This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
2025 data engineering trends incoming. Synthetic data works by leveraging models to create artificial datasets that reflect what someone might find organically (in some alternate reality where more data actually exists), and then using that new data to train their own models. Table of Contents 1. Process > Tooling (Barr) 3.
But as we move into 2025, organizations are facing new challenges that are testing their data strategies, artificial intelligence (AI) readiness, and overall trust in data. Read on for the highlights from this panel – including actionable tips to ensure success in your 2025 data, analytics, and AI initiatives.
HNY 2025 ( credits ) Happy new year ✨ I wish you the best for 2025. I hope you will enjoy 2025. Let's jump to the news, and have fun reading, it's a large wrap of everything that happened at the end of the year + how 2025 started. Thank you so much for your support through the years. This is a must-read.
2025 data engineering trends incoming. Synthetic data works by leveraging models to create artificial datasets that reflect what someone might find organically (in some alternate reality where more data actually exists), and then using that new data to train their own models. But is synthetic data a long-term solution? Probablynot.
As we approach 2025, data teams find themselves at a pivotal juncture. As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. Leveraging cloud-based platforms and distributed computing can help handle large datasets efficiently.
But as we move into 2025, organizations are facing new challenges that are testing their data strategies, artificial intelligence (AI) readiness, and overall trust in data. Read on for the highlights from this panel – including actionable tips to ensure success in your 2025 data, analytics, and AI initiatives.
As we approach 2025, data teams find themselves at a pivotal juncture. As we look towards 2025, it’s clear that data teams must evolve to meet the demands of evolving technology and opportunities. Leveraging cloud-based platforms and distributed computing can help handle large datasets efficiently.
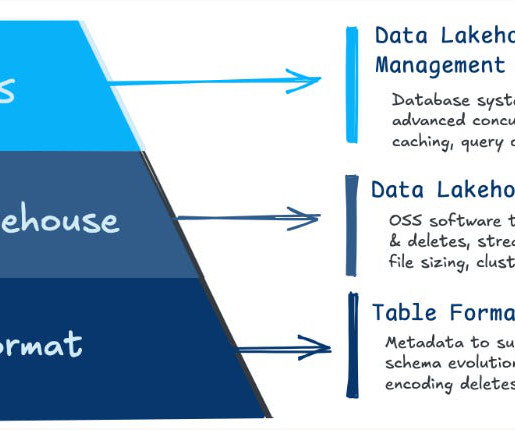
Together, we discussed how Hudi drives innovation, the state of open standards, and what lies ahead for data lakehouses in 2025 and beyond. This hybrid approach empowers enterprises to efficiently handle massive datasets while maintaining flexibility and reducing operational overhead. Exploring Apache Hudi 1.0:
Three Predictions for 2025: The Future of Cybersecurity in the AI Era As AI and machine learning continue to advance, several key trends will shape cybersecurity by 2025. Models: Unified Cybersecurity Infrastructure By 2025, cybersecurity will pivot toward a truly unified model. Is C|EH worth it in 2025? Absolutely.
Great for teams dealing with big, messy datasets. Its super searchable, and it supports data previews and lineage trackingso you can follow your data from where it starts to where it ends up. DataHub Source: DataHub DataHub , originally developed by LinkedIn, is another favorite.
Annual Report: The State of Apache Airflow® 2025 DataOps on Apache Airflow® is powering the future of business – this report reviews responses from 5,000+ data practitioners to reveal how and what’s coming next. Data Council 2025 is set for April 22-24 in Oakland, CA. link] Mehdio: DuckDB goes distributed?
Editor’s Note: Launching Data & Gen-AI courses in 2025 I can’t believe DEW will reach almost its 200th edition soon. We are planning many exciting product lines to trial and launch in 2025. What I started as a fun hobby has become one of the top-rated newsletters in the data engineering industry.
Annual Report: The State of Apache Airflow® 2025 DataOps on Apache Airflow® is powering the future of business – this report reviews responses from 5,000+ data practitioners to reveal how and what’s coming next. Data Council 2025 is set for April 22-24 in Oakland, CA. What we learned?
