This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As data scientists who are the brains behind the AI-based innovations, you need to understand the significance of datapreparation to achieve the desired level of cognitive capability for your models. Let’s begin.
Windows Server 2019Data Centre, server 2019 standard, server 2016 standard, server 2016 datacenter. Self-service tools for big data: dataflows are used to ingest, cleanse, transform, integrate, and visualize data from various observation sources. Below are the Power BI requirements for the system.
The Data Science Engineer Let’s start with the original idea of the Data Engineer, the support of Data Science functions by providing clean data in a reliable, consistent manner, likely using big data technologies. I’m going to refer to this role as the Data Science Engineer to differentiate from its current state.
default, Mar 27 2019, 22:11:17) >>> print("Hello, World") Hello, World >>> quit() (venv) (base) amit@amit:~$ By using the command deactivate , you can exit the environment and go back to your default directory. To do this, we will open the Python terminal in a virtual environment by writing Python.
In 2019, Facebook built a spam fighting engine that was responsible for taking down 6.6B Big tech companies have been able to bridge the gap between user demand and application capabilities because they have the time, money and resources to build and maintain on-premise data architectures.
The traditional Data Warehouse ETL process has splintered into many smaller components. Ingest is now focused data capture and real-time trend analysis where possible. Once data is brought under control in a system like Cloudera, then the work of DataPreparation, Quality begins. Visit us at Informatica World 2019.
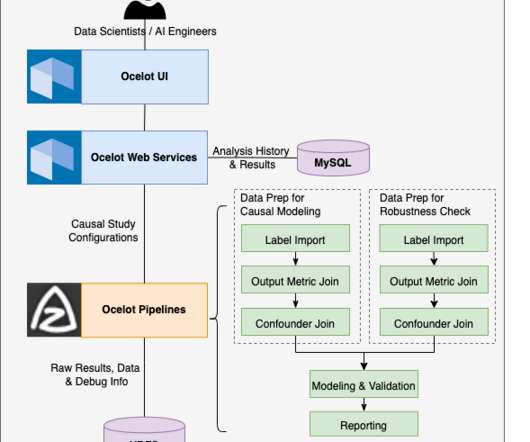
.�� The second component is the Ocelot pipelines, which are fully integrated data pipelines consisting of Java jobs, Spark jobs, and R jobs running on Azkaban (a LinkedIn open-source workflow manager), which both prepare modeling data according to the user configuration and executes causal modeling code.
Increase your confidence to perform data cleaning with a broader perspective of what datasets typically look like, and follow this toolbox of code snipets to make your data cleaning process faster and more efficient.
First of all, this is an increase of around 5 percent over the summer of 2019: It’s already an indicator that things are going pretty well. A lot of quality data, to be even more exact. To learn the basics, you can read our dedicated article on how data is prepared for machine learning or watch a short video.
Namely, AutoML takes care of routine operations within datapreparation, feature extraction, model optimization during the training process, and model selection. In the meantime, we’ll focus on AutoML which drives a considerable part of the MLOps cycle, from datapreparation to model validation and getting it ready for deployment.
Talend is an open-source data integration and data management platform that empowers users with facilitated, self-service datapreparation. Talend is considered one of the most effective and easy-to-use data integration tools focusing on Big Data. That’s a lot of data to learn from.
Ritual started in 2016 with a single reimagined multivitamin for women and has since launched products for different stages of her life and seen tremendous growth, crossing the threshold of over 1M multivitamin bottle sales in 2019. The team at Ritual started a free trial of Rockset and was impressed at the ease of use.
With a mission to digitize every aspect of construction materials logistics, the company launched CONNEX in 2019 to provide a SaaS application where suppliers, transportation providers and contractors on jobsites can collaborate on all the data collected by Command Alkon’s systems.
theme of the ML Platform meetup hosted at Netflix, Los Gatos on Sep 12, 2019. Their offline datapreparation ETLs run on Spark and they use Airflow as the orchestration layer. Faisal Siddiqi Infrastructure for Contextual Bandits and Reinforcement Learning?—? they need to prevent malicious content from impacting the service.
