This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This involves cleaning, standardizing, merging datasets, and applying business logic. Its key goals are to store data in a format that supports fast querying and scalability and to enable real-time or near-real-time access for decision-making. It may also be sent directly to dashboards, APIs, or ML models.
Before Policy Zones, we relied on conventional access control mechanisms like access control lists (ACL) to protect datasets (“assets”) when they were accessed. However, this approach requires physical coarse-grained separation of data into distinct groupings of datasets to ensure each maintains a single purpose.
These three libraries work seamlessly together to transform static datasets into responsive, visually engaging applications — all without needing a background in web development. The sample code provides a template, but each dataset will have unique requirements for cleaning and preparation.
Load data into an accessible storage location. For our example, we will use the heart attack dataset from Kaggle as the data source to develop our ETL process. We also mount the local data folder to the data folder within the container, making the datasetaccessible to our script. Transform data into a valid format.
Every data scientist has been there: downsampling a dataset because it won’t fit into memory or hacking together a way to let a business user interact with a machine learning model. Taking it a step further, you can also access models you’ve built with BigQuery Machine Learning (BQML). No credit card required.
Most data scientists spend 15-30 minutes manually exploring each new dataset—loading it into pandas, running.info() ,describe() , and.isnull().sum() Most data scientists spend 15-30 minutes manually exploring each new dataset—loading it into pandas, running.info() ,describe() , and.isnull().sum() Which columns are problematic?
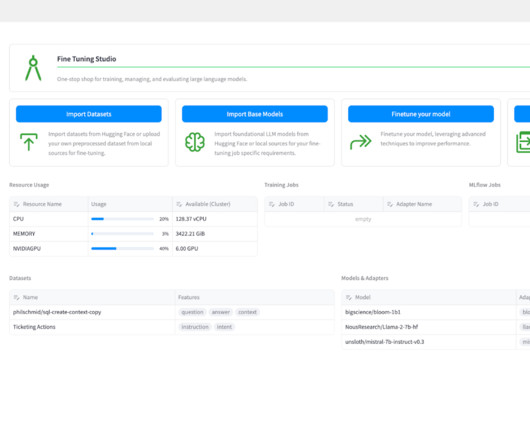
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. The Counter Abstraction API resembles Java’s AtomicInteger interface: AddCount/AddAndGetCount : Adjusts the count for the specified counter by the given delta value within a dataset.
It provides a simplified, intuitive interface where users can explore AI/BI Dashboards, ask questions using natural language via Genie, and access custom Databricks Apps. This feature allows tables governed in Unity Catalog to be accessed by Microsoft Fabric, enabling interoperability via Unity Catalog Open APIs.
Once youve created an account, access the Google Cloud Console. Machine Learning Pipeline with Google Cloud Platform To build our machine learning pipeline, we will need an example dataset. We will use the Heart Attack Prediction dataset from Kaggle for this tutorial. To do that, we must create a storage bucket for our dataset.
The square bracket notation directly accesses the key, creating a new list containing only the desired values while maintaining the original order. Filtering JSON Objects by Condition Data filtering is essential when working with large JSON datasets. Laptop, Coffee Maker, Smartphone, Desk Chair, Headphones] # 2.
This is particularly useful in environments where multiple applications need to access and process the same data. Near Real-Time Database Ingestion: We are developing a near real-time database ingestion system, utilizing CDC, to ensure timely data accessibility and efficient decision-making.
Step 3: Ingest Raw Voter Data and Register as Delta Tables With GCS access verified, I loaded three Parquet datasets—voter_demographics, voting_records, and election_results—into Databricks and converted them into Delta tables as the bronze layer. Full access requires a premium or enterprise-tier workspace.
For our S&P 500 dataset, it identifies powerful feature combinations like company age buckets (startup, growth, mature, legacy) and sector-location interactions that reveal regionally dominant industries. The prompt includes dataset statistics, column relationships, and business context to produce relevant suggestions.
You can launch it locally with: mlflow ui By default, the UI is accessible at [link]. Artifacts : Files generated during the experiment, such as models, datasets, and plots. mlruns This command uses an SQLite database for metadata storage and saves artifacts in the mlruns directory. Key Components of MLFlow 1.
Feature joins across multiple datasets were costly and slow due to Spark-based workflows. Reward signal updates needed repeated full-dataset recomputations, inflating infrastructure costs. Design: Code Consolidation: Consolidated common code across teams, e.g. the dataset readers for Iceberg and Parquet.
End-to-End ETL Workflow Using GCP and Databricks Lakeflow Job Orchestration Built a Lakeflow-style ETL Pipeline on Databricks (GCP Free Trial) using modular notebooks, GCS access via service account, Delta tables, 15-min scheduling, retries, and email alerts. This enables secure read access from Databricks.
These platforms enable scalable and distributed data processing, allowing data teams to efficiently handle massive datasets. Leverage Built-In Partitioning Features: Use built-in features provided by databases like Snowflake or Databricks to automatically partition large datasets.
This fragmentation leads to inconsistencies and wastes valuable time as teams end up reinventing metrics or seeking clarification on definitions that should be standardized and readily accessible. Enter DataJunction (DJ). DJ acts as a central store where metric definitions can live and evolve.
