This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
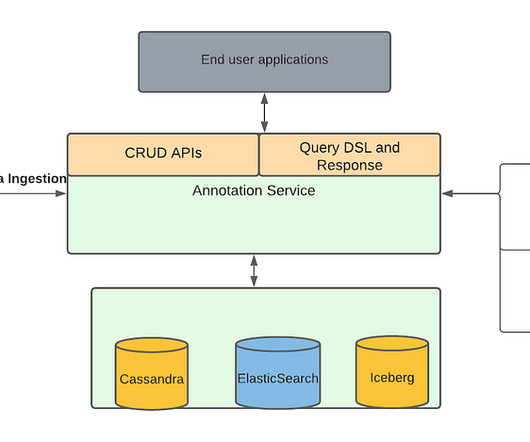
These media focused machine learning algorithms as well as other teams generate a lot of data from the media files, which we described in our previous blog , are stored as annotations in Marken. We refer the reader to our previous blog article for details. in a video file. This new operation is marked to be in STARTED state.
For more than a decade, Cloudera has been an ardent supporter and committee member of Apache NiFi, long recognizing its power and versatility for dataingestion, transformation, and delivery. and its potential to revolutionize data flow management. access our free 5-day trial now. If you can’t wait to try Apache NiFi 2.0,
By systematically moving data through these layers, the Medallion architecture enhances the data structure in a data lakehouse environment. This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority.
When you deconstruct the core database architecture, deep in the heart of it you will find a single component that is performing two distinct competing functions: real-time dataingestion and query serving. When dataingestion has a flash flood moment, your queries will slow down or time out making your application flaky.
This blog post expands on that insightful conversation, offering a critical look at Iceberg's potential and the hurdles organizations face when adopting it. Dataingestion tools often create numerous small files, which can degrade performance during query execution. What are your data governance and security requirements?
But at Snowflake, we’re committed to making the first step the easiest — with seamless, cost-effective dataingestion to help bring your workloads into the AI Data Cloud with ease. Like any first step, dataingestion is a critical foundational block. Ingestion with Snowflake should feel like a breeze.
Complete Guide to DataIngestion: Types, Process, and Best Practices Helen Soloveichik July 19, 2023 What Is DataIngestion? DataIngestion is the process of obtaining, importing, and processing data for later use or storage in a database. In this article: Why Is DataIngestion Important?
In this blog post, well discuss our experiences in identifying the challenges associated with EC2 network throttling. In the remainder of this blog post, well share how we root cause and mitigate the aboveissues. In the database service, the application reads data (e.g. 4xl with up to 12.5
DE Zoomcamp 2.2.1 – Introduction to Workflow Orchestration Following last weeks blog , we move to dataingestion. We already had a script that downloaded a csv file, processed the data and pushed the data to postgres database. This week, we got to think about our dataingestion design.
[link] Georg Heiler: Upskilling data engineers What should I prefer for 2028, or how can I break into data engineering? I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling. These are common LinkedIn requests. and then to Nuage 3.0, The article highlights Nuage 3.0's
Iceberg tables (now generally available), when combined with the capabilities of the Snowflake platform, allow you to build various open architectures, including a data lakehouse and data mesh. Parquet Direct (private preview) allows you to use Iceberg without rewriting or duplicating Parquet files — even as new Parquet files arrive.
lower latency than Elasticsearch for streaming dataingestion. In this blog, we’ll walk through the benchmark framework, configuration and results. We’ll also delve under the hood of the two databases to better understand why their performance differs when it comes to search and analytics on high-velocity data streams.
Cloudera Operational Database is now available in three different form-factors in Cloudera Data Platform (CDP). . If you are new to Cloudera Operational Database, see this blog post. In this blog post, we’ll look at both Apache HBase and Apache Phoenix concepts relevant to developing applications for Cloudera Operational Database.
In addition to big data workloads, Ozone is also fully integrated with authorization and data governance providers namely Apache Ranger & Apache Atlas in the CDP stack. While we walk through the steps one by one from dataingestion to analysis, we will also demonstrate how Ozone can serve as an ‘S3’ compatible object store.
Siloed storage : Critical business data is often locked away in disconnected databases, preventing a unified view. Delayed dataingestion : Batch processing delays insights, making real-time decision-making impossible. Heres why: AI Models Require Clean Data: Machine learning models are only as good as their training data.
This blog post explores how Snowflake can help with this challenge. Legacy SIEM cost factors to keep in mind Dataingestion: Traditional SIEMs often impose limits to dataingestion and data retention. Now there are a few ways to ingestdata into Snowflake.
Todays organizations have access to more data than ever before, and consequently are faced with the challenge of determining how to transform this tremendous stream of real-time information into actionable insights. Safeguarding Personally Identifiable Information (PII) Oftentimes, crisis data includes sensitive details (e.g.,
This is part 2 in this blog series. You can read part 1, here: Digital Transformation is a Data Journey From Edge to Insight. The first blog introduced a mock connected vehicle manufacturing company, The Electric Car Company (ECC), to illustrate the manufacturing data path through the data lifecycle.
However, that data must be ingested into our Snowflake instance before it can be used to measure engagement or help SDR managers coach their reps — and the existing ingestion process had some pain points when it came to data transformation and API calls.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? They also support ACID transactions, ensuring data integrity and stored data reliability.
