This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. A powerful BigDatatool, Apache Hadoop alone is far from being almighty.
Throughout the 20th century, volumes of data kept growing at an unexpected speed and machines started storing information magnetically and in other ways. Accessing and storing huge data volumes for analytics was going on for a long time. Types of BigData 1. Then computers started doing the same.
This article will discuss bigdata analytics technologies, technologies used in bigdata, and new bigdata technologies. Check out the BigData courses online to develop a strong skill set while working with the most powerful BigDatatools and technologies.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Row-access policies in Snowflake – Snowflake is one of the most well-known unicorns in the world of BigData.
Here’s what’s happening in data engineering right now. Apache Spark already has two official APIs for JVM – Scala and Java – but we’re hoping the Kotlin API will be useful as well, as we’ve introduced several unique features. Row-access policies in Snowflake – Snowflake is one of the most well-known unicorns in the world of BigData.
Apache Hive and Apache Spark are the two popular BigDatatools available for complex data processing. To effectively utilize the BigDatatools, it is essential to understand the features and capabilities of the tools. Hive uses HQL, while Spark uses SQL as the language for querying the data.
According to the Cybercrime Magazine, the global data storage is projected to be 200+ zettabytes (1 zettabyte = 10 12 gigabytes) by 2025, including the data stored on the cloud, personal devices, and public and private IT infrastructures. Certain roles like Data Scientists require a good knowledge of coding compared to other roles.
What’s more, investing in data products, as well as in AI and machine learning was clearly indicated as a priority. This suggests that today, there are many companies that face the need to make their data easily accessible, cleaned up, and regularly updated.
How much Java is required to learn Hadoop? “I want to work with bigdata and hadoop. Table of Contents Can students or professionals without Java knowledge learn Hadoop? Can students or professionals without Java knowledge learn Hadoop? What are the skills I need - to learn Hadoop?”
Hadoop is an open-source framework that is written in Java. It incorporates several analytical tools that help improve the data analytics process. With the help of these tools, analysts can discover new insights into the data. Hadoop helps in data mining, predictive analytics, and ML applications.
The data engineers are responsible for creating conversational chatbots with the Azure Bot Service and automating metric calculations using the Azure Metrics Advisor. Data engineers must know data management fundamentals, programming languages like Python and Java, cloud computing and have practical knowledge on data technology.
The key responsibilities are deploying machine learning and statistical models , resolving data ambiguities, and managing of data pipelines. BigData Engineer identifies the internal and external data sources to gather valid data sets and deals with multiple cloud computing environments.
You can check out the BigData Certification Online to have an in-depth idea about bigdatatools and technologies to prepare for a job in the domain. To get your business in the direction you want, you need to choose the right tools for bigdata analysis based on your business goals, needs, and variety.
Innovations on BigData technologies and Hadoop i.e. the Hadoop bigdatatools , let you pick the right ingredients from the data-store, organise them, and mix them. Now, thanks to a number of open source bigdata technology innovations, Hadoop implementation has become much more affordable.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. That needs to be done because raw data is painful to read and work with. Good skills in computer programming languages like R, Python, Java, C++, etc.
News on Hadoop - May 2018 Data-Driven HR: How BigData And Analytics Are Transforming Recruitment.Forbes.com, May 4, 2018. With platforms like LinkedIn and Glassdoor giving every employer access to valuable bigdata, the world of recruitment transforming to intelligent recruitment.HR
However, if you're here to choose between Kafka vs. RabbitMQ, we would like to tell you this might not be the right question to ask because each of these bigdatatools excels with its architectural features, and one can make a decision as to which is the best based on the business use case. What is Kafka?
In this blog on “Azure data engineer skills”, you will discover the secrets to success in Azure data engineering with expert tips, tricks, and best practices Furthermore, a solid understanding of bigdata technologies such as Hadoop, Spark, and SQL Server is required. Contents: Who is an Azure Data Engineer?
This blog on BigData Engineer salary gives you a clear picture of the salary range according to skills, countries, industries, job titles, etc. BigData gets over 1.2 Several industries across the globe are using BigDatatools and technology in their processes and operations. So, let's get started!
Languages Python, SQL, Java, Scala R, C++, Java Script, and Python Tools Kafka, Tableau, Snowflake, etc. Skills A data engineer should have good programming and analytical skills with bigdata knowledge. The ML engineers act as a bridge between software engineering and data science.
So, work on projects that guide you on how to build end-to-end ETL/ELT data pipelines. BigDataTools: Without learning about popular bigdatatools, it is almost impossible to complete any task in data engineering. Finally, the data is published and visualized on a Java-based custom Dashboard.
PySpark runs a completely compatible Python instance on the Spark driver (where the task was launched) while maintaining access to the Scala-based Spark cluster access. Although Spark was originally created in Scala, the Spark Community has published a new tool called PySpark, which allows Python to be used with Spark.
PySpark is used to process real-time data with Kafka and Streaming, and this exhibits low latency. Multi-Language Support PySpark platform is compatible with various programming languages, including Scala, Java, Python, and R. PySpark allows you to process data from Hadoop HDFS , AWS S3, and various other file systems.
The end of a data block points to the location of the next chunk of data blocks. DataNodes store data blocks, whereas NameNodes store these data blocks. Learn more about BigDataTools and Technologies with Innovative and Exciting BigData Projects Examples. Steps for Data preparation.
Data science professionals are scattered across various industries. This data science tool helps in digital marketing & the web admin can easily access, visualize, and analyze the website traffic, data, etc., BigDataTools 23. One of them is in digital marketing. via Google Analytics.
