This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
New in 2021. Figure 2 – CDE product launch highlights in 2021. As data teams grow, RAZ integration with CDE will play an even more critical role in helping share and control curated datasets. Early on in 2021 we expanded our APIs to support pipelines using a new job type — Airflow. Modernizing pipelines.
Download the 2021 DataOps Vendor Landscape here. DataOps is a hot topic in 2021. Soda doesn’t just monitor datasets and send meaningful alerts to the relevant teams. The post The DataOps Vendor Landscape, 2021 first appeared on DataKitchen. Soda Data Monitoring — Soda tells you which data is worth fixing.
What (if any) are the datasets or analyses that you are consciously not investing in supporting? The company was founded in 2021 by Kirk Marple after his tenure as CTO of Kespry. What (if any) are the datasets or analyses that you are consciously not investing in supporting?
In this blog post, we will ingest a real world dataset into Ozone, create a Hive table on top of it and analyze the data to study the correlation between new vaccinations and new cases per country using a Spark ML Jupyter notebook in CML. On creation of the bucket, we also upload a COVID dataset [1] that is a CSV with about 100K rows.
Given the way we have seen communities and workplace cultures come together and stand for change over what has been a disruptive 20 months, we are proud to introduce the People First category to the 2021 DIA. So, without further ado, it is with great delight that we officially publish the 2021 Data Impact Award winners!
With a lot of excitement and research around NLP, there are growing opportunities to apply these technologies to real-world scenarios. It's not trivial to become familiar with NLP and these open-source data sets can help you increase your skills.
After one particularly tough week in the winter of 2021, when marketing data was disrupted by daily incidents and downtime, a group of data engineers decided to create a full diagram of the data systems. The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months.
After one particularly tough week in the winter of 2021, when marketing data was disrupted by daily incidents and downtime, a group of data engineers decided to create a full diagram of the data systems. The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months.
The 2021 Data Impact Awards aim to honor organizations who have shown exemplary work in this area. . In 2021, the finalists under this category include the following organizations. Winner of the Data Impact Awards 2021: Data for Enterprise AI. …and congratulations to the winner: Internal Revenue Service.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These formats are transforming how organizations manage large datasets. Though basic and easy to use, traditional table storage formats struggle to keep up. Why are They Essential?
But it is incredibly hard to determine whether a dataset is ethical, unbiased, and not skewed manually. But what if we need to query the same dataset multiple times? Conferences SmartData 2021 – This international conference on data engineering is organized by a Russian company, but it aims to have at least 30% of the talks in English.
15 NLP Projects Ideas for Beginners With Source Code for 2021 How to Become a Big Data Engineer in 2021 Big Data Engineer Salary - How Much Can You Make in 2021? 15 NLP Projects Ideas for Beginners With Source Code for 2021 How to Become a Big Data Engineer in 2021 Big Data Engineer Salary - How Much Can You Make in 2021?
For example, writing a Spark dataset to Ozone or launching a DDL query in Hive that points to a location in Ozone. I’ve chosen those names because I’ll be using an easy method for generating and writing TPC-DS datasets, along with creating their corresponding Hive tables. Create a dataset from the customer table. With CDP 7.1.4
Many real-world datasets consist of records of events that occur at arbitrary and irregular intervals. These datasets then need to be processed into regular time series for further analysis. We will use the AI & Analytics Engine to illustrate how you can prepare your time-series data in just 1 step.
The data architecture layer is one such area where growing datasets have pushed the limits of scalability and performance. The data explosion has to be met with new solutions, that’s why we are excited to introduce the next generation table format for large scale analytic datasets within Cloudera Data Platform (CDP) – Apache Iceberg.
2021: Users can more easily navigate categories of information in Access Your Information 2023: Users can more easily use our tools as access features are consolidated within Accounts Center. 2020: Users continue to receive more information in DYI such as additional information about their interactions on Facebook and Instagram.
These large models are pre-trained on large general-purpose datasets, such as ImageNet, and later fine-tuned for more specialized tasks, including object detection, segmentation, and image classification, making them useful in many real-world applications.
This post runs through just over six months of progress from Sept 2021 - March 2022. Recursive task decomposition September 2021 One of the big constraints of the GPT series of models is the size of the input. Fine-tuning December 2021 Fine-tuning, a topic I covered in my previous blog post , has progressed out of beta.
A lot of missing values in the dataset can affect the quality of prediction in the long run. Several methods can be used to fill the missing values and Datawig is one of the most efficient ones.
This article is a brief summary of our observations on some common client misperceptions with respect to recent developments in NLP, especially the use of large-scale models and datasets.
ROAPI: An API Server for Static Datasets Mark Litwintschik, #bigdata Consultant ROAPI is an API Server that exposes CSV, JSON and Parquet files without the need to write any code. Day In The Life Of A Data Engineer — What Do Data Engineers Do? SeattleDataGuy There’s no better time to jump into the world of data engineering.
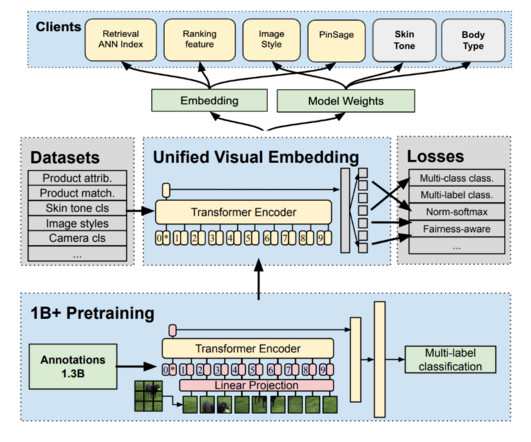
In 2021, we announced hair pattern search. In this case, thousands of fashion Pins¹ publicly available on Pinterest are gathered to serve as the raw dataset. The resulting structured dataset becomes the foundation to train and evaluate the machine learning model known as the body type signal.
2021 to move beyond the traditional dashboards of the past. To show this in action, we will use the airline flights dataset to demonstrate some of the ways you can start incorporating predictive analytics in your visual applications. . For our flights dataset we will use the flight cancellation AMP as our starting point.
Datasets containing attributes of Airbnb listings in 10 European cities ¹ will be used to create the same Pipeline in scikit-learn and MLLib. First, let’s load the datasets. link] Finally, we can fit the pipeline into the training dataset and predict the prices for the test dataset listings just like is done with any other model.
This will only become more important as we move into 2021 and a post-pandemic new normal. It may not replace previous datasets, but alternative data offers another perspective to round out the historical information about an individual customer or business. . This can be done at speed, and at scale. What if 2020 is an anomaly?
But it is incredibly hard to determine whether a dataset is ethical, unbiased, and not skewed manually. But what if we need to query the same dataset multiple times? Conferences SmartData 2021 – This international conference on data engineering is organized by a Russian company, but it aims to have at least 30% of the talks in English.
Standardize Datasets Here’s the first of three things Suvayu recommends to get the trust in trusted data : as data definitions are codified in the business glossary, establish those data objects in your enterprise datasets and evangelize them as the source of truth from which new data assets should be sourced.
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. Table of Contents What is the MNIST dataset? Test the Trained Neural Network Visualizing the Test Results Ending Notes What is the MNIST dataset?
The idea is to show pros and cons of these two types of engines on a concrete dataset. In this article, we are going to compare the sentiment extraction performance between Sentiment Analysis engines and Custom Text classification engines.
In this blog, I’ll showcase how the Pinterest Mobile Builds team is leveraging Honeycomb (starting in 2021) to enhance observability and performance in our mobile builds and continuous integration (CI) workflows. Established Habits: We’ve been using Honeycomb’s trace view since 2021, long before the Waterfall View was introduced.
In 2021, ML was siloed at Pinterest with 10+ different ML frameworks relying on different deep learning frameworks, framework versions, and boilerplate logic to connect with our ML platform. Hardware upgrades usually require months of collaboration with various client teams to get software versions that are lagging behind up-to-date.
It also provides an advanced materialized view engine to enable live aggregated datasets to be accessible by other applications via a simple REST API. Even better, if you want to watch a live demo of this product, attend our webinar on March 30th, 2021 – Liberating real-time data access with the new SQL Stream Builder.
A strategic acquisition and the need for integration In 2021, Magnite made a decisive move to strengthen its position in the CTV advertising market by acquiring SpringServe, a leader in CTV ad-serving technology. Remarkably, the entire dataset with over 1.2 PBs was replicated in just one day.
What sets Bard apart is its ability to draw from up-to-date web information to provide prompt responses, giving it an advantage over ChatGPT, whose data pool is limited to pre-2021. DialoGPT DialoGPT is a large language model developed by OpenAI that was specifically trained for engaging in human-like conversations.
If you want to look back, here are the 2021 and 2022 results) Interested to learn more? If you want to explore the data, feel free to download the dataset , please do attribute if you reproduce or use this data.
CDP allows all data users and decision-makers to access the same enterprise data cloud that gathers every dataset available in their business, no matter where it’s coming from in a safe and compliant manner. We’d love to hear from you so why not submit your entry for the 2021 Data Champion category?
Your project proposal should include a description of your data science project , as well as statistics about the size and complexity of your dataset. Iron Viz is the ultimate Tableau skills competition in which three finalists compete in a 20-minute nail-biting viz fight utilizing the same dataset. Swag from Tableau!
Cloudera has been recognized as a Visionary in 2021 Gartner® Magic Quadrant for Cloud Database Management Systems (DBMS) and for the first time, evaluated CDP Operational Database (COD) against the 12 critical capabilities for Operational Databases. Gartner Magic Quadrant for Cloud DBMS 2021. What Cloudera COD customers are saying .
It was designed and trained using the following three key insights and innovations: 1) Many-but-condensed experts with more expert choices: In late 2021, the DeepSpeed team demonstrated that MoE can be applied to auto-regressive LLMs to significantly improve model quality without increasing compute cost.
Here are some key data points that illustrate how the intelligent use of data and analytics redefines companies in 2021: Data-driven companies know where all their data is located. All of these factors weigh heavily on the success of products and services in the market. In fact, most data-driven cultures are exactly the opposite. In summary.
At Pinterest, to overcome the well-known ID embedding overfitting issue and maximize ROI and flexibility in downstream ML models, we pre-train large-scale user and Pin ID embeddings by contrastive learning on sampled negatives over a cross-surface large window dataset with no positive engagement downsampling [7]. 2] Zhang, Buyun, et al.
Binary Classification Machine Learning This type of classification involves separating the dataset into two categories. Image Source: Wikipedia Commons Multi-Label Classification Machine Learning This is an extraordinary type of classification task with multiple output variables for each instance from the dataset.
You have several relational datasets flowing through your warehouse, and, of course, you can easily access and transform these tables through dbt. You need the history of each entity_id across all of your datasets, because each related table is updated on its own timeline. Here’s an example of a dataset. Let’s set the scene.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content