This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. To harness this data effectively, we employ a process of interaction tokenization, ensuring meaningful events are identified and redundancies are minimized.
The key to those solutions is a robust and flexible metadata management system. LinkedIn has gone through several iterations on the most maintainable and scalable approach to metadata, leading them to their current work on DataHub. What were you using at LinkedIn for metadata management prior to the introduction of DataHub?
We are committed to building the data control plane that enables AI to reliably access structured data from across your entire data lineage. We believe it is important for the industry to start coalescing on best practices for safe and trustworthy ways to access your business data via LLM. What is MCP?
However, these tools are limited by their lack of access to runtime data, which can lead to false positives from unexecuted code. Improving consumption experience : streamline the consumption experience to make it easier for developers and stakeholders to access and utilize data lineage information.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Metadata Overhead: Iceberg relies heavily on metadata to track table changes and enable features like time travel.
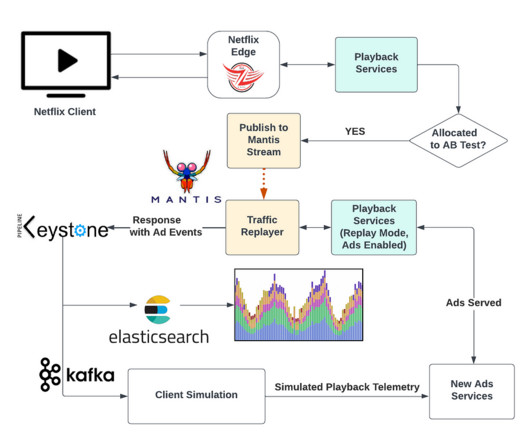
Collecting Raw Impression Events As Netflix members explore our platform, their interactions with the user interface spark a vast array of raw events. These events are promptly relayed from the client side to our servers, entering a centralized event processing queue.
Ingest data more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
link] Event Alert: MLOps World/ Gen AI World - Austin, TX - Nov 7-8 The Gen AI Summit, consisting of a wider group of 20,000 Engineers, AI entrepreneurs, and Scientists, will host 1,000 AI teams in Austin, TX, November 7-8. Passes include app-brain-date networking, birds of a feature, post-event parties, etc. What are you waiting for?
In every step,we do not just read, transform and write data, we are also doing that with the metadata. Every data governance policy about this topic must be read by a code to act in your data platform (access management, masking, etc.) Who has an access to this Data ? Last part, it was added the data security and privacy part.
Summary Building a data platform that is enjoyable and accessible for all of its end users is a substantial challenge. Developing event-driven pipelines is going to be a lot easier - Meet Functions! Memphis Logo]([link] Developing event-driven pipelines is going to be a lot easier - Meet Functions!
During a recent talk titled Hunters ATT&CKing with the Right Data , which I presented with my brother Jose Luis Rodriguez at ATT&CKcon, we talked about the importance of documenting and modeling security event logs before developing any data analytics while preparing for a threat hunting engagement. Yeah…I can do that already!
Kafka is designed for streaming events, but Fluss is designed for streaming analytics. This capability, termed Union Read, allows both layers to work in tandem for highly efficient and accurate data access. It excels in event-driven architectures and data pipelines. How do you compare Fluss with Apache Kafka?
New content or national events may drive brief spikes, but, by and large, traffic is usually smoothly increasing or decreasing. It also included metadata about ads, such as ad placement and impression-tracking events. We stored these responses in a Keystone stream with outputs for Kafka and Elasticsearch.
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. This is what managing data without metadata feels like. This is what managing data without metadata feels like. Effective metadata management is no longer a luxury—it’s a necessity.
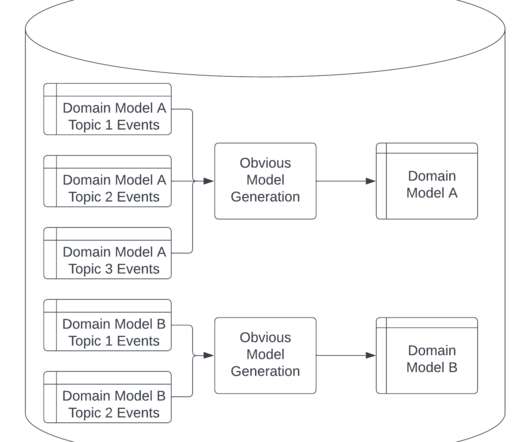
Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
At our recent Snowday event, we announced a wave of Snowflake product innovations for easier application development, new AI and LLM capabilities, better cost management and more. If you missed the event or need a refresh of what was presented, watch any Snowday session on demand. Learn more about Iceberg Tables here. Learn more.
Data & Metadata : the data of the data product in many possible storages if needed but also the metadata (data on data) Infrastructure : you will need compute & storage but with the Serverless philisophy, we want to make it totally transparent and stay focus on the first two dimensions. What you have to code is this workflow !
They are used to provide Snowflake access to unstructured datafiles and supports both of internal or external stage Query a directory table helps to retrieve the snowflake hosted file URL for each file present in stage. Directory tables metadata should be refreshed automatically when underlying stage gets updated.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Join in with the event for the global data community, Data Council Austin. Don't miss out on their only event this year! Data Council Logo]([link] Join us at the event for the global data community, Data Council Austin.
Unlike traditional planners that need to consider accessing a table via a variety of types of index, Impala’s planner always starts with a full table scan and then applies pruning techniques to reduce the data scanned. Metadata Caching. See the performance results below for an example of how metadata caching helps reduce latency.
Try Astro Free → Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Streamline code deployment, enhance collaboration, and ensure DevOps best practices with Astro's robust CI/CD capabilities.
At Snowflake, we believe in making the power of data accessible to all. Not only do we have a unique vantage point into the challenges faced by data analysts, we also possess rich metadata that feeds into Snowflake’s dedicated text-to-SQL model that Copilot leverages in combination with Mistral’s technology.
Even with detection capabilities, there is a risk that exposed credentials can provide access to sensitive data and/or the ability to cause damage in our environment. Today, we would like to share two additional layers of security: API enforcement and metadata protection.
Editor’s Note: Data Council 2025, Apr 22-24, Oakland, CA Data Council has always been one of my favorite events to connect with and learn from the data engineering community. Data Council 2025 is set for April 22-24 in Oakland, CA. Initially a self-service platform (Nuage 1.0), it transitioned to a decentralized model (Nuage 2.0)
Let’s discuss how to convert events from an event-driven microservice architecture into relational tables in a warehouse like Snowflake. Quality problems lead to first responders unable to check into disaster sites or parents unable to access ESA funds. So our solution was to start using an intentional contract: Events.
Their SDKs and plugins make event streaming easy, and their integrations with cloud applications like Salesforce and ZenDesk help you go beyond event streaming. High-growth startups use Molecula’s feature store because of its unprecedented speed, cost savings, and simplified access to all enterprise data.
Their SDKs make event streaming from any app or website easy, and their state-of-the-art reverse ETL pipelines enable you to send enriched data to any cloud tool. Acryl]([link] The modern data stack needs a reimagined metadata management platform. Acryl]([link] The modern data stack needs a reimagined metadata management platform.
Rajiv Shringi Vinay Chella Kaidan Fullerton Oleksii Tkachuk Joey Lynch Introduction As Netflix continues to expand and diversify into various sectors like Video on Demand and Gaming , the ability to ingest and store vast amounts of temporal data — often reaching petabytes — with millisecond access latency has become increasingly vital.
At the same time, organizations must ensure the right people have access to the right content, while also protecting sensitive and/or Personally Identifiable Information (PII) and fulfilling a growing list of regulatory requirements. Additional built-in UI’s and privacy enhancements make it even easier to understand and manage sensitive data.
Simply put, every item in a Kubernetes Prometheus store is a metric event that comes with a timestamp. Events are recorded in real time by Prometheus. Any event that is pertinent to your program can be included in this list, including memory usage, network activity, and specific inbound requests.
Impala Row Filtering to set access policies for rows when reading from a table. Atlas / Kafka integration provides metadata collection for Kafa producers/consumers so that consumers can manage, govern, and monitor Kafka metadata and metadata lineage in the Atlas UI. Figure 1: sales group SELECT access.
Here are a couple of the biggest takeaways we had from our time at the event. In those discussions, it was clear that everyone understood the need to treat data estates more cohesively as a whole—that means bringing more attention to security, data governance, and metadata management, the latter of which has become increasingly popular.
Second, developers had to constantly re-learn new data modeling practices and common yet critical data access patterns. This abstraction simplifies data access, enhances the reliability of our infrastructure, and enables us to support the broad spectrum of use cases that Netflix demands with minimal developer effort.
By collecting, accessing and analyzing network data from a variety of sources like VPC Flow Logs , ELB Access Logs, eBPF flow logs on the instances, etc, we can provide network insight to users and central teams through multiple data visualization techniques like Lumen , Atlas , etc.
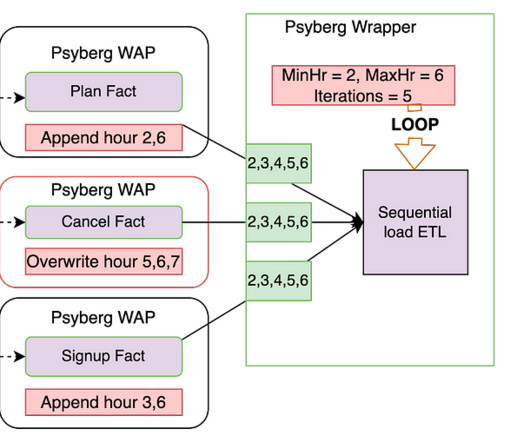
Input : List of source tables and required processing mode Output : Psyberg identifies new events that have occurred since the last high watermark (HWM) and records them in the session metadata table. The session metadata table can then be read to determine the pipeline input. Audit Run various quality checks on the staged data.
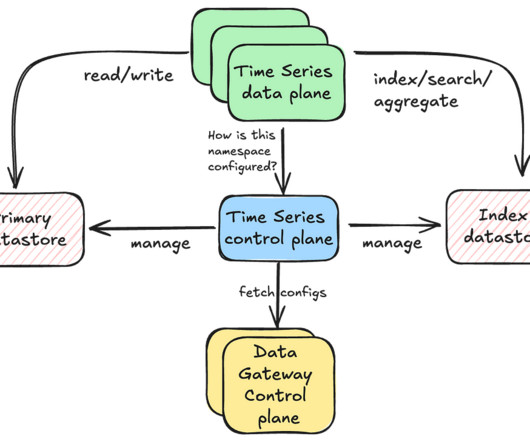
NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries. under varying load conditions as well as a wide variety of access patterns; (b) scalability?—?persisting
Getting started with version control APIs To begin, ensure that the following prerequisites are met: You have admin access (can administer Thoughtspot privilege) to connect ThoughtSpot to a Git repository and deploy commits. You have a Git repository and a branch that can be used as a default branch in ThoughtSpot.
This is particularly useful in environments where multiple applications need to access and process the same data. This configuration ensures that if the host goes down due to an EC2® event or any other reason, it will be automatically reprovisioned.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
In retrospect, complex SCD modeling techniques are not intuitive and reduce accessibility. Data engineers are also the “librarians” of the data warehouse, cataloging and organizing metadata, defining the processes by which one files or extract data from the warehouse.
the event streaming platform built by the original creators of Apache Kafka. What do we mean by contextual event-driven applications? Well, infrastructure to support event-driven applications has been around for decades; mere messaging is nothing new. Accelerate the development of contextual event-driven applications.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content