This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Netflix, Uber, Spotify, Meta, and Airbnb offer a masterclass in scaling data operations, ensuring real-time processing, and maintaining data quality. It can easily handle millions of events per second and is where data starts in the pipeline before being consumed by another tool for storage or analysis.
Datastorage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
Annual Report: The State of Apache Airflow® 2025 DataOps on Apache Airflow® is powering the future of business – this report reviews responses from 5,000+ data practitioners to reveal how and what’s coming next. Data Council 2025 is set for April 22-24 in Oakland, CA.
This was the case for AutoTrader UK technical lead Edward Kent who spoke with my team last year about data trust and the demand for self-service analytics. “We We want to empower AutoTrader and its customers to make data-informed decisions and democratize access to data through a self-serve platform….As
The focus has also been hugely centred on compute rather than datastorage and analysis. In reality, enterprises need their data and compute to occur in multiple locations, and to be used across multiple time frames — from real time closed-loop actions, to analysis of long-term archived data.
At the same time Microsoft leaked 38To of data — through a Github repository containing a link to an Azure storage with public access open. Data Economy 💰 Cisco acquired Splunk for $28b in cash. Secoda is a data catalog tool with lineage and monitoring capabilities. Crazy amount.
At the same time Microsoft leaked 38To of data — through a Github repository containing a link to an Azure storage with public access open. Data Economy 💰 Cisco acquired Splunk for $28b in cash. Secoda is a data catalog tool with lineage and monitoring capabilities. Crazy amount.
Many customers evaluating how to protect personal information and minimize access to data look specifically to data governance in Snowflake features. Rights of access and rectification Law 25 covers right of access and rectification at a person’s request.
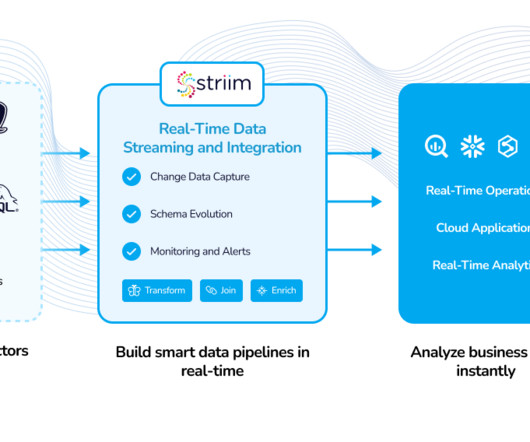
Data Mesh is revolutionizing event streaming architecture by enabling organizations to quickly and easily integrate real-time data, streaming analytics, and more. In this article, we will explore the advantages and limitations of data mesh, while also providing best practices for building and optimizing a data mesh with Striim.
Legacy security information and event management (SIEM) solutions, like Splunk, are powerful tools for managing and analyzing machine-generated data. Legacy SIEM cost factors to keep in mind Data ingestion: Traditional SIEMs often impose limits to data ingestion and data retention.
With cloud computing, businesses can now access powerful computer resources without having to invest in their own hardware. ARPANET allowed users to access information and applications from remote computers, laying the groundwork for later developments in cloud computing.
Cloudera recently hosted the Streaming Analytics in the Real World – Key Industry Use Cases virtual event to showcase practical, case-by-case applications of how fast-data and streaming analytics are revolutionizing industries. Static, historical data is no longer enough. .
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Continuous replication via CDC is an event driven architecture. This is a more efficient data pipeline methodology because it only gets triggered when there is a change to the source.”
[link] Amazon S3 Express One Zone is a high-performance, single-availability Zone storage class purpose-built to deliver consistent single-digit millisecond dataaccess for your most frequently accesseddata and latency-sensitive applications. There are two critical properties of data warehouse access patterns.
Instead of trapping data in a black box, they enable you to easily collect customer data from the entire stack and build an identity graph on your warehouse, giving you full visibility and control. Sign up free… or just get the free t-shirt for being a listener of the Data Engineering Podcast at dataengineeringpodcast.com/rudder.
Confidentiality Confidentiality in information security assures that information is accessible only by authorized individuals. It involves the actions of an organization to ensure data is kept confidential or private. Simply put, it’s about maintaining access to data to block unauthorized disclosure.
Summary The modern era of software development is identified by ubiquitous access to elastic infrastructure for computation and easy automation of deployment. This requires a new class of datastorage which can accomodate that demand without having to rearchitect your system at each level of growth.
Summary One of the biggest challenges for any business trying to grow and reach customers globally is how to scale their datastorage. To make it easier for startups to focus on delivering useful features Segment offers a flexible and reliable data infrastructure for your customer analytics and custom events.
Each of these technologies has its own strengths and weaknesses, but all of them can be used to gain insights from large data sets. As organizations continue to generate more and more data, big data technologies will become increasingly essential. Let's explore the technologies available for big data.
It provides access to industry-leading large language models (LLMs), enabling users to easily build and deploy AI-powered applications. By using Cortex, enterprises can bring AI directly to the governed data to quickly extend access and governance policies to the models.
This blog post goes over: The complexities that users will run into when self-managing Apache Kafka on the cloud and how users can benefit from building event streaming applications with a fully managed service for Apache Kafka. In the same way, messaging technologies don’t have storage, thus they cannot handle past data.
France, Brazil, and the USA are the favourites, and this year Italy is present at the event for the first time in 20 years. From a data perspective, the World Cup represents an interesting source of information. Data sources. The beginning of our journey starts with connecting to various data sources.
With video-conference resources, team members can stay connected to tasks and address general topics and events around the organization. Cloud-based platforms like Google's G Suite, Box, Dropbox, OneDrive, NextCloud, Wimi, and Samepage are handy to regulate tracking access, auditing, communication, and cooperation.
under varying load conditions as well as a wide variety of access patterns; (b) scalability?—?persisting dataaccess semantics that guarantee repeatable data read behavior for client applications. This makes multi-tenancy as well as access control of data important problems to solve.
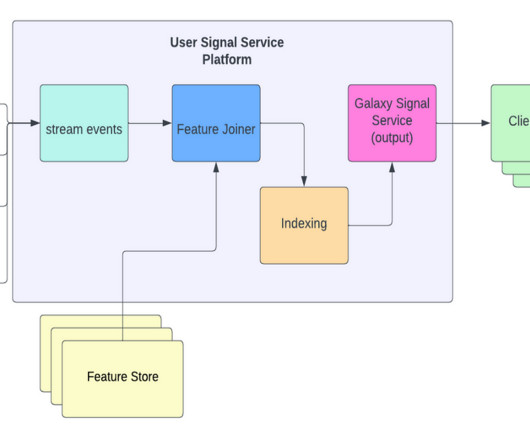
So our user sequence real-time indexing pipeline is composed of a Flink job that reads the relevant events as they come into our Kafka streams, fetches the desired features for each event from our feature services, and stores the enriched events into our KV store system. Handles out-of-order inserts.
Second, developers had to constantly re-learn new data modeling practices and common yet critical dataaccess patterns. To overcome these challenges, we developed a holistic approach that builds upon our Data Gateway Platform. This model supports both simple and complex data models, balancing flexibility and efficiency.
I recently had the privilege of attending the CDAO event in Boston hosted by Corinium. Overall, it struck me that while data science is not new, most firms are still defining the mission of the data office and data officer. A large component of their role is data management related to regulatory compliance.
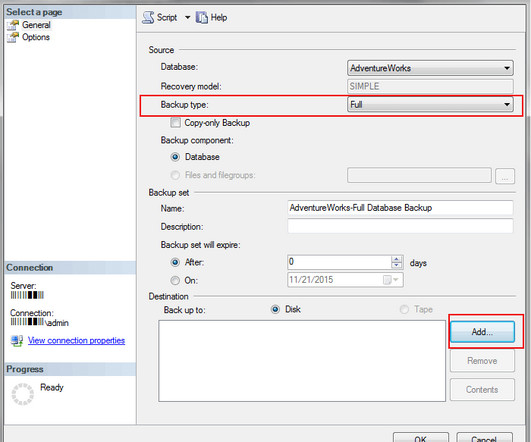
Microsoft SQL Server (MSSQL) is a popular relational database management application that facilitates datastorage and access in your organization. Backing up and restoring your MSSQL database is crucial for maintaining data integrity and availability. In the event of system failure or […]
Having only one vendor to call for updates, security patches, questions–or in the event of a problem–is a major plus for administrators. Vendors were interested in OpenStack, but customers saw better, more accessible platforms.” Reason No. 1: Support from the Top. ” Reason No. 5: Resources Can Ramp Up.
Application programming interfaces (APIs) are used to modify the retrieved data set for integration and to support users in keeping track of all the jobs. Users can schedule ETL jobs, and they can also choose the events that will trigger them. Create schedules or events that will act as job triggers.
As a result, a Big Data analytics task is split up, with each machine performing its own little part in parallel. Hadoop hides away the complexities of distributed computing, offering an abstracted API to get direct access to the system’s functionality and its benefits — such as. High latency of dataaccess. scalability.
Our initial use for Druid was for near real-time geospatial querying and high performance on high-cardinality data sets. It also allowed us to optimize for handling time-series data and eventdata at scale. Kinesis → Flink → ClickHouse : this ingestion scheme populates our eventsdata in ClickHouse.
High-quality data is essential for making well-informed decisions, performing accurate analyses, and developing effective strategies. Data quality can be influenced by various factors, such as data collection methods, data entry processes, datastorage, and data integration.
Hadoop Gigabytes to petabytes of data may be stored and processed effectively using the open-source framework known as Apache Hadoop. Hadoop enables the clustering of many computers to examine big datasets in parallel more quickly than a single powerful machine for datastorage and processing. degrees.
Having a bigger and more specialized data team can help, but it can hurt if those team members don’t coordinate. More people accessing the data and running their own pipelines and their own transformations causes errors and impacts data stability.
Cybersecurity is the term used to describe efforts to protect computer networks from unauthorized access. It encompasses a broad range of activities, including network security systems, network monitoring, and datastorage and protection. In addition, it's important to stay vigilant when it comes to cybersecurity.
When screening resumes, most hiring managers prioritize candidates who have actual experience working on data engineering projects. Top Data Engineering Projects with Source Code Data engineers make unprocessed dataaccessible and functional for other data professionals. Which queries do you have?
Data Validation : Perform quality checks to ensure the data meets quality and accuracy standards, guaranteeing its reliability for subsequent analysis. DataStorage : Store validated data in a structured format, facilitating easy access for analysis. Used for identifying and cataloging data sources.
Where we started In the mid-2010s, data teams began migrating to the cloud and adopting datastorage and compute technologies — Redshift, Snowflake, Databricks, GCP, oh my! — to The cloud made data faster to process, easier to transform and far more accessible. to meet the growing demand for analytics.
Organizations across industries moved beyond experimental phases to implement production-ready GenAI solutions within their data infrastructure. Natural Language Interfaces Companies like Uber, Pinterest, and Intuit adopted sophisticated text-to-SQL interfaces, democratizing dataaccess across their organizations.
Snowpipe micro-batch into Snowflake: Either triggered through a cloud service provider’s messaging service (such as AWS SQS , Azure Event notification , or Google Pub/Sub ) or making calls to Snowpipe ’s REST API endpoints. Snowflake can also ingest external tables from on-premise s data sources via S3-compliant datastorage APIs.
With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited dataaccess, all while protecting the company’s multi-year investment in centralized data management, security, and governance. One IT-step away from a life outside the shadows.
A growing number of companies now use this data to uncover meaningful insights and improve their decision-making, but they can’t store and process it by the means of traditional datastorage and processing units. Key Big Data characteristics. Datastorage and processing. Traditional approach.
An MDA allows you to identify silos and disparate processes, providing visibility across data functions and assets allowing rapid consolidation and harmonization. When you deploy a platform that supports MDA you can consolidate other systems, like legacy data mediation and disparate datastorage solutions.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content