Furthermore, the same tools that empower cybercrime can drive fraudulent use of public-sector data as well as fraudulent access to government systems. In financial services, another highly regulated, data-intensive industry, some 80 percent of industry experts say artificial intelligence is helping to reduce fraud.
If you’ve followed Cloudera for a while, you know we’ve long been singing the praises—or harping on the importance, depending on perspective—of a solid, standalone enterprise data strategy. The ways data strategies are implemented, the resulting outcomes and the lessons learned along the way provide important guardrails.
?. What if you could access all your data and execute all your analytics in one workflow, quickly with only a small IT team? CDP One is a new service from Cloudera that is the first data lakehouse SaaS offering with cloud compute, cloud storage, machine learning (ML), streaming analytics, and enterprise grade security built-in.
In this blog, we’ll compare and contrast how Elasticsearch and Rockset handle dataingestion as well as provide practical techniques for using these systems for real-time analytics. Or, they can periodically scan their relational database to get access to the most up to date records and reindex the data in Elasticsearch.
This is part 4 in this blog series. This blog series follows the manufacturing and operations data lifecycle stages of an electric car manufacturer – typically experienced in large, data-driven manufacturing companies. The second blog dealt with creating and managing Data Enrichment pipelines.
During the economic upheaval brought about by the COVID pandemic, the government of Australia was working with the Commonwealth Bank of Australia (CBA) to access real-time data about everyday financial transactions to understand the economic and social impacts of the crisis. Commonwealth Bank of Australia.
The platform converges data cataloging, dataingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the data preparation process and thus accelerates the data preparation by 4x.
The data and the techniques presented in this prototype are still applicable as creating a PCA feature store is often part of the machine learning process. . The process followed in this prototype covers several steps that you should follow: DataIngest – move the raw data to a more suitable storage location.
Snowpark External Access – public preview External Access is in public preview on AWS regions. Users can now easily connect to external network locations, including external LLMs, from their Snowpark code while maintaining high security and governance over their data. Snowpark Python Updates Snowpark support for Python 3.9
In the previous blog post , we looked at some of the application development concepts for the Cloudera Operational Database (COD). In this blog post, we’ll see how you can use other CDP services with COD. Integrated across the Enterprise Data Lifecycle . Cloudera Shared Data Experience (SDX) . Conclusion.
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Data Collection/Ingestion The next component in the data pipeline is the ingestion layer, which is responsible for collecting and bringing data into the pipeline.
By controlling the processing of the data flows, the cybersecurity team can now run Splunk searches 55% faster and get faster insight into potential fraud. Here is another example: the scoring system takes 70 minutes to identify a perpetrator getting access to the computer system and the time to detect the intrusion.
It can accessdata from inside the business, like ERP and asset management, outside sources, like edge devices and external assets, and correlate them for real-time predictive maintenance. A modern streaming architecture consists of critical components that provide dataingestion, security and governance, and real-time analytics.
The promise of a modern data lakehouse architecture. Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested.
It calls out that Cloudera DataFlow “ includes streaming flow and streaming data processing unified with Cloudera Data Platform ”. Hundreds of customers across multiple industry verticals are leveraging Cloudera DataFlow today for various streaming use cases like Clickstreams, log ingestion/analysis, social stream analysis, etc.
Some of the key benefits of a modern data architecture for regulatory compliance include: Enhanced data governance and compliance: Modern data architecture incorporates data governance practices and security controls to ensure data privacy, regulatory compliance, and protection against unauthorized access or breaches.
Data transformation helps make sense of the chaos, acting as the bridge between unprocessed data and actionable intelligence. You might even think of effective data transformation like a powerful magnet that draws the needle from the stack, leaving the hay behind.
The blog posts How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka and Using Apache Kafka to Drive Cutting-Edge Machine Learning describe the benefits of leveraging the Apache Kafka ® ecosystem as a central, scalable and mission-critical nervous system. For now, we’ll focus on Kafka.
By leveraging the flexibility of a data lake and the structured querying capabilities of a data warehouse, an open data lakehouse accommodates raw and processed data of various types, formats, and velocities. Learn more about the Cloudera Open Data Lakehouse here.
One of our customers, Commerzbank, has used the CDP Public Cloud trial to prove that they can combine both Google Cloud and CDP to accelerate their migration to Google Cloud without compromising data security or governance. . Data Preparation (Apache Spark and Apache Hive) .
The right set of tools helps businesses utilize data to drive insights and value. But balancing a strong layer of security and governance with easy access to data for all users is no easy task. You can become a data hero too. Retrofitting existing solutions to ever-changing policy and security demands is one option.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. With over 160 data connectors available, Fivetran makes it easy to move data out of, into, and across any cloud data platform in the market.
In this use case NiFi deployments on CDF-PC are the bridge between streaming data and services relying on data being available in ADLS Gen2. DataIngest for Microsoft Sentinel . Figure 4: Moving data from network infrastructure devices to Microsoft Sentinel.
We adopted the following mission statement to guide our investments: “Provide a complete and accurate data lineage system enabling decision-makers to win moments of truth.” As a result, a single consolidated and centralized source of truth does not exist that can be leveraged to derive data lineage truth. push or pull.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content