This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts. Then came Big Data and Hadoop!
But is it truly revolutionary, or is it destined to repeat the pitfalls of past solutