This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making dataaccessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. What are data logs?
Data storage has been evolving, from databases to datawarehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
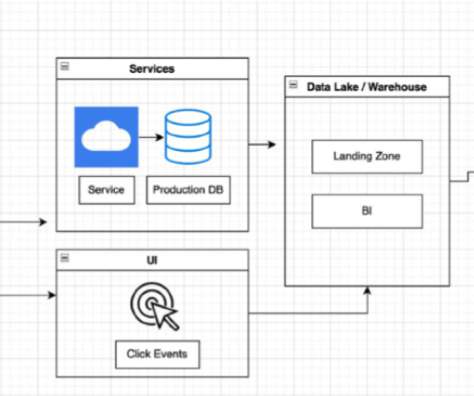
These stages propagate through various systems including function-based systems that load, process, and propagate data through stacks of function calls in different programming languages (e.g., For simplicity, we will demonstrate these for the web, the datawarehouse, and AI, per the diagram below. Hack, C++, Python, etc.)
Challenge Approach Understanding at scale (lack of foundation) At Meta, we manage hundreds of data systems and millions of assets across our family of apps. Each product features its own distinct data model, physical schema, query language, and access patterns. Creating a canonical representation for compliance tools.
Over the years, the technology landscape for data management has given rise to various architecture patterns, each thoughtfully designed to cater to specific use cases and requirements. These patterns include both centralized storage patterns like datawarehouse , data lake and data lakehouse , and distributed patterns such as data mesh.
The next evolution in data is making it AI ready. For years, an essential tenet of digital transformation has been to make dataaccessible, to break down silos so that the enterprise can draw value from all of its data. For this reason, internal-facing AI will continue to be the focus for the next couple of years.
Usually Data scientists and engineers write Extract-Transform-Load (ETL) jobs and pipelines using big data compute technologies, like Spark or Presto , to process this data and periodically compute key information for a member or a video. The processed data is typically stored as datawarehouse tables in AWS S3.
Making a decision on a cloud datawarehouse is a big deal. Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structured data to a modern platform.
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud datawarehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
First, we create an Iceberg table in Snowflake and then insert some data. Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. In the screenshot below, we can see that the metadata file for the Iceberg table retains the snapshot history.
Summary Cloud datawarehouses have unlocked a massive amount of innovation and investment in data applications, but they are still inherently limiting. Because of their complete ownership of your data they constrain the possibilities of what data you can store and how it can be used.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
TL;DR After setting up and organizing the teams, we are describing 4 topics to make data mesh a reality. With this 3rd platform generation, you have more real time data analytics and a cost reduction because it is easier to manage this infrastructure in the cloud thanks to managed services. What you have to code is this workflow !
The challenge, however, lies in accessing the relevant data. This is problematic due to the following reasons: High Cost: Fetching data for each cloud datawarehouse (CDW) query with specific filters is computationally expensive. Data filtering algorithms Lets look at the algorithm at work.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Data modeling is changing Typical data modeling techniques — like the star schema — which defined our approach to data modeling for the analytics workloads typically associated with datawarehouses, are less relevant than they once were.
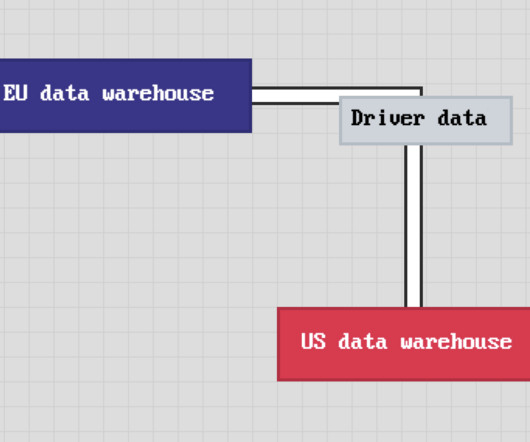
This truth was hammered home recently when ride-hailing giant Uber found itself on the receiving end of a staggering €290 million ($324 million) fine from the Dutch Data Protection Authority. Poor datawarehouse governance practices that led to the improper handling of sensitive European driver data. The reason?
How self-service data warehousing frees IT resources. Cloudera DataWarehouse (CDW) is a cloud service and an integral part of the newly released Cloudera Data Platform (CDP). Key features are: Highly scalable and performant open-source engines for BI and data warehousing workloads. Simplified provisioning.
Take advantage of old school databasetricks In the last 1015 years weve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, datawarehouses, and new tools (lots and lots of newtools). Consequently, weve had to say goodbye to some things to make room for all this new stuff.
Consensus seeking Whether you think that old-school data warehousing concepts are fading or not, the quest to achieve conformed dimensions and conformed metrics is as relevant as it ever was. The datawarehouse needs to reflect the business, and the business should have clarity on how it thinks about analytics.
While a +3500 year data retention capability for data stored on clay tablets is impressive, the access latency and forward compatibility of clay tablets fall a little short. Similarly, data platforms based on the business needs of the past dont always meet the needs of today. Save up to 50% on compute! Book a Demo!
When it comes to storing large volumes of data, a simple database will be impractical due to the processing and throughput inefficiencies that emerge when managing and accessing big data. This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem.
The most commonly used one is dataflow project , which helps folks in managing their data pipeline repositories through creation, testing, deployment and few other activities. It lets you create YAML formatted mock data files based on selected tables, columns and a few rows of data from the Netflix datawarehouse.
RudderStack’s smart customer data pipeline is warehouse-first. It builds your customer datawarehouse and your identity graph on your datawarehouse, with support for Snowflake, Google BigQuery, Amazon Redshift, and more. Interview Introduction How did you get involved in the area of data management?
Datawarehouses are the centralized repositories that store and manage data from various sources. They are integral to an organization’s data strategy, ensuring dataaccessibility, accuracy, and utility. Integration Layer : Where your data transformations and business logic are applied.
You have full control over your data and their plugin system lets you integrate with all of your other data tools, including datawarehouses and SaaS platforms. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
While cloud-native, point-solution datawarehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. Cloudera DataWarehouse (CDW) is here to save the day! CDW is an integrated datawarehouse service within Cloudera Data Platform (CDP).
The datawarehouse is the foundation of the modern data stack, so it caught our attention when we saw Convoy head of data Chad Sanderson declare, “ the datawarehouse is broken ” on LinkedIn. Treating data like an API. Immutable datawarehouses have challenges too.
Your sunk costs are minimal and if a workload or project you are supporting becomes irrelevant, you can quickly spin down your cloud datawarehouses and not be “stuck” with unused infrastructure. Cloud deployments for suitable workloads gives you the agility to keep pace with rapidly changing business and data needs.
Different vendors offering datawarehouses, data lakes, and now data lakehouses all offer their own distinct advantages and disadvantages for data teams to consider. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?
This includes services that: Manage and monitor the tenant-specific resources—this does not include access to tenant data Maintains indexed data to serve as your application home page. This multi-tenant service isolates the tenant metadata index, authorizing and filtering the search answer requests from every tenant.
Summary Business intelligence is the foremost application of data in organizations of all sizes. The typical conception of how it is accessed is through a web or desktop application running on a powerful laptop. Zing Data is building a mobile native platform for business intelligence.
“Data Lake vs DataWarehouse = Load First, Think Later vs Think First, Load Later” The terms data lake and datawarehouse are frequently stumbled upon when it comes to storing large volumes of data. DataWarehouse Architecture What is a Data lake?
TL;DR Over the past decade, Picnic transformed its approach to dataevolving from a single, all-purpose data team into multiple specialized teams using a lean, scalable tech stack. We empowered analysts by giving them access and training to the same tools as engineers, dramatically increasing speed and impact. The impact was massive.
Summary As your data needs scale across an organization the need for a carefully considered approach to collection, storage, organization, and access becomes increasingly critical. In terms of infrastructure, what are the components of a modern data architecture and how has that changed over the years?
Summary Data lineage is the roadmap for your data platform, providing visibility into all of the dependencies for any report, machine learning model, or datawarehouse table that you are working with. Atlan is the metadata hub for your data ecosystem. Can you describe what Manta is and the story behind it?
Many organizations struggle to meet growing and variable datawarehouse demands. This is exactly what Cloudera Data Platform (CDP) provides to the Cloudera DataWarehouse. CDP is a data platform that is optimized for both business units and central IT. . Cloudera DataWarehouse Security.
Geolocation data is also stored, which will help map customer locations to latitudes and longitudes to better understand where these motors are located after being sold in a vehicle. ECC will use Cloudera Data Engineering (CDE) to address the above data challenges (see Fig. 2 ECC data enrichment pipeline.
The article shows our Netflix art creators are using past data to create new artworks. ebay, Variable Hub a dataaccess layer for risk decisioning — Looks like a feature store but for risk topics. The idea is to create a unified layer that stores all the data needed to take decisions. It makes sense.
Often it is a datawarehouse solution (DWH) in the central part of our infrastructure. Datawarehouse exmaple. It’s worth mentioning that its data frame transformations have been included in one of the basic methods of data loading for many modern datawarehouses.
If you’re a Snowflake customer using ServiceNow’s popular SaaS application to manage your digital workloads, data integration is about to get a lot easier — and less costly. The connector provides immediate access to up-to-date ServiceNow data without the need to manually integrate against API endpoints.
Summary The data ecosystem has been growing rapidly, with new communities joining and bringing their preferred programming languages to the mix. This has led to inefficiencies in how data is stored, accessed, and shared across process and system boundaries. Atlan is the metadata hub for your data ecosystem.
Cloudera and Accenture demonstrate strength in their relationship with an accelerator called the Smart Data Transition Toolkit for migration of legacy datawarehouses into Cloudera Data Platform. Accenture’s Smart Data Transition Toolkit . Are you looking for your datawarehouse to support the hybrid multi-cloud?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content