This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cloudera, together with Octopai, will make it easier for organizations to better understand, access, and leverage all their data in their entire data estate – including data outside of Cloudera – to power the most robust data, analytics and AI applications.
We believe Eventador will accelerate innovation in our Cloudera DataFlow streaming platform and deliver more business value to our customers in their real-time analyticsapplications. The post Cloudera acquires Eventador to accelerate Stream Processing in Public & Hybrid Clouds appeared first on Cloudera Blog.
From understanding the delays to implementing effective solutions, dive into practical strategies for optimizing serverless performance in this blog. Every now and then, your application experiences a slow start-up time, affecting user experience. Discover all there is to know about AWS Lambda Cold Starts with our in-depth guide.
In this blog, we will explore the roles of data engineers and data architects and the key differences between them. After reading this blog, you'll have a better understanding of who builds the data castle and how they do it. Data Engineers are responsible for integrating and cleaning data for usage in analyticsapplications.
This blog post is intended to provide guidance to Ozone administrators and application developers on the optimal usage of the bucket layouts for different applications. Bucket Layouts in Apache Ozone Interoperability between FS and S3 API Users can store their data in Apache Ozone and can access the data with multiple protocols.
With over 24K customers worldwide and 2K Github repositories, DynamoDB is one of the most popular NoSQL databases available today, allowing developers to focus on building applications without worrying about maintaining the underlying infrastructure. MongoDB fully supports secondary indexes, ensuring fast access to data by any field.
AWS vs. GCP blog compares the two major cloud platforms to help you choose the best one. Table of Contents AWS vs. GCP - The Cloud Battle AWS vs. Popular instances where GCP is used widely are machine learning analytics, application modernization, security, and business collaboration. Let’s get started!
However, in the typical enterprise, only a small team has the core skills needed to gain access and create value from streams of data. Contrast that with the skills honed over decades for gaining access, building data warehouses, performing ETL, creating reports and/or applications using structured query language (SQL).
This blog is all about that—specifically, the top 10 data pipeline tools that data engineers worldwide rely on. From the initial extraction of raw data to its eventual loading into a data warehouse or analytical platform, data pipelines play a pivotal role in shaping the information narrative within an organization.
From reducing storage costs to improving data accessibility and enhancing security, the advantages of cloud storage solutions are endless. This blog will help you take a closer look at Azure Blob Storage and explore its key features, benefits, and use cases. Table of Contents What is Microsoft Azure Blob Storage?
Its integration with other Azure services and support for real-time analytics and machine learning make it a valuable tool for many businesses. Read this blog to understand the benefits of using Apache Spark on Azure, the various Azure services available for Spark, and a few suitable use case scenarios for Spark on Azure.
With AWS DevOps, data scientists and engineers can access a vast range of resources to help them build and deploy complex data processing pipelines, machine learning models, and more. This blog will explore 15 exciting AWS DevOps project ideas that can help you gain hands-on experience with these powerful tools and services.
The ability to manage how the data flows and transforms during the first mile of the data pipeline and control the data distribution can accelerate the performance of all analyticapplications. The post Why Modernizing the First Mile of the Data Pipeline Can Accelerate all Analytics appeared first on Cloudera Blog.
In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3). Interoperability of the same data for several workloads: multi-protocol access. Ranger policies enable authorization access to Ozone resources (volume, bucket, and key).
Becoming a successful aws data engineer demands you to learn AWS for data engineering and leverage its various services for building efficient business applications. It is useful to learn about the different cloud services AWS offers for the first-ever step of any data analytics process, i.e., data engineering on AWS!
The blog crossed the 2000 members mark (❤️) and I won the best data science newsletter award. Introducing ADBC: Database Access for Apache Arrow — When I see "minimal-overhead alternative to JDBC/ODBC for analyticalapplications" I'm instantly in.
Introduction to Big Data Big data combines structured, semi-structured, and unstructured data collected by organizations to glean valuable insights and information using machine learning, predictive modeling , and other advanced analyticalapplications. This will give you an overview of the theory around big data analytics.
If you are still wondering whether or why you need to master SQL for data engineering, read this blog to take a deep dive into the world of SQL for data engineering and how it can take your data engineering skills to the next level. Your SQL skills as a data engineer are crucial for data modeling and analytics tasks.
Modern data platforms deliver an elastic, flexible, and cost-effective environment for analyticapplications by leveraging a hybrid, multi-cloud architecture to support data fabric, data mesh, data lakehouse and, most recently, data observability. The post Demystifying Modern Data Platforms appeared first on Cloudera Blog.
This unified data environment eliminates the need for maintaining separate data silos and facilitates seamless access to data for AI and analyticsapplications. The post Unify your data: AI and Analytics in an Open Lakehouse appeared first on Cloudera Blog. Learn more about the Cloudera Open Data Lakehouse here.
There are several big data and business analytics companies that offer a novel kind of big data innovation through unprecedented personalization and efficiency at scale. Which big data analytic companies are believed to have the biggest potential?
It is designed to simplify deployment, configuration, and serviceability of Solr-based analyticsapplications. DDE also makes it much easier for application developers or data workers to self-service and get started with building insight applications or exploration services based on text or other unstructured data (i.e.
This blog will help you determine which data analysis tool best fits your organization by exploring the top data analysis tools in the market with their key features, pros, and cons. When choosing the right analytics tool, a million questions run through one’s mind. Well, this blog will answer all these questions in one go!
