This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data storage has been evolving, from databases to data warehouses and expansive datalakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like data warehouse , datalake and data lakehouse , and distributed patterns such as data mesh.
The next evolution in data is making it AI ready. For years, an essential tenet of digital transformation has been to make dataaccessible, to break down silos so that the enterprise can draw value from all of its data. For this reason, internal-facing AI will continue to be the focus for the next couple of years.
With Hybrid Tables’ fast, high-concurrency point operations, you can store application and workflow state directly in Snowflake, serve data without reverse ETL and build lightweight transactional apps while maintaining a single governance and security model for both transactional and analytical data — all on one platform.
In this episode Kevin Liu shares some of the interesting features that they have built by combining those technologies, as well as the challenges that they face in supporting the myriad workloads that are thrown at this layer of their data platform. What are the other systems that feed into and rely on the Trino/Iceberg service?
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI.
Snowflake is now making it even easier for customers to bring the platform’s usability, performance, governance and many workloads to more data with Iceberg tables (now generally available), unlocking full storage interoperability. Iceberg tables provide compute engine interoperability over a single copy of data.
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud data warehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
Summary Building a data platform that is enjoyable and accessible for all of its end users is a substantial challenge. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. Datalakes are notoriously complex.
Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used. Can you describe what Iceberg is and its position in the datalake/lakehouse ecosystem? Acryl]([link] The modern data stack needs a reimagined metadata management platform.
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. What you have to code is this workflow !
[link] Alireza Sadeghi: Open Source Data Engineering Landscape 2025 This article comprehensively overviews the 2025 open-source data engineering landscape, highlighting key trends, active projects, and emerging technologies.
Data governance plays a critical role in the successful implementation of Generative AI (GenAI) and large language models (LLM), with 86.7% It serves as a vital protective measure, ensuring proper dataaccess while managing risks like data breaches and unauthorized use. of respondents rating it as highly impactful.
Fluss uses Lakehouse as a tiered storage, and data will be converted and tiered into datalakes periodically; Fluss only retains a small portion of recent data. So you only need to store one copy of data for your streaming and Lakehouse. The TabletServer stores data and provides I/O services directly to users.
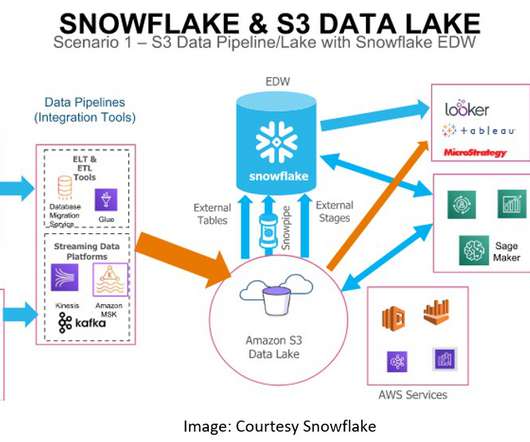
Read Time: 4 Minute, 23 Second During this post we will discuss how AWS S3 service and Snowflake integration can be used as DataLake in current organizations. How customer has migrated On Premises EDW to Snowflake to leverage snowflake DataLake capabilities.
As the magnitude and role of data in society has changed, so have the tools for dealing with it. While a +3500 year data retention capability for data stored on clay tablets is impressive, the access latency and forward compatibility of clay tablets fall a little short. Save up to 50% on compute!
Datalakes are useful, flexible data storage repositories that enable many types of data to be stored in its rawest state. Traditionally, after being stored in a datalake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption.
When it comes to storing large volumes of data, a simple database will be impractical due to the processing and throughput inefficiencies that emerge when managing and accessing big data. This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
These formats are changing the way data is stored and metadataaccessed. Apache Iceberg is a high-performance open table format developed for modern datalakes. Iceberg Data Catalog - an open-source metadata management system that tracks the schema, partition, and versions of Iceberg tables.
Acryl Data provides DataHub as an easy to consume SaaS product which has been adopted by several companies. Signup for the SaaS product at dataengineeringpodcast.com/acryl RudderStack helps you build a customer data platform on your warehouse or datalake. Can you describe what Privacera is and the story behind it?
Over the past few years, datalakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Who has access to it?
In 2010, a transformative concept took root in the realm of data storage and analytics — a datalake. The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. What is a datalake?
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. Different vendors offering data warehouses, datalakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider.
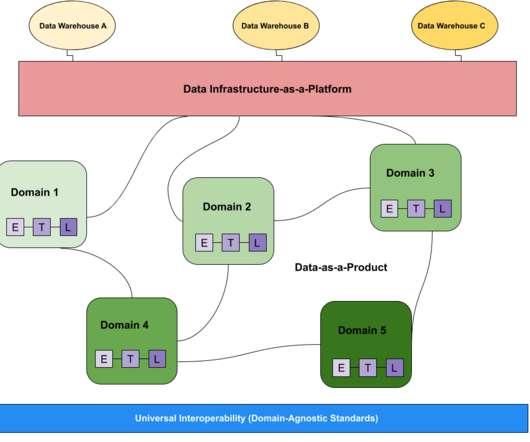
When it comes to the data community, there’s always a debate broiling about something— and right now “data mesh vs datalake” is right at the top of that list. In this post we compare and contrast the data mesh vs datalake to illustrate the benefits of each and help discover what’s right for your data platform.
