This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Imagine building enterprise data infrastructure where you write 90% less code but deliver twice the value. On the flip side, closed-source platforms offer unified experiences but trap you in their ecosystems where you can’t access the code or extend beyond their feature sets in case of need.
However, it also complexities the code. Probably, some of you have already seen, written, or worked with the code like this. One of the biggest changes for PySpark has been the DataFrame API. It greatly reduces the JVM-to-PVM communication overhead and improves the performance.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. feature on Facebook.
This data can be accessed and analyzed via several clients supported by MongoDB. It is also compatible with IDEs like Studio3T, JetBrains (DataGrip), and VS Code. Link to the source code. Typically, the application has a few administrators and will provide access to large files that can be shared with specific permissions.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
10 Unique Business Intelligence Projects with Source Code for 2025 For the convenience of our curious readers, we have divided the projects on business intelligence into three categories so that they can easily pick a project on the basis of their previous experience with BI techniques. influence the land prices.
Get FREE Access to Machine Learning Example Codes for Data Cleaning , Data Munging, and Data Visualization 3) Boxplot with Seaborn Seaborn is another statistical graphics library in Python built on top of matplotlib. Access Data Science and Machine Learning Project Code Examples Let’s Make it Picture Perfect!
Please don’t think twice about scrolling down if you are looking for data mining projects ideas with source code. Data Mining Project with Source Code in Python and Guided Videos - Machine Learning Project-Walmart Store Sales Forecasting. The code allows them to understand the difficulty level and customise their projects.
Movement and ease of access to data are essential to generating any form of insight or business value. Non-technical users will benefit from self-service analytics because it will make it easier to access information fast. IT professionals are often disappointed by the time spent preparing data for loading.
By KDnuggets on June 11, 2025 in Partners Sponsored Content Recommender systems rely on data, but access to truly representative data has long been a challenge for researchers. Yambda comes in 3 sizes (50M, 500M, 5B) and includes baselines to underscore accessibility and usability.
There are many examples of building neural networks to differentiate between cats and dogs so that you can download the source code for this online.If Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization 2. Access Data Science and Machine Learning Project Code Examples 14.
Backend code I wrote and pushed to prod took down Amazon.com for several hours. and hand-rolled C -code. To update code, we flipped a symlink ( a symbolic link is a file whose purpose is to point to a file or directory ) to swap between the code and HTML files contained in these directories.
It is embedded in Pythons design philosophy to emphasize that errors need to be shown explicitly, following the principle that its Easier to Ask Forgiveness than Permission (EAFP), which allows you to execute the code first before knowing whether theres an error. Let’s see the error in the Python code.
A lot of improvements have happened after the initial merge, including but not limited to: Many, many bugfixes in the code generator and runtime, witnessed by the full GHC testsuite for the wasm backend in upstream GHC CI pipelines. Show me the code! $ Now let’s run some code. nix shell gitlab:ghc/ghc-wasm-meta?host
Today, full subscribers got access to a comprehensive Senior-and-above tech compensation research. The company says: “Devin is the new state-of-the-art on the SWE-Bench coding benchmark, has successfully passed practical engineering interviews from leading AI companies, and has even completed real jobs on Upwork.
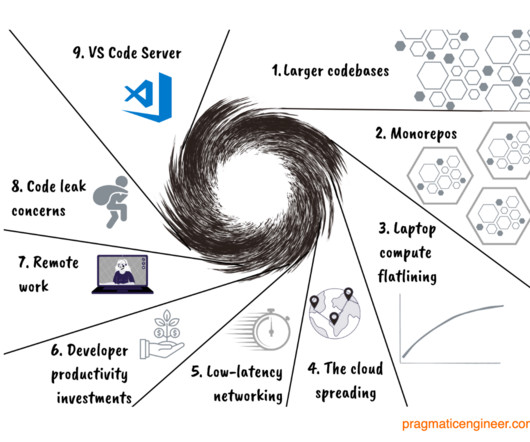
Every day, there’s more code at a tech company, not less. However, monorepos result in codebases growing large, so that even checking out the code or updating to the head can be time consuming. Concern about code leaks. With full-remote work, the risk is higher that someone other than the employee accesses the codebase.
