This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. feature on Facebook.
10 Unique Business Intelligence Projects with Source Code for 2025 For the convenience of our curious readers, we have divided the projects on business intelligence into three categories so that they can easily pick a project on the basis of their previous experience with BI techniques. influence the land prices. to estimate the costs.
This data can be accessed and analyzed via several clients supported by MongoDB. It is also compatible with IDEs like Studio3T, JetBrains (DataGrip), and VS Code. MongoDB’s scale-out architecture allows you to shard data to handle fast querying and documentation of massive datasets. Link to the source code.
This project, although simple, is intended entirely towards understanding the various features available and configurable using the matplotlib library for a simple scatter plot, which is generally used to observe the relations between two attributes in the dataset. NOTE: The plots generated here are, however, Matplotlib objects.
Please don’t think twice about scrolling down if you are looking for data mining projects ideas with source code. FAQs on Data Mining Projects 15 Top Data Mining Projects Ideas Data Mining involves understanding the given dataset thoroughly and concluding insightful inferences from it.
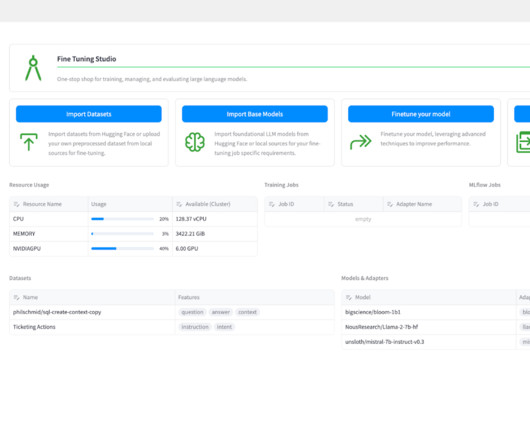
LLMs deployed as code assistants accelerate developer efficiency within an organization, ensuring that code meets standards and coding best practices. Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation. No-code, low-code, and all-code solutions.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. Making raw data more readable and accessible falls under the umbrella of a data engineer’s responsibilities. as they effectively summarise and label the data.
Movement and ease of access to data are essential to generating any form of insight or business value. Non-technical users will benefit from self-service analytics because it will make it easier to access information fast. IT professionals are often disappointed by the time spent preparing data for loading.
Pre-trained models are models trained on an existing dataset. Cat vs. Dog Image Classification System If you are a beginner in deep learning, this is a project you should start with.First, you will need to find a labeled dataset of cat and dog images. You can find an existing dataset of labeled faces on the Internet.
In order to build high-quality data lineage, we developed different techniques to collect data flow signals across different technology stacks: static code analysis for different languages, runtime instrumentation, and input and output data matching, etc. Static analysis tools simulate code execution to map out data flows within our systems.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. The Counter Abstraction API resembles Java’s AtomicInteger interface: AddCount/AddAndGetCount : Adjusts the count for the specified counter by the given delta value within a dataset.
Project Idea: You can use the Resume Dataset available on Kaggle to build this model. This dataset contains only two columns - job title and the candidate’s resume information. Tools and Libraries: Python, NLTK Dataset: Kaggle Resume Dataset Experience Hands-on Learning with the Best Course for MLOps 2.
Feature Store : Feature stores are used to store variations on the feature set leveraged for machine learning models t hat multiple teams can access. Just one line of code will enable you to quickly perform the initial EDA in a visually appealing and shareable format. The source code for inspiration can be found here.
With AWS DevOps, data scientists and engineers can access a vast range of resources to help them build and deploy complex data processing pipelines, machine learning models, and more. Suppose you want to learn to use AWS CloudFormation, a tool for defining and deploying infrastructure resources as code.
Real-World End-to-End Data Engineering Project with Source Code to Build Azure Data Factory Pipeline Step 1 - Define the Data Sources to Create Azure Data Factory Pipeline In this step, we will identify the data sources (e.g., machines, sensors) from which data needs to be extracted and loaded into a centralized data warehouse.
When Glue receives a trigger, it collects the data, transforms it using code that Glue generates automatically, and then loads it into Amazon S3 or Amazon Redshift. You can produce code, discover the data schema, and modify it. For analyzing huge datasets, they want to employ familiar Python primitive types.
