This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Our digital lives would be much different without cloudstorage, which makes it easy to share, access, and protect data across platforms and devices. The cloud market has huge potential and is continuously evolving with the advancement in technology and time.
Shared Data Experience ( SDX ) on Cloudera Data Platform ( CDP ) enables centralized data access control and audit for workloads in the Enterprise Data Cloud. The public cloud (CDP-PC) editions default to using cloudstorage (S3 for AWS, ADLS-gen2 for Azure). RAZ for S3 gives them that capability.
In such cases one must consider the manner in which the files will be pulled to the application while taking into account: bandwidth capacity, network latency, and the application’s file access pattern. This continues a series of posts on the topic of efficient ingestion of data from the cloud (e.g., here , here , and here ).
And that’s the target of today’s post — We’ll be developing a data pipeline using Apache Spark, Google CloudStorage, and Google Big Query (using the free tier) not sponsored. Google CloudStorage (GCS) is Google’s blob storage. Access the GCP console and create a new project. data/ mkdir -p. .
Faster compute: Iceberg's metadata layer is optimized for cloudstorage, allowing for advance file and partition pruning with minimal IO overhead. Get started: Begin activating data stored in a cloudstorage provider, without lock-in, by creating Iceberg tables directly from existing Parquet files in Snowflake.
Powered by Apache HBase and Apache Phoenix, COD ships out of the box with Cloudera Data Platform (CDP) in the public cloud. It’s also multi-cloud ready to meet your business where it is today, whether AWS, Microsoft Azure, or GCP. We tested for two cloudstorages, AWS S3 and Azure ABFS. runtime version.
introduces fine-grained authorization for access to Azure Data Lake Storage using Apache Ranger policies. Cloudera and Microsoft have been working together closely on this integration, which greatly simplifies the security administration of access to ADLS-Gen2 cloudstorage. Cloudera Data Platform 7.2.1
What are the differences in terms of pipeline design/access and usage patterns when using a Trino/Iceberg lakehouse as compared to other popular warehouse/lakehouse structures? For someone who is interested in building a data lakehouse with Trino and Iceberg, how does that influence their selection of other platform elements?
But one thing is for sure, tech enthusiasts like us will never stop hunting for the best free online cloudstorage platforms to upgrade our unlimited free cloudstorage game. What is CloudStorage? Cloudstorage provides you with cost-effective, scalable storage.
Cloudera Data platform ( CDP ) provides a Shared Data Experience ( SDX ) for centralized data access control and audit in the Enterprise Data Cloud. The Ranger Authorization Service (RAZ) is a new service added to help provide fine-grained access control (FGAC) for cloudstorage. Changes with file access control .
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. This feature is essential in environments where multiple users or applications access, modify, or analyze the same data simultaneously. Amazon S3, Azure Data Lake, or Google CloudStorage).
Read Time: 2 Minute, 30 Second For instance, Consider a scenario where we have unstructured data in our cloudstorage. Therefore, As per the requirement, Business users wants to download the files from cloudstorage. But due to compliance issue, users were not authorized to login to the cloud provider.
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. The Silver layer aims to create a structured, validated data source that multiple organizations can access. How do you ensure data quality in every layer ?
While cloud computing is pushing the boundaries of science and innovation into a new realm, it is also laying the foundation for a new wave of business start ups. 5 Reasons Your Startup Should Switch To CloudStorage Immediately 1) Cost-effective Probably the strongest argument in cloud’s favor I is the cost-effectiveness that it offers.
?. What if you could access all your data and execute all your analytics in one workflow, quickly with only a small IT team? CDP One is a new service from Cloudera that is the first data lakehouse SaaS offering with cloud compute, cloudstorage, machine learning (ML), streaming analytics, and enterprise grade security built-in.
Additionally, it offers genuine multi-cloud flexibility by integrating easily with AWS, Azure, and GCP. JSON, Avro, Parquet, and other structured and semi-structured data types are supported by the natively optimized proprietary format used by the cloudstorage layer.
After content ingestion, inspection and encoding, the packaging step encapsulates encoded video and audio in codec agnostic container formats and provides features such as audio video synchronization, random access and DRM protection. There are existing distributed file systems for the cloud as well as off-the-shelf FUSE modules for S3.
They opted for Snowflake, a cloud-native data platform ideal for SQL-based analysis. The team landed the data in a Data Lake implemented with cloudstorage buckets and then loaded into Snowflake, enabling fast access and smooth integrations with analytical tools.
Rockset’s distributed SQL engine accesses data from the relevant RocksDB instance during query processing. Step 1: Separate Compute and Storage One of the ways we first extended RocksDB to run in the cloud was by building RocksDB Cloud , in which the SST files created upon a memtable flush are also backed into cloudstorage such as Amazon S3.
Access new platform capabilities – such as the SQL Stream Builder. To use CDP, you will need to set up the following resources in your Google Cloud account: A VPC – you can use shared or dedicated VPCs – set up with subnets and firewalls as per our documentation.
Our experience so far reveals firms are still in the early stages of understanding the operational model and the total cost of ownership related to data platforms deployed in the cloud compared to on-premise deployments. In some cases, firms are surprised by cloudstorage costs and looking to repatriate data.
CDP is Cloudera’s new hybrid cloud, multi-function data platform. With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance.
We recently completed a project with IMAX, where we learned that they had developed a way to simplify and optimize the process of integrating Google CloudStorage (GCS) with Bazel. In this blog post, we’ll dive into the features, installation, and usage of rules_gcs , and how it provides you with access to private resources.
There was a strong requirement to seamlessly migrate hundreds of users, roles, and other account-level objects, including compute resources and cloudstorage integrations. Additionally, Magnite’s Snowflake account was integrated with an identity provider for Single Sign-On (SSO). Remarkably, the entire dataset with over 1.2
destroyAllWindows() By engaging in this Gesture Language Translator project, you'll not only enhance your programming skills but also contribute to fostering a more inclusive and accessible world. Student Portal: Students can enroll in courses, access course materials, and communicate with instructors and other students.
At the storage layer security, lineage, and access control play a critical role for almost all customers. A new capability called Ranger Authorization Service (RAZ) provides fine grained authorization on cloudstorage. This also enables sharing other directories with full audit trails.
To access real-time data, organizations are turning to stream processing. Striim customers often utilize a single streaming source for delivery into Kafka, Cloud Data Warehouses, and cloudstorage, simultaneously and in real-time. There are two main data processing paradigms: batch processing and stream processing.
Broad data connectivity : Seamless integration with numerous data sources enables streamlined access and analysis across systems. It also supports various sources, including cloudstorage, on-prem databases, and third-party platforms, making it highly versatile for hybrid ecosystems. How do I migrate from Power BI to Fabric?
It was only a few short years ago that the concept of cloud computing was first introduced, and it has already transformed how businesses operate. With cloud computing, businesses can now access powerful computer resources without having to invest in their own hardware. However, the hybrid cloud is not going away anytime soon.
Let’s dive into the characteristics of these PaaS deployments: Hardware (compute and storage) : With PaaS deployments, the data lakehouse will be provisioned within your cloud account. You will have access to on-demand compute and storage at your discretion. To the user, it is a serverless experience.
While using CDH on-premises cluster or CDP Private Cloud Base cluster, make sure that the following ports are open and accessible on the source hosts to allow communication between the source on-premise cluster and CDP Data Lake cluster. Specification of access conditions for specific users and groups.
With on-demand pricing, you will generally have access to up to 2000 concurrent slots, shared among all queries in a single project, which is more than enough in most cases. Physical Bytes Storage Billing BigQuery offers two billing models for storage: Standard and Physical Bytes Storage Billing.
The spatial disconnect of team members is eliminated through AI bots embedded within the cloud system, which facilitates instant communication and sharing of resources.
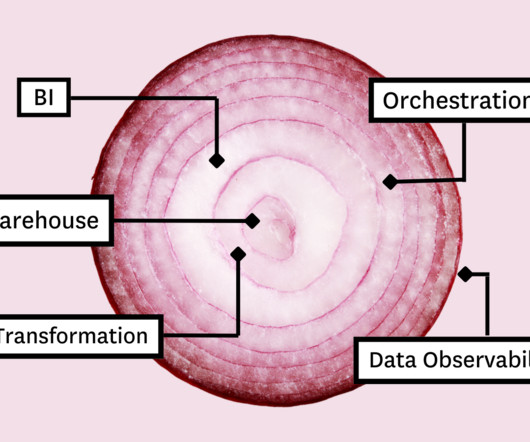
Those tools include: Cloudstorage and compute Data transformation Business intelligence Data observability And orchestration And we won’t mention ogres or bean dip again. Cloudstorage and compute Whether you’re stacking data tools or pancakes, you always build from the bottom up. Let’s dive into it.
Cybersecurity is a common domain for DataFlow deployments due to the need for timely access to data across systems, tools, and protocols. RK built some simple flows to pull streaming data into Google CloudStorage and Snowflake. Congratulations Vince! Runner up Ramakrishna Sanikommu was our runner up.
This includes services that: Manage and monitor the tenant-specific resources—this does not include access to tenant data Maintains indexed data to serve as your application home page. We secure the API key and secrets used to communicate with Azure in a secure vault storage that has role-based access control.
By encapsulating Kerberos, it eliminates the need for client software or client configuration, simplifying the access model. YARN allows you to use various data processing engines for batch, interactive, and real-time stream processing of data stored in HDFS or cloudstorage like S3 and ADLS. Provides perimeter security.
As organizations increasingly seek to enhance decision-making and drive operational efficiencies by making knowledge in documents accessible via conversational applications, a RAG-based application framework has quickly become the most efficient and scalable approach. Amazon S3) without copying the original file into Snowflake.
*For clarity, the scope of the current certification covers CDP-Private Cloud Base. Certification of CDP-Private Cloud Experiences will be considered in the future. The certification process is designed to validate Cloudera products on a variety of Cloud, Storage & Compute Platforms. Ranger 2.0.
A database is a structured data collection that is stored and accessed electronically. File systems can store small datasets, while computer clusters or cloudstorage keeps larger datasets. The designer must decide and understand the data storage, and inter-relation of data elements.
Anyone who’s fought to get access to a database or data warehouse in order to build a model can relate. Essentially, the more data we have, the more the chance that some of it goes missing or gets accessed by someone inappropriately. Taking a hard look at data privacy puts our habits and choices in a different context, however.
Data storage is a vital aspect of any Snowflake Data Cloud database. Within Snowflake, data can either be stored locally or accessed from other cloudstorage systems. What are the Different Storage Layers Available in Snowflake? These stages are unique to the user, meaning no other user can access the stage.
For example, we can run ml_engine_training_op after we export data into the cloudstorage (bq_export_op) and make this workflow run daily or weekly. It creates a simple data pipeline graph to export data into a cloudstorage bucket and then trains the ML model using MLEngineTrainingOperator. """DAG
Another NiFi landing dataflow consumes from this Kafka topic and accumulates the messages into ORC or Parquet files of an ideal size, then lands them into the cloud object storage in near real-time. In many large-scale solutions, data is divided into partitions that can be managed and accessed separately. Design Detail.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content