The historical dataset is over 20M records at the time of writing! ” These are sensible mid-term plans: but they do not answer for what happens to the startup starting 1 January 2025, when their grant funding runs out. This means about 275,000 up-to-date server prices, and around 240,000 benchmark scores.
2025 Outlook: Essential Data Integrity Insights Whats trending in trusted data and AI readiness for 2025? Enriching your address data with unique identifiers and external datasets is key to making better-informed decisions and minimizing these kinds of losses. The results are in!
Save Your Spot → Stanford HAI: AI Index 2025 - State of AI in 10 Charts Stanford gives an insight into AI adoption in the industry with the AI adoption. Despite minor performance trade-offs, Dataset’s benefits significantly enhance correctness, clarity, and long-term maintainability in robust data engineering practices.
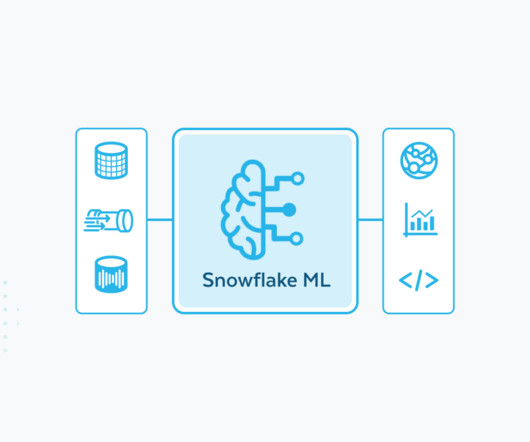
From November 2024 to January 2025, over 4,000 customers used Snowflakes AI capabilities every week. For image data, running distributed PyTorch on Snowflake ML also with standard settings resulted in over 10x faster processing for a 50,000-image dataset when compared to the same managed Spark solution.
For IT operations (ITOps) teams, 2025 means reassessing technology stacks, processes, and people. Examples of datasets include privileged users, access to failures, and customer data. As businesses evolve and delivery speeds increase, IT operations teams face environments where downtime isn’t an option.
Save Your Spot → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. We all bet on 2025 being the year of Agents.
a lea prepare command that creates database objects that needs to be created (dataset, schema, etc.). 25 million Creative Commons image dataset released — Fondant, an open-source processing framework, released publicly available images from web crawling with their associated license. What are the main differences?
The Gartner Data & Analytics Summit 2025 in London is approaching quickly! Why Gartners Data & Analytics Summit 2025 Matters 3. Summit Essentials Date & Location The Gartner Data & AI Summit takes place May 12-15th, 2025 in London, England. The Monte Carlo team will be attending, so be sure to look for us there!
Cloud-Based Solutions: Large datasets may be effectively stored and analysed using cloud platforms. In 2025 , the tale of change is about more than simply technology; it is also about the vision, leadership, and strategy that enable it. Tableau, Power BI, and SAS provide user-friendly interfaces and extensive modelling capabilities.
Demand Forecasting – Companies must move beyond basic demand forecasting using only historical transaction data to leveraging real-time datasets and external consumer demand signals. Companies need to leverage more data and broader datasets, whether that is real-time data, whether that is external data or more specific to geolocations.
While the app itself is cool, we’re seeing some really interesting benefits including reducing regression bugs, building better dev and demo schemas, rebalancing biased datasets, and even scale testing. You can even train ML models on our synthetic data, or use it for data sharing purposes. Why did you choose to build your app on Snowflake?
According to the World Economic Forum, the amount of data generated per day will reach 463 exabytes (1 exabyte = 10 9 gigabytes) globally by the year 2025. These skills are essential to collect, clean, analyze, process and manage large amounts of data to find trends and patterns in the dataset.
At the same time for the gov I've worked on a larger project to develop a private datalake to work datasets with on-demand RStudio and Jupyter containers. Let's more make ideas and stuff I'll be proud about in January 2025 when writing the 2024 post.
With global data creation projected to grow to more than 180 zettabytes by 2025 , it’s not surprising that more organizations than ever are looking to harness their ever-growing datasets to drive more confident business decisions.