However, these tools are limited by their lack of access to runtime data, which can lead to false positives from unexecuted code. Improving consumption experience : streamline the consumption experience to make it easier for developers and stakeholders to access and utilize data lineage information.
The vast amount of information businesses generate often remains hidden in systems and is typically difficult to access and use. AI, on the other hand, continuously analyzes massive datasets to identify emerging risks before they become problems. According to a Box-sponsored IDC whitepaper, 90% of business data is unstructured.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. Making raw data more readable and accessible falls under the umbrella of a data engineer’s responsibilities. as they effectively summarise and label the data.
Spark uses Resilient Distributed Dataset (RDD), which allows it to keep data in memory transparently and read/write it to disc only when necessary. It can also access structured and unstructured data from various sources. Analysis and Visualization on Yelp Dataset Explore more Apache Spark Data Engineering Projects here.
For image data, running distributed PyTorch on Snowflake ML also with standard settings resulted in over 10x faster processing for a 50,000-image dataset when compared to the same managed Spark solution. Secure access to open source repositories via pip and the ability to bring in any model from hubs such as Hugging Face (see example here ).
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter AI Agents in Analytics Workflows: Too Early or Already Behind? Here, SQL stepped in.
Are your tools simple to implement and accessible to users with diverse skill sets? Embrace Version Control for Data and Code: Just as software developers use version control for code, DataOps involves tracking versions of datasets and data transformation scripts.
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. The Silver layer aims to create a structured, validated data source that multiple organizations can access. How do you ensure data quality in every layer ?
Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets. To safeguard sensitive information, compliance with frameworks like GDPR and HIPAA requires encryption, access control, and anonymization techniques.
Filling in missing values could involve leveraging other company data sources or even third-party datasets. Data Normalization Data normalization is the process of adjusting related datasets recorded with different scales to a common scale, without distorting differences in the ranges of values.
While Apache Spark™ provides robust support for approximately 10 standard data source types, the healthcare domain requires access to hundreds of specialized formats and protocols. The authors acknowledge the creators of the benchmark dataset used in their study. The custom data source processes everything in memory. Rutherford, M.
Ultimately, they are trying to serve data in their marketplace and make it accessible to business and data consumers,” Yoğurtçu says. With the rise of cloud-based data management, many organizations face the challenge of accessing both on-premises and cloud-based data. However, they require a strong data foundation to be effective.
We’ll use the famous Iris dataset and train a random forest classifier to predict the type of iris flower based on its petal and sepal measurements. Here’s the training script. Create a file called train_model.py
Similarly, companies with vast reserves of datasets and planning to leverage them must figure out how they will retrieve that data from the reserves. Work in teams to create algorithms for data storage, data collection, data accessibility, data quality checks, and, preferably, data analytics. Structured Query Language or SQL (A MUST!!):
In this case, Tudum needs to serve personalized experiences for our beloved fans, and accesses only the latest version of our content. RAW Hollow is an innovative in-memory, co-located, compressed object database developed by Netflix, designed to handle small to medium datasets with support for strong read-after-write consistency.
Each product features its own distinct data model, physical schema, query language, and access patterns. Machine learning models : trained on labeled datasets using supervised learning and improved through unsupervised learning to identify patterns and anomalies in unlabeled data.
High costs from specialized software and hardware, complex integration requirements, and inflexible schema-on-write approaches made them increasingly unsuitable for diverse, rapidly evolving datasets. This democratizes data access by leveraging existing SQL skills rather than requiring specialized programming knowledge.
Unfortunately, there is still no standard way to access all these models, as each company can develop its own framework. That is why having an open-source tool such as LiteLLM is useful when you need standardized access to your LLM apps without any additional cost. Let’s get into it.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources.
Data pipelines are crucial in managing the information lifecycle, ensuring its quality, reliability, and accessibility. Check out the following insightful post by Leon Jose , a professional data analyst, shedding light on the pivotal role of data pipelines in ensuring data quality, accessibility, and cost savings for businesses.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. All these objects are essential for managing access, configuring data connections, and building interactive Liveboards.
It offers fast SQL queries and interactive dataset analysis. Key Features: Along with direct connections to Google Cloud's streaming services like Dataflow, BigQuery includes built-in streaming capabilities that instantly ingest streaming data and make it readily accessible for querying.
Additionally, Analyst Studio provides an extract solution called Datasets, which allows you to decide when to work with periodic data snapshots and controlled data refresh schedules instead of live connections. Join the waitlist for early access or schedule a one-on-one demo today. Need to perform advanced analytics ? No problem.
Use specialized tools, such as Informatica, Goldengate, or StreamSets, if you need to conduct complex logic to detect incremental datasets. Network Security Users must install the Data Factory Self Hosted Integration runtime on their virtual machine for their storage to be accessible from within their Virtual Network on Azure (VM).
And, with largers datasets come better solutions. Use Athena in AWS to perform big data analysis on massively voluminous datasets without worrying about the underlying infrastructure or the cost associated with that infrastructure. Redshift Amazon Athena Amazon Redshift A serverless tool for building and querying large datasets.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content