This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
He’s solved interesting engineering challenges along the way, too – like building observability for Amazon’s EC2 offering, and being one of the first engineers on Uber’s observability platform. I wrote code for drivers on Windows, and started to put a basic observability system in place.
Traditional relational database systems are ubiquitous in software systems. The database system guarantees that multiple concurrent transactions will appear to the user to be executed one after the other. Upholding each property in a system based on Kafka is tricky but not impossible, as you are about to find out.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. 2019 - Delta Lake Databricks released Delta Lake as an open-source project.
Fall 2019 By Tom Richards , Carenina Garcia Motion , and Leslie Posada Hack Day at Netflix is an opportunity to build and show off a feature, tool, or quirky app. November 2019 was originally published in Netflix TechBlog on Medium, where people are continuing the conversation by highlighting and responding to this story.
Leveraging machine learning and deep learning , these agents can process data, interact with systems, and adapt to changing conditions, thus enabling sophisticated automation and problem-solving capabilities. The rapid shift toward automation and intelligent systems is becoming impossible to ignore.
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. He then worked at the casual games company Zynga, building their in-game advertising platform.
A first, smaller wave of these stories included Magic.dev raising $100M in funding from Nat Friedman (CEO of GitHub from 2018-2021,) and Daniel Gross (cofounder of search engine Cue which Apple acquired in 2013,) to build a “superhuman software engineer.” AI dev tool startups need outlandish claims to grab attention.
Datadog is a leading observability tooling provider which went public in 2019, with a current market cap of $28B. A very popular open-source solution for systems and services monitoring. A fast and open-source column-oriented database management system, which is a popular choice for log management. But why is this?
Data Engineering refers to creating practical designs for systems that can extract, keep, and inspect data at a large scale. It involves building pipelines that can fetch data from the source, transform it into a usable form, and analyze variables present in the data. Ability to demonstrate expertise in database management systems.
This blog is your complete guide to building Generative AI applications in Python. AI even de-aged actors in The Irishman (2019) using one of the popular generative models- Generative Adversarial Networks (GANs). The real question is: how do you build your own GenAI applications and tap into this power? Let’s get started!
This is the most significant milestone yet for this project, which began in earnest after Mark Zuckerberg outlined his vision for it in 2019. Neither WhatsApp nor Secret Conversations operated in this manner, and we didn’t want all users to have to rely on a device-side storage system.
She recounted a number of lessons Confluent has learned in building Confluent Cloud, and announced the availability of several new features in the cloud service. ?. We rightly spend a lot of time trying to figure out how to build things, so it was good to step back and see how our engineering work can drive internal cultural change as well.
4:45pm-5:45pm NFX 202 A day in the life of a Netflix Engineer Dave Hahn , SRE Engineering Manager Abstract : Netflix is a large, ever-changing ecosystem serving millions of customers across the globe through cloud-based systems and a globally distributed CDN. In 2019, Netflix moved thousands of container hosts to bare metal.
Have you ever considered the challenges data professionals face when building complex AI applications and managing large-scale data interactions? These obstacles usually slow development, increase the likelihood of errors and make it challenging to build robust, production-grade AI applications that adapt to evolving business requirements.
This created an opportunity to build job sites which collect this data, make it easy to browse, and allow job seekers to apply to jobs paying at or above a certain level. For AI, we’ve built a system to efficiently use GPT-4 for this purpose, including auto-crafting prompts and performing pre and post-processing.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
This blog post focuses on the scope and the goals of the recommendation system, and explores some of the most recent changes the Rider team has made to better serve Lyft’s riders. Introduction: Scope of the Recommendation System The recommendation system covers user experiences throughout the ride journey.
To build the kinds of systems we are being called upon to build these days, we need infrastructure that gives equal priority to events and state together. and a couple of fantastic keynotes: Jay Kreps (CEO of Confluent and co-creator of Apache Kafka ® ) kept the unifying vision of the event streaming platform in front of us.
If you looked at the Kafka Summits I’ve been a part of as a sequence of immutable events (and they are, unless you know something about time I don’t), it would look like this: New York City 2017, San Francisco 2017, London 2018, San Francisco 2018, New York City 2019, London 2019, San Francisco 2019. Yes, you read that right.
Launched in 2019, this strategy aims to position the US as a leader in AI research, development, and deployment. It focuses on five key pillars: investing in research and development; unleashing government AI resources; setting standards and policy; building the AI workforce; and advancing trust and security. million), among others.
Worried about building a great data engineer resume ? We also have a few tips and guidelines for beginner-level and senior data engineers on how they can build an impressive resume. Data engineering entails creating and developing data collection, storage, and analysis systems. Don’t worry!
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. 2019: Users can view their activity off Meta-technologies and clear their history. feature on Facebook. What are data logs?
A first, smaller wave of these stories included Magic.dev raising $100M in funding from Nat Friedman (CEO of GitHub from 2018-2021,) and Daniel Gross (cofounder of search engine Cue which Apple acquired in 2013,) to build a “superhuman software engineer.” AI dev tool startups need outlandish claims to grab attention.
Based on the votes of Summit attendees from within the Kafka Summit mobile app, here are the top-rated talks: Building Stream Processing Applications with Apache Kafka Using KSQL by Robin Moffatt of Confluent. With so many sessions to choose from, perhaps you’re wondering where to start. Why Stop the World When You Can Change It?