Optimized access to both full fidelity raw data and aggregations. Optimized access to both current data and historical data. Time Series and Event Analytics Specialized RTDW. Analytics storage engine for huge volumes of fast arriving data. Mutability, random access, fast scans, interactive queries.
In this blog, we will cover the most popular ideas for Predictive Financial Modeling Projects you need to explore. That's why having access to a repository of solved projects can save you time and effort. But, before we start with that, let us discuss a few real-life examples of predictive modeling.
The open-source KNIME Analytics Platform allows anyone to analyze data and develop data science workflows and reusable elements. The KNIME Server is a commercial platform that allows you to automate, manage, and deploy data science workflows as analyticalapplications and services.
Discover the perfect synergy between Kubernetes and Data Science as we unveil a treasure trove of innovative Data Science Kubernetes projects in this blog. By practicing Kubernetes projects, data scientists can learn how to effectively deploy and scale data processing and analyticsapplications. Say hello to Kubernetes!
This blog is your go-to guide for the top 21 big data tools, their key features, and some interesting project ideas that leverage these big data tools and technologies to gain hands-on experience on enterprise. Many developers have access to it due to its integration with Python IDEs like PyCharm. Starting a career in Big Data ?
This blog aims to answer two questions as illustrated in the diagram below: How have stream processing requirements and use cases evolved as more organizations shift to “streaming first” architectures and attempt to build streaming analytics pipelines? Conclusion.
This blog invites you to explore the best cloud computing projects that will inspire you to explore the power of cloud computing and take your big data skills to the next level. Create a Kinesis Data AnalyticsApplication and utilize Glue and Athena to define the Partition Key. But why go to lengths and work on such projects?
Explore the world of data analytics with the top AWS databases! Check out this blog to discover your ideal database and uncover the power of scalable and efficient solutions for all your data analytical requirements. Developers can access data without complex configurations, ensuring increased productivity.
A machine learning engineer performs the following tasks- Implement statistical analysis and machine learning into highly available and high performance production level systems to provide ease of access to users. Automate feature engineering , model training, and evaluation process. Enrich machine learning frameworks and libraries.
SDX , which is an integral part of CDP , delivers uniform data security and governance, coupled with data visualization capabilities enabling quick onboarding of data and data platform consumers and access to insights for all of CDP across hybrid clouds at no extra cost. benchmarking study conducted by independent 3rd party ). Conclusion .
In this blog, we'll dive into some of the most commonly asked big data interview questions and provide concise and informative answers to help you ace your next big data job interview. The Hadoop MapReduce architecture has a Distributed Cache feature that allows applications to cache files. Data Size HDFS stores and processes big data.
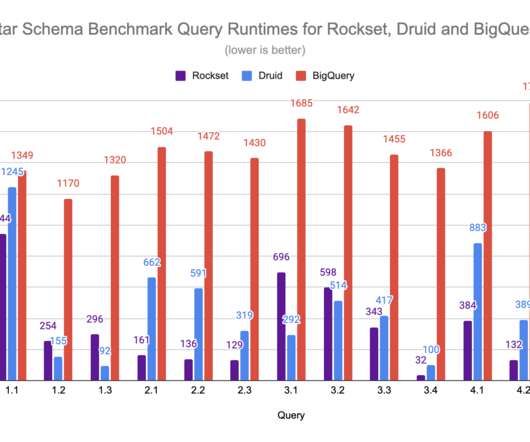
times faster than Druid in the latest performance blog post. Real-time analytics is all about deriving insights and taking actions as soon as data is produced. When broken down into its core requirements, real-time analytics means two things: access to fresh data and fast responses to queries. Learn how Rockset is 1.67
It enables cloud-native applications to store and process mass amounts of data in a hybrid multi-cloud environment and on premises. These could be traditional analyticsapplications like Spark, Impala, or Hive, or custom applications that access a cloud object store natively. Conclusion.
That’s why JetBlue innovates with real-time analytics and AI, using over 15 machine learning applications in production today for dynamic pricing, customer personalization, alerting applications, chatbots and more. Rockset provides the speed and scale required of ML applicationsaccessed daily by over 2,000 employees at JetBlue.
This leads to extra cost, effort, and risk to stitch together a sub-optimal platform for multi-disciplinary, cloud-based analyticsapplications. Because metadata is always associated with your data, you can open up self-service access to more diverse users and apps without those apps becoming data silos in cloud.
In 2023, Rockset announced a new cloud architecture for search and analytics that separates compute-storage and compute-compute. With this architecture, users can separate ingestion compute from query compute, all while accessing the same real-time data. This is a game changer in disaggregated, real-time architectures.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! More application code not only takes more time to create, but it almost always results in slower queries.
We'll be publishing more posts in the series in the near future, so subscribe to our blog so you don't miss them! Analytical queries could be accelerated by caching heavily-accessed read-only data in RAM or SSDs. Get faster analytics on fresher data, at lower costs, by exploiting indexing over brute-force scanning.
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analyticapplications are able to turn the latest data into instant business insights. Design Detail.
In the end, we want all of DTCC’s data securely accessible to our internal and external stakeholders. Forward-Looking Statements This blog contains express and implied forward-looking statements, including statements regarding Snowflake and DTCC’s products, services, and technology offerings that are under development.
Apache HBase® is one of many analyticsapplications that benefit from the capabilities of Intel Optane DC persistent memory. HBase is a distributed, scalable NoSQL database that enterprises use to power applications that need random, real time read/write access to semi-structured data.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content