According to data from sources like Network World and, G2 the global datasphere is projected to expand from 33 zettabytes in 2018 to an astounding 175 zettabytes by 2025, reflecting a compound annual growth rate (CAGR) of 61%. For example, when processing a large dataset, you can add more EC2 worker nodes to speed up the task.
By 2025, generative AI will be producing 10 percent of all data (now it’s less than 1 percent) with 20 percent of all test data for consumer-facing use cases; By 2025, generative AI will be used by 50 percent of drug discovery and development initiatives; and. is compared to the expected output (y) from the training dataset.
Together, these innovations reflect a growing industry-wide focus on tools and frameworks that process unstructured data more intelligently and cost-effectively, opening new possibilities for analyzing complex, unformatted datasets at unprecedented scales. What is ahead of us in 2025? Stay Tuned.
The International Data Corporation (IDC) estimates that by 2025 the sum of all data in the world will be in the order of 175 Zettabytes (one Zettabyte is 10^21 bytes). It aims to protect AI stakeholders from the effects of biased, compromised or skewed datasets. Quantifications of data. Data scrutiny.
By 2025, 80% of mainstream data quality vendors will expand their product capabilities to provide greater data insights by discovering patterns, trends, data relationships, and error resolution. Problem: “We’re uncertain about compliance with privacy regulations!”
Migration : Prepare for long-term cloud operations, and begin to look at look at migrating your critical datasets, like legacy systems, as you establish a cloud center of excellence. Foundation : Gradually increase your cloud presence, building a scalable and secure base for more extensive projects.
Recently, we announced the launch of Spotter, our AI Analyst, which brings AI-powered insights to every user, on any question, and any dataset. Organizations have unique use cases, datasets, and requirements. This is ThoughtSpot's answer to a growing market of AI agents , and its our vision to make AI the new BI.
Cloudera joined forces with NVIDIA to develop a new capability to accelerate Artificial Intelligence (AI) and Machine Learning (ML) operations on petabyte-scale datasets using GPUs. Failure to address this meant major implications for the IRS and the taxpayer. Industry Transformation.
In 2020, this number grew to 59 ZB and was expected to reach a whopping 175 ZB in 2025. Learn Data Analysis with Python Now that you know how to code in Python start picking toy datasets to perform analysis using Python. In 2018, the world produced 33 Zettabytes (ZB) of data, which is equivalent to 33 trillion Gigabytes (GB).
This solution leverages Scikit-Learn models in ONNX format, allowing efficient, SQL-based batch scoring directly in BigQuery, significantly improving scoring performance on large datasets. link] All rights reserved ProtoGrowth Inc, India. I have provided links for informational purposes and do not suggest endorsement.
This lets them do things like get real-time information or process datasets that are specific to a topic. Some important reasons are: 1. Integration with External Data : LangChain lets LLMs talk to APIs, databases, and other data sources.
A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. They analyze datasets to find trends and patterns and report the results using visualization tools. Data engineers can also create datasets using Python. It can easily integrate with Hadoop and work with large and unstructured datasets.
Most companies have already adopted AI solutions into their workflow, and the global AI market value is projected to reach $190 billion by 2025. The training dataset is ready and made available for you for most of these beginner-level object detection projects. You can use the flowers recognition dataset on Kaggle to build this model.
zettabytes in 2020, and is projected to mushroom to over 180 zettabytes by 2025, according to Statista. Moreover, the concept of ‘online machine learning’ has emerged as a potential solution for organizations working with data that arrives in a continuous stream or when the dataset is too large to fit into memory. It reached 64.2
If you think machine learning methods may not be of use to you, we reckon you reconsider that because, in May 2021, Gartner has revealed that about 70% of organisations will shift their focus from big to small and wide data by 2025. It simplifies complex problems by making probabilistic predictions for specific parameters in the dataset.
Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets. The World Economic Forum identifies data analysts and scientists as crucial roles, predicting a 15% increase in demand for such positions by 2025.
As per the below statistics, worldwide data is expected to reach 181 zettabytes by 2025 Source: statists 2021 “Data is the new oil. Feature Engineering — Talk about the approach you took to select the essential features and how you derived new ones by adding more meaning to the dataset flow.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content