enabling organizations to build their modern data stacks. Analysts can also write ad-hoc queries, aggregate and manipulate data, and join multiple tables to create virtual datasets. This isnt a new phenomenon. .
from 2019 to 2027, rising to $19.20 Additionally, it offers custom dashboards that give users a 360-degree view of all actions, reports, and datasets. Excel offers only a few built-in charts, and building dashboards requires working exclusively with those charts. It is not the best tool for massive datasets, though.
For more details on how to build a UD(A)F function, please refer to How to Build a UDF and/or UDAF in KSQL 5.0 The following part of this blog post focuses on pushing the dataset into Google BigQuery and visual analysis in Google Data Studio. wwc : defines the BigQuery dataset name. setContent(text).setType(Type.PLAIN_TEXT).build();
The bureau’s report also suggests that we are likely to witness an increase in the jobs of management analysts by 11% between 2019 and 2029. Additionally, you will learn how to implement Apriori and Fpgrowth algorithms over the given dataset. The rate is pretty higher than the average for other occupations.
Comparing the performance of ORC and Parquet on spatial joins across 2 Billion rows on an old Nvidia GeForce GTX 1060 GPU on a local machine Photo by Clay Banks on Unsplash Over the past few weeks I have been digging a bit deeper into the advances that GPU data processing libraries have made since I last focused on it in 2019.
Between 2019-02-01 and 2019-05-01, find the customer with the highest overall order cost. Also, assume that each first name in the dataset is distinct. Common Table Expressions (CTEs) are expressions used to build temporary output tables from which data can be obtained and used. What is meant by cte in SQL Server?
They created a system to spread data across several servers with GPU-based processing so large datasets could be managed more effectively across the board. . LG Uplus , a South Korean telecommunications service provider, had just launched the world’s first 5G service in April 2019 but was struggling to commercialize it.
This guide has a list of common SQL interview questions and answers to help beginners prepare for SQL interviews with clear questions, simple answers, and easy-to-follow examples that build your confidence and understanding. Between 2019-02-01 and 2019-05-01, find the customer with the highest overall order cost. What is RDBMS?
The ai and machine learning job opportunities have grown by 32% since 2019, according to Linkedin’s ‘ Jobs on the Rise ’ list in 2021. The ML engineer would be responsible for working on various Amazon projects , such as building a product recommendation system or, a retail price optimization system.
But, these two functions directly compete for the available compute resources, creating a fundamental limitation that makes it difficult to build efficient, reliable real-time applications at scale. OLTP databases aren’t built to ingest massive volumes of data streams and perform stream processing on incoming datasets. Michael Carey.
According to the marketanalysis.com report forecast, the global Apache Spark market will grow at a CAGR of 67% between 2019 and 2022. billion (2019 – 2022). Dynamic nature: Spark offers over 80 high-level operators that make it easy to build parallel apps. count(): Return the number of elements in the dataset.
Practical use cases for speech & music activity Audio dataset preparation Speech & music activity is an important preprocessing step to prepare corpora for training. Nevertheless, noisy labels allow us to increase the scale of the dataset with minimal manual efforts and potentially generalize better across different types of content.
DBT (Data Build Tool) — A command-line tool that enables data analysts and engineers to transform data in their warehouse more effectively. Prefect Technologies — Open-source data engineering platform that builds, tests, and runs data workflows. Soda doesn’t just monitor datasets and send meaningful alerts to the relevant teams.
Building a real-time, contextual and trustworthy knowledge base for AI applications revolves around RAG pipelines. What are the challenges building RAG pipelines? When you are building applications for consistent, real-time performance at scale you will want to use a streaming-first architecture.
Having that designation means you can build end-to-end machine learning solutions , which is a highly marketable skill set considering the fact that it has been the fastest-growing job title in the world since 2019. Build a strong portfolio of industry-level ML projects. 2025 Update) 2) What is a machine learning engineer?
If Kafka is persisting your log of messages over time, just like with any other event streaming application, you can reconstitute datasets when needed. Here, we have three sample records moving over the “friends” topic in Kafka.
Encoder-Decoder Structure The encoder-decoder structure is one of the building blocks used in sequence-to-sequence tasks, such as language translation. The pre-trained model is fine-tuned using a smaller labeled dataset on a specific task. How Does The Transformer Model Differ from Traditional NLP Models?
The RMSNorm normalizing function, introduced by Zhang and Sennrich in 2019, is used for this purpose. LLaMA vs Alpaca: Training Data The LLaMA model has been trained on a mixture of datasets that span various domains and contains about 1.4T The datasets used are publicly available and compatible with open sourcing.
That compares to only 36 percent of customer interactions as of December 2019, which was before the pandemic impacted business, and only 20 percent in May 2018. It may not replace previous datasets, but alternative data offers another perspective to round out the historical information about an individual customer or business. .
Read on to find out what occupancy prediction is, why it’s so important for the hospitality industry, and what we learned from our experience building an occupancy rate prediction module for Key Data Dashboard — a US-based business intelligence company that provides performance data insights for small and medium-sized vacation rentals.
This book's publisher is "No Starch Press," and the second edition was released on November 12, 2019. The first edition was launched on February 25, 2015, and the second edition was issued on May 3, 2019. Explains how to build, tweak, and reliably deploy web apps online. Readers gave this book a rating of 4.36
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content