Catalog Integration: Our newly developed Catalog Integration feature allows you to seamlessly plug Snowflake into other Iceberg catalogs tracking table metadata. Since 2021, Snowflake has had External Tables for the purpose of read-only querying external datalakes.
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited dataaccess, all while protecting the company’s multi-year investment in centralized data management, security, and governance. Proprietary file formats mean no one else is invited in!
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide datalakes versus smaller, typically BU-Specific, “data ponds”.
Databricks announced that Delta tables metadata will also be compatible with the Iceberg format, and Snowflake has also been moving aggressively to integrate with Iceberg. How Apache Iceberg tables structure metadata. Is your datalake a good fit for Iceberg? I think it’s safe to say it’s getting pretty cold in here.
“DataLake vs Data Warehouse = Load First, Think Later vs Think First, Load Later” The terms datalake and data warehouse are frequently stumbled upon when it comes to storing large volumes of data. Data Warehouse Architecture What is a Datalake?
Summary Business intelligence is the foremost application of data in organizations of all sizes. The typical conception of how it is accessed is through a web or desktop application running on a powerful laptop. Zing Data is building a mobile native platform for business intelligence.
It offers a simple and efficient solution for data processing in organizations. It offers users a data integration tool that organizes data from many sources, formats it, and stores it in a single repository, such as datalakes, data warehouses, etc., being data exactly matches the classifier, and 0.0
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or datalake.
Summary As your data needs scale across an organization the need for a carefully considered approach to collection, storage, organization, and access becomes increasingly critical. In terms of infrastructure, what are the components of a modern data architecture and how has that changed over the years?
Registering an Environment provides CDP with access to your cloud provider account and identifies the resources in your cloud provider account that CDP services can access or provision. When you register an Environment in CDP, a DataLake is automatically deployed for that environment. Cloudera Data Warehouse Security.
Comprehensive auditing is provided to enable enterprises to effectively and efficiently meet their compliance requirements by auditing access and other types of operations across OpDB (through HBase). User, business classification of asset accessed. Policy outcome (access or deny). Policy outcome (access or deny).
Summary The data ecosystem has been growing rapidly, with new communities joining and bringing their preferred programming languages to the mix. This has led to inefficiencies in how data is stored, accessed, and shared across process and system boundaries. Atlan is the metadata hub for your data ecosystem.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. RudderStack helps you build a customer data platform on your warehouse or datalake.
Visit them today at dataengineeringpodcast.com/timescale RudderStack helps you build a customer data platform on your warehouse or datalake. The warehouse (Bigquery, Snowflake, Redshift) has become the focal point of the "modern data stack" Data orchestration Who will be managing the workflow logic?
His key takeaways from the conversation were that “ data leaders are under tremendous pressure to collaborate within the C-Suite on projects that deliver true business value. Explore the key topics and insights from this event below, and get inspired to apply these takeaways for success in your own data-driven journey.
This blog post outlines detailed step by step instructions to perform Hive Replication from an on-prem CDH cluster to a CDP Public Cloud DataLake. CDP DataLake cluster versions – CM 7.4.0, Pre-Check: DataLake Cluster. Understanding Ranger Policies in DataLake Cluster. Runtime 7.2.8.
With Cloudera’s vision of hybrid data , enterprises adopting an open data lakehouse can easily get application interoperability and portability to and from on premises environments and any public cloud without worrying about data scaling. Why integrate Apache Iceberg with Cloudera Data Platform?
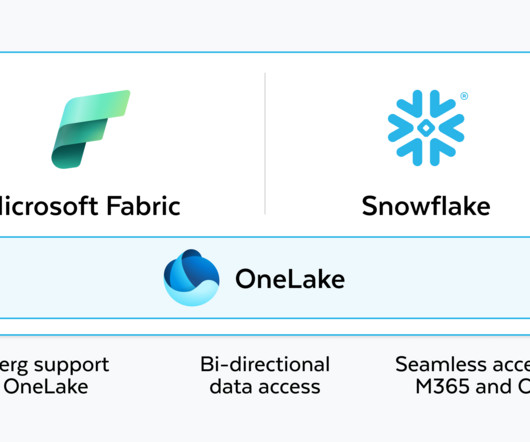
This will enable our joint customers to experience bidirectional dataaccess between Snowflake and Microsoft Fabric, with a single copy of data with OneLake in Fabric. Organizations using both platforms will be able to do so more cost-effectively, rather than building pipelines or maintaining copies of data in each platform.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content