Source Code: E-commerce product reviews - Pairwise ranking and sentiment analysis. Source Code: Chatbot example application using python - text classification using nltk. Source Code: Topic Modeling using K Means Clustering. Fine-tuning models on custom datasets improves accuracy for specific applications.
The first step in a machine learning project is to explore the dataset through statistical analysis. However, with large datasets, these tasks have to be automated. With time, one is likely to witness changes in the input dataset, which must be reflected in the output. you have used in your project.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. The historical dataset is over 20M records at the time of writing! They use GitHub Actions and Pulumi templates to kick off benchmark tasks: that plumbing code to start benchmarking can be found in the sc-runner repo.
Click here to view a list of 50+ solved, end-to-end Big Data and Machine Learning Project Solutions (reusable code + videos) PyTorch 1.8 has introduced better features for code optimization, compilation, and front-ned apis for scientific computing. vs Tensorflow 2.x x in 2021 What's New in TensorFlow 2.x
As different sets of text (or corpus ) are vital in computational linguistics, NLTK also gives access to many of these sets, models, and pre-trained utilities. NLTK gives access to a pretty good pre trained lemmatizer called the WordNetLemmatizer. We will use the movie reviews dataset from NLTK.
With the global data volume projected to surge from 120 zettabytes in 2023 to 181 zettabytes by 2025, PySpark's popularity is soaring as it is an essential tool for efficient large scale data processing and analyzing vast datasets. Some of the major advantages of using PySpark are- Writing code for parallel processing is effortless.
Python Flask Project Ideas for Beginners with Source Code If you are a beginner looking for Python projects using Flask, check out these interesting Python Flask projects with source code. So, get ready to build exciting Flask-based projects and take your data science and machine learning skills to the next level!
And, with largers datasets come better solutions. Use Athena in AWS to perform big data analysis on massively voluminous datasets without worrying about the underlying infrastructure or the cost associated with that infrastructure. Redshift Amazon Athena Amazon Redshift A serverless tool for building and querying large datasets.
Built on datasets that fail to capture the majority of a company's data, these models are doomed to return inaccurate results. This helps data scientists and business analysts access and analyze all the data at their disposal. Master data analytics skills with unique big data analytics mini projects with source code.
Each dataset has a separate pipeline, which you can analyze simultaneously. To assess how the model works against new datasets, you need to divide the existing labeled data into training, testing, and validation data subsets at this point. DVC handles large files, data sets, machine learning models, metrics, and code.
Metric definitions are often scattered across various databases, documentation sites, and code repositories, making it difficult for analysts and data scientists to find reliable information quickly. Enter DataJunction (DJ). For example, LORE provides human-readable reasoning on how it arrived at the answer that users can cross-verify.
The No-Code orchestration offered by Data Factory makes it an effective tool for any data engineer. Code-Free Transformation: UI-driven mapping dataflows. Ability to run Code on Any Azure Compute: Hands-on data transformations Ability to rehost on-prem services on Azure Cloud in 3 Steps: Many SSIS packages run on Azure cloud.
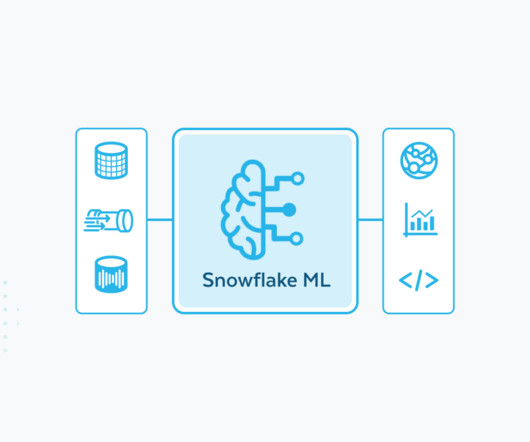
For image data, running distributed PyTorch on Snowflake ML also with standard settings resulted in over 10x faster processing for a 50,000-image dataset when compared to the same managed Spark solution. Secure access to open source repositories via pip and the ability to bring in any model from hubs such as Hugging Face (see example here ).
We developed tools and APIs for developers to organize assets, classify data, and auto-generate annotation code. Each product features its own distinct data model, physical schema, query language, and access patterns. Datasets provide a native API for creating data pipelines.
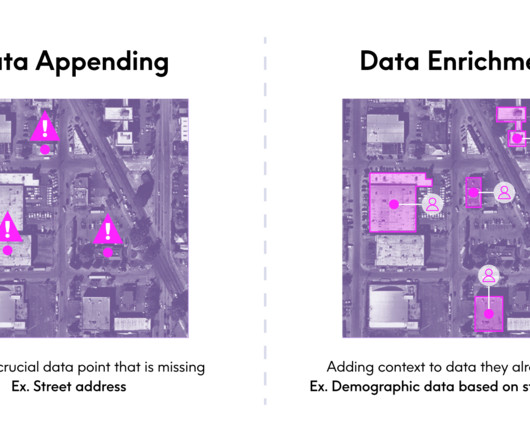
After my (admittedly lengthy) explanation of what I do as the EVP and GM of our Enrich business, she summarized it in a very succinct, but new way: “Oh, you manage the appending datasets.” Matching accuracy: Matching records between datasets is complex. ” That got me thinking.
Spark uses Resilient Distributed Dataset (RDD), which allows it to keep data in memory transparently and read/write it to disc only when necessary. It can also access structured and unstructured data from various sources. Analysis and Visualization on Yelp Dataset Explore more Apache Spark Data Engineering Projects here.
FAQs on Data Engineering Projects Top 30+ Data Engineering Project Ideas for Beginners with Source Code [2025] We recommend over 20 top data engineering project ideas with an easily understandable architectural workflow covering most industry-required data engineer skills. Build your Data Engineer Portfolio with ProjectPro!
There are three types of padding: Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization Valid Padding - In this case, the last convolution is dropped/skipped if the filter is falling outside the input matrix. Access the Dogs vs Cats to start working on this project.
Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex. text, audio) and structured (e.g.,
By extracting features from the images through a deep learning model like MobileNetV, you can use the KNN algorithm to display the images from an open-source dataset similar to your image. The pyzbar library has a decode function that locates and extracts information from Barcodes and QR codes in an image.
For example, consider the Australian Wine Sales dataset containing information about the number of wines Australian winemakers sold every month for 1980-1995. Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization An Autoregressive (AR) Process Let E t denote the variable of interest.
The AI platform can be used for several use cases like access control, number plate recognition, recommendation system, business analytics with NLP, etc. CodeCommit maintains code consistency by enabling you to store your sample code in one or more repositories.
In traditional machine learning, models are trained from scratch on specific datasets, requiring large amounts of labeled data and computational resources. Traditionally, you would start from scratch, collecting a large dataset of animal images and training a model to recognize these animals.
AWS Lambda will fetch real-time personalization scores, and Amazon DynamoDB will serve as a fast-access data layer. This dataset, containing over 200K product reviews from customers across five countries between 1995 and 2015, is a valuable asset for machine learning and natural language processing applications.
k-Nearest Neighbors (k-NN) This algorithm is simple and effective for smaller datasets, classifying emotions based on the majority class among the k-nearest neighbors. So without any further ado, we present you a functional code for a speech-emotion recognition project in Python. For now, we use it just to load into a NumPy array.
When any particular project is open-sourced, it makes the source codeaccessible to anyone. Multi-node, multi-GPU deployments are also supported by RAPIDS, allowing for substantially faster processing and training on much bigger datasets. Anyone can freely use, study, modify and improve the project, enhancing it for good.
This would allow the customer service team to quickly and easily access the prediction without going through a cumbersome process of manually inputting the data and running the model. Deploy The API: Finally, deploy the API using a platform such as Heroku or AWS to make it accessible to users. Why Practice FastAPI Projects?
This blog covers all the steps to master data preparation with machine learning datasets. In building machine learning projects , the basics involve preparing datasets. This is because the raw data usually has various inconsistencies that must be resolved before the dataset can be fed to machine learning/ deep learning algorithms.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content