Data Engineer Career: Overview Currently, with the enormous growth in the volume, variety, and veracity of data generated and the will of large firms to store and analyze their data, data management is a critical aspect of data science. That’s where data engineers are on the go.
While Pandas is the library for data processing in Python, it isn't really built for speed. Learn more about the new library, Modin, developed to distribute Pandas' computation to speedup your data prep.
This post will walkthrough a Python implementation of a vocabulary class for storing processed text data and related metadata in a manner useful for subsequently performing NLP tasks.
From not sweating missing values, to determining feature importance for any estimator, to support for stacking, and a new plotting API, here are 5 new features of the latest release of Scikit-learn which deserve your attention.
In October 2019, Microsoft reported artificial intelligence helped manufacturing companies outperform rivals stating that manufacturers adopting AI perform 12 percent better than their competitors.Therefore, we are likely to see the outburst of AI-based technologies in manufacturing along with the advent of new highly-paid workplaces in this area.
In this tutorial, we show how to apply mathematical set operations (union, intersection, and difference) to Pandas DataFrames with the goal of easing the task of comparing the rows of two datasets.
This blog shows how text data representations can be used to build a classifier to predict a developer’s deep learning framework of choice based on the code that they wrote, via examples of TensorFlow and PyTorch projects.
Predictive Analytics is expected to generate more than six billion dollars in revenue by 2019. Many data warehouses are not directly connected to systems that store user data. A data science team may not be able to share data freely with some lines of business because they feel that their data belongs to them. .
from 2014-2019. A data scientist spends most of the time in datapreparation so a HDaaS solution should offer a rich and powerful environment for analysis. Data scientists should be able to run Hadoop jobs through Pig, Hive , Mahout and other data science programming tools.
Let’s say your project is humongous and needs data labeling to be done continuously - while you’re on-the-go, sleeping, or eating. I’m sure you’d appreciate User-generated Data Labeling. I’ve got 6 interesting examples to help you understand this, let’s dive right in!
theme of the ML Platform meetup hosted at Netflix, Los Gatos on Sep 12, 2019. Their offline datapreparation ETLs run on Spark and they use Airflow as the orchestration layer. Faisal Siddiqi Infrastructure for Contextual Bandits and Reinforcement Learning?—? they need to prevent malicious content from impacting the service.
The pandas library offers core functionality when preparing your data using Python. But, many don't go beyond the basics, so learn about these lesser-known advanced methods that will make handling your data easier and cleaner.
Data engineers will be in high demand as long as there is data to process. According to Dice Insights, data engineering was the top trending career in the technology industry in 2019, beating out computer scientists, web designers, and database architects. This real-world data engineering project has three steps.
Your spectacularly-performing machine learning model could be subject to the common culprits of class imbalance and missing labels. Learn how to handle these challenges with techniques that remain open areas of new research for addressing real-world machine learning problems.
To build an effective learning model, it is must to understand the quality issues exist in data & how to detect and deal with it. In general, data quality issues are categories in four major sets.
AI-based models are highly dependent on accurate, clean, well-labeled, and prepareddata in order to produce the desired output and cognition. These models are fed with bulky datasets covering an array of probabilities and computations to make its functioning as smart and gifted as human intelligence.
Learn the essential skills needed to become a Data Science rockstar; Understand CNNs with Python + Tensorflow + Keras tutorial; Discover the best podcasts about AI, Analytics, Data Science; and find out where you can get the best Certificates in the field.
Otherwise, let’s proceed to the first and most fundamental step in building AI-fueled computer vision tools — datapreparation. Computer vision requires plenty of quality data, diverse in gender, race, and geography. The next large step in datapreparation for computer vision is image labeling or annotation.
Download OSIC Pulmonary Fibrosis Progression Dataset Data Science/Machine Learning Project Idea using OSIC Kaggle Dataset You can build a machine learning model to predict a patient’s severity of the decline in lung function. Each image is clinically rated on a scale of 0 to 4 based on the severity of diabetic retinopathy.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content