As with any system out there, the data often needs processing before it can be used. In traditional data warehousing, we’d call this ETL, and whilst more “modern” systems might not recognise this term, it’s what most of us end up doing whether we call it pipelines or wrangling or engineering. Handling time.
which is difficult when troubleshooting distributed systems. This insight led us to build Edgar: a distributed tracing infrastructure and user experience. Troubleshooting a session in Edgar When we started building Edgar four years ago, there were very few open-source distributed tracing systems that satisfied our needs.
I even stopped by Build-A-Bear at lunchtime with the inaugural class of Confluent Community Catalysts ! He is the co-presenter of various O’Reilly training videos on topics ranging from Git to distributed systems, and is the author of Gradle Beyond the Basics. And, I saw fresh Kafka swag in the making. and all over the world.
Additionally, the website reported that the number of job positions was almost similar in 2019 and 2020. Build and deploy ETL/ELT data pipelines that can begin with data ingestion and complete various data-related tasks. Build solutions highlighting data quality, operational efficiency, and other feature describing data.
Zhamak Dehghani introduced the concepts behind this architectural patterns in 2019, and since then it has been gaining popularity with many companies adopting some version of it in their systems. How has your view of the principles of the data mesh changed since our conversation in July of 2019?
While the process of building simple, domain-specific chatbots has gotten way easier, building large scale, multi-agent conversational applications remains a massive challenge.
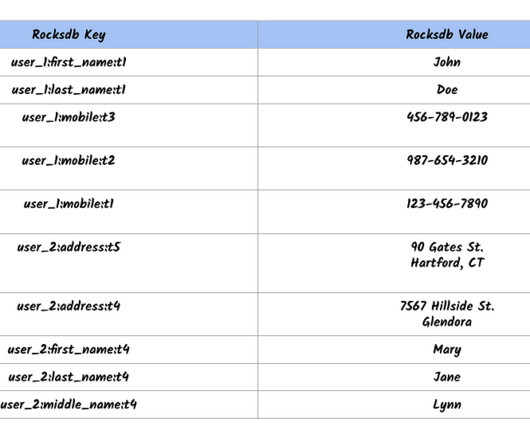
In 2020, anticipating the growing needs of the business and to simplify our storage offerings, we decided to consolidate our different key-value systems in the company into a single unified service called KVStore. In order to build a distributed and replicated service using RocksDB, we built a real time replicator library: Rocksplicator.
In fact, as per a report by Dice Insights in 2019, companies are hungry for data engineers as the job role ranked at the top of the list of trending jobs. Data engineers are responsible for creating pipelines enabling data flow from various sources to data storage and processing systems.
Building Artificial Intelligence projects not only improves your skillset as an AI engineer/ data scientist, but it also is a great way to display your artificial intelligence skills to prospective employers to land your dream future job. Project Idea: You can use the Resume Dataset available on Kaggle to build this model.
DataOps DevOps Databases, data warehouses, schemas, tables, views, and integration logs from other important systems make up the DataOps ecosystem. The building of CI/CD pipelines, the discussion about code automation, and ongoing uptime and availability improvements all take place here.
This guide has a list of common SQL interview questions and answers to help beginners prepare for SQL interviews with clear questions, simple answers, and easy-to-follow examples that build your confidence and understanding. RDBMS stands for Relational Database Management System. What is RDBMS? List a few examples. Provide examples.
Transfer Learning Examples Keras Transfer Learning Implementation in Python Build exciting Deep Learning Systems with ProjectPro! Check Out ProjectPro's Deep Learning Course to Gain Practical Skills in Building and Training Neural Networks! Why use Transfer Learning? When to use Transfer Learning?
In 2019, Alibaba bought Ververica. This comparison seems like a clear point that Flink will be the system of choice. Streaming systems are already difficult enough and adding more complexity to the choice with lead to analysis paralysis. That’s because it was recently founded, but that doesn’t mean it wasn’t formidable.
A 2020 retention report by the Work Institute revealed that over 42 million employees in the US left their jobs voluntarily in 2019, and this trend appeared to be increasing. This is especially important for organizations to set and meet diversity, equity and inclusion targets to build well-rounded and successful teams. .
The app makes heavy use of code generation, spurred by Buck , our custom buildsystem. Without heavy caching from our buildsystem, engineers would have to spend an entire workday waiting for the app to build. If News Feed wanted to have a declarative UI, the team would have to build a new UI framework.
COLOR_BGR2RGB) # Display the image with detected faces plt.imshow(face_image_rgb) plt.axis('off') # Hide axes plt.show() Computer Vision Project Idea-3 Face Recognition System This is another computer vision project that deals with human faces. we suggest you keep in mind this helpful tip on building computer vision project by Timpthy Goebel.
Software Engineers, on the other hand, specialize in building and developing comprehensive systems, with an emphasis on architectural and engineering concepts. On the other hand, a Software Engineer focuses on specific areas of development, such as system design, algorithms, or a programming language.
We’re looking for driven engineers to fortify our European operations and solve some of the hardest problems in building large distributed systems to support rideshare, mapping, and more. Lyft was founded in 2012 and went public in 2019, with the mission to improve people’s lives with the world’s best transportation.
Built with Prometheus and InfluxDB monitoring systems. To build an event streaming pipeline, Spring Cloud Data Flow provides a set of application types: A source represents the first step in the data pipeline, a producer that extracts data from the external systems like databases, filesystem, FTP servers, IoT devices, etc.
An authoritarian regime is manipulating an artificial intelligence (AI) system to spy on technology users. When developing ethical AI systems, the most important part is intent and diligence in evaluating models on an ongoing basis,” said Santiago Giraldo Anduaga, director of product marketing, data engineering and ML at Cloudera.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content