By Abid Ali Awan , KDnuggets Assistant Editor on June 13, 2025 in Programming Image by Author Claude Opus 4 is Anthropics most advanced and powerful AI model to date, setting a new benchmark for coding, reasoning, and long-running tasks. Copy the authentication code generated by the console and paste it into the Claude Code terminal.
Accessible data pipelines in SQL For many organizations, SQL pipelines offer the most accessible entry into data transformation, empowering a wider range of team members, such as data analysts, and thereby easing the burden on data engineers. With Snowpark execution, customers have seen an average 5.6x
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Static analysis tools simulate code execution to map out data flows within our systems.
Use tech debt payments to get into the flow and stay in it A good reason to add new comments to old code before you change it is to speed up a code review. When it takes me time to learn what code does, writing something down helps me remember what I figured out. Clarifying the code is even better.
” They write the specification, code, tests it, and write the documentation. Code reviews reduce the need to pair while working on a task, allowing engineers to keep up with changes and learn from each other. CI/CD : running automated tests on all changes, and deploying code to production automatically. The copilot.
It makes complex AI workflows accessible by enabling teams to analyze documents, images and other unstructured data formats using SQL. AI observability in Snowflake Cortex AI (generally available soon) enables no-code monitoring of generative AI apps.
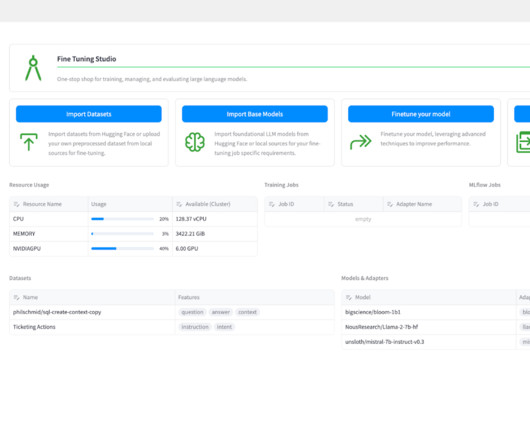
LLMs deployed as code assistants accelerate developer efficiency within an organization, ensuring that code meets standards and coding best practices. No-code, low-code, and all-code solutions. Anyone with any skill level can leverage the power of Fine Tuning Studio with or without code.
Optimize performance and cost with a broader range of model options Cortex AI provides easy access to industry-leading models via LLM functions or REST APIs, enabling you to focus on driving generative AI innovations. This no-code interface allows you to quickly experiment with, compare and evaluate models as they become available.
Making raw data more readable and accessible falls under the umbrella of a data engineer’s responsibilities. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization What do Data Engineers do? That needs to be done because raw data is painful to read and work with.
Customers can now access the most intelligent model in the Claude model family from Anthropic using familiar SQL, Python and REST API (coming soon) interfaces, within the Snowflake security perimeter. Gaining access to Anthropic's industry-leading Claude 3.5 You can access the models in one of the supported regions.
Click here to view a list of 50+ solved, end-to-end Big Data and Machine Learning Project Solutions (reusable code + videos) PyTorch 1.8 has introduced better features for code optimization, compilation, and front-ned apis for scientific computing. vs Tensorflow 2.x x in 2021 What's New in TensorFlow 2.x
MCP clients are applications (like IDEs, chatbots, or desktop apps) that connect to these servers, allowing users or AI agents to access thousands of tools and services from a single interface. Claude Desktop I really enjoy using Claude Desktop because it makes it easy to view and interact with code in dynamic ways.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. Code and raw data repository: Version control: GitHub Heavily using GitHub Actions for things like getting warehouse data from vendor APIs, starting cloud servers, running benchmarks, processing results, and cleaning up after tuns.
As a listener to the Data Engineering Podcast you can get a special discount of 20% off your ticket by using the promo code dataengpod20. What are the differences in terms of pipeline design/access and usage patterns when using a Trino/Iceberg lakehouse as compared to other popular warehouse/lakehouse structures?
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. You can produce code, discover the data schema, and modify it. By using AWS Glue Data Catalog, multiple systems can store and access metadata to manage data in data silos.