What client languages, data formats, and integrations does AWS Glue Schema Registry support? The Schema Registry supports Java client apps and the Apache Avro and JSON Schema data formats. Explore the ProjectPro repository to access industry-level bigdata and data science projects. PREVIOUS NEXT <
If your career goals are headed towards BigData, then 2016 is the best time to hone your skills in the direction, by obtaining one or more of the bigdata certifications. Acquiring bigdata analytics certifications in specific bigdata technologies can help a candidate improve their possibilities of getting hired.
” or “What are the various bigdatatools in the Hadoop stack that you have worked with?”- How bigdata problems are solved in retail sector? What is the largest amount of data that you have handled? What are sinks and sources in Apache Flume when working with Twitter data?
A person who designs and implements data management , monitoring, security, and privacy utilizing the entire suite of Azure data services to meet an organization's business needs is known as an Azure Data Engineer. The main exam for the Azure data engineer path is DP 203 learning path.
Modes of Execution for Apache Pig Frequently Asked Apache Pig Interview Questions and Answers Before the advent of Apache Pig, the only way to process huge volumes of data stores on HDFS was - Java based MapReduce programming. The initial step of a PigLatin program is to load the data from HDFS.
Assume that you are a Java Developer and suddenly your company hops to join the bigdata bandwagon and requires professionals with Java+Hadoop experience. If you have not sharpened your bigdata skills then you will likely get the boot, as your company will start looking for developers with Hadoop experience.
Problem-Solving Abilities: Many certification courses provide projects and assessments which require hands-on practice of bigdatatools which enhances your problem solving capabilities. Networking Opportunities: While pursuing bigdata certification course you are likely to interact with trainers and other data professionals.
Many organizations across these industries have started increasing awareness about the new bigdatatools and are taking steps to develop the bigdata talent pool to drive industrialisation of the analytics segment in India. ” Experts estimate a dearth of 200,000 data analysts in India by 2018.Gartner
Azure Data Engineer Job Description | Accenture Azure Certified Data Engineer Azure Data Engineer Certification Microsoft Azure Projects for Practice to Enhance Your Portfolio FAQs Who is an Azure Data Engineer? This is where the Azure Data Engineer enters the picture.
Still, the job role of a data scientist has now also filtered down to non-tech companies like GAP, Nike, Neiman Marcus, Clorox, and Walmart. These companies are looking to hire the brightest professionals with expertise in Math, Statistics, SQL, Hadoop, Java, Python, and R skills for their own data science teams.
Hadoop Framework works on the following two core components- 1)HDFS – Hadoop Distributed File System is the java based file system for scalable and reliable storage of large datasets. Data in HDFS is stored in the form of blocks and it operates on the Master-Slave Architecture. iii)Splittability to be processed in parallel.
Learners can access this information 24 hours a day, seven days a week. It makes it easy for businesses to turn data into money in a competitive market quickly. A business can see the value of data by using a method that is both automated and flexible. Businesses save money and time when DevOps utilities run BigDatatools.
Hadoop Common houses the common utilities that support other modules, Hadoop Distributed File System (HDFS™) provides high throughput access to application data, Hadoop YARN is a job scheduling framework that is responsible for cluster resource management and Hadoop MapReduce facilitates parallel processing of large data sets.
According to IDC, the amount of data will increase by 20 times - between 2010 and 2020, with 77% of the data relevant to organizations being unstructured. 81% of the organizations say that BigData is a top 5 IT priority. What other bigdata use cases you can think of that measure the success of an organization?
To run Kafka, remember that your local environment must have Java 8+ installed on it. It can be used to move existing Kafka data from an older version of Kafka to a newer version. There are several libraries available in Python which allow access to Apache Kafka: Kafka-python: an open-source community-based library.
Languages : Prior to obtaining a related certificate, it's crucial to have at least a basic understanding of SQL since it is the most often used language in data analytics. Python is useful for various data analytics positions. Importance : It is unquestionably worthwhile to earn the IBM Data Analyst Professional Certificate.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




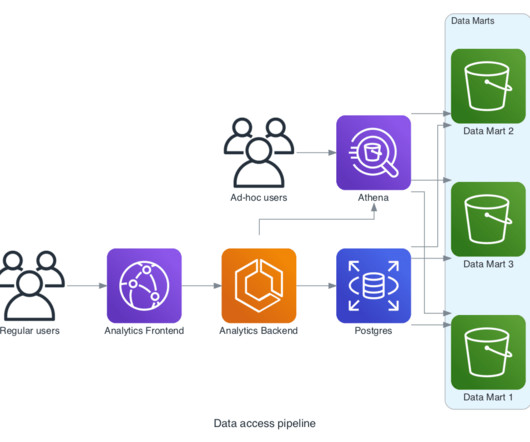
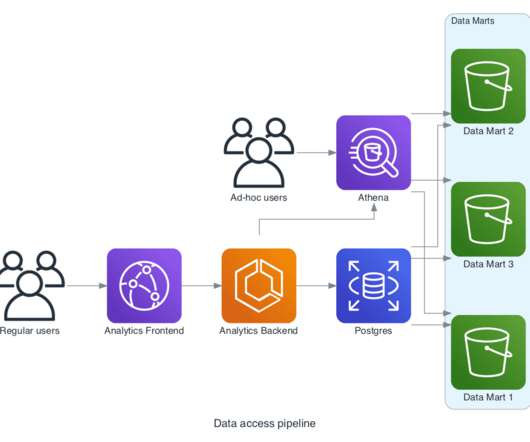










































Let's personalize your content