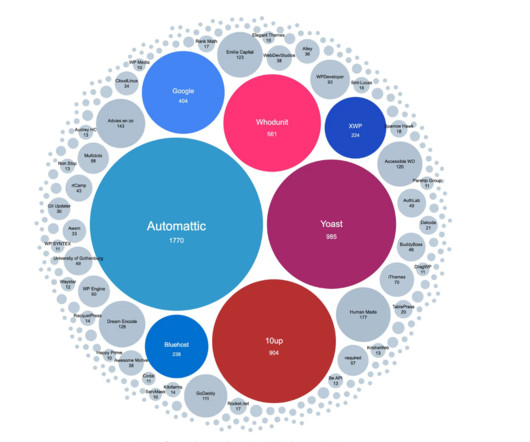
What makes Wordpress popular is a mix of factors: Restrictive license : licensed as GPLv2 , which allows for commercial use, and for modifying the code; as long as the license remains in place. Forks gaining momentum that has the code of Wordpress, but uses a different name could also be in the books. 25 Sep: Block.
Watch the video with Experian and Flo Health “With Agent Bricks, our teams were able to parse through more than 400,000 clinical trial documents and extract structured data points, without writing a single line of code.
This blog post discusses how to do that, but refer to the quickstart itself if you want to see the actual code. In its simplest form, location data is generally known as a variety of text and numeric fields that comprise what we call addresses and include things such as streets, cities, states, counties, ZIP codes and countries.
These imperatives go far beyond whats offered by platforms built for quick experimentation and vibe coding. Companies deeply invested in the Postgres ecosystem will be able to migrate and run existing applications on Snowflake without rewriting code, and roll out new ones more confidently.
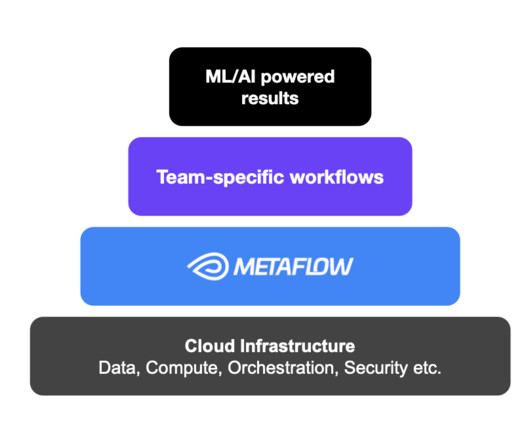
A natural solution is to make flows configurable using configuration files, so variants can be defined without changing the code. Unlike parameters, configs can be used more widely in your flow code, particularly, they can be used in step or flow level decorators as well as to set defaults for parameters.
But as technology speeds forward, organizations of all sizes are realizing that generative AI isn’t just aspirational: It’s accessible and applicable now. " Now Advisor360° has instant access to the most up-to-date customer insights — allowing the firm to provide the enterprise-class customer care it is known for.
AWS DevOps features simplify several business operations, such as maintaining infrastructure, automating software releases, monitoring applications, deploying application code, etc. These activities result in events, and if you implement such tasks by using the GitHub code repository, events are generated in the form of Git push events.
Feature Store : Feature stores are used to store variations on the feature set leveraged for machine learning models t hat multiple teams can access. Just one line of code will enable you to quickly perform the initial EDA in a visually appealing and shareable format. The source code for inspiration can be found here.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. Enter DataJunction (DJ). For example, LORE provides human-readable reasoning on how it arrived at the answer that users can cross-verify.
As described by DeepSeek , this model, trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT), can achieve performance comparable to OpenAI-o1 across math, code and reasoning tasks. To request access during preview please reach out to your sales team. The model is hosted in the U.S.
Snowflake has embraced serverless since our founding in 2012, with customers providing their code to load, manage and query data and us taking care of the rest. They can easily access multiple code interfaces, including those for SQL and Python, and the Snowflake AI & ML Studio for no-code development.
She enjoys reading, writing, coding, and coffee! Bala also creates engaging resource overviews and coding tutorials. Her areas of interest and expertise include DevOps, data science, and natural language processing.
open-webui/open-webui:cuda Once the container is running, access the Open Web UI interface in your browser at [link]. This command will: Start the Open Web UI server on port 8080 Enable GPU acceleration using the --gpus all flag Mount the necessary data directory ( -v open-webui:/app/backend/data ) docker pull ghcr.io/open-webui/open-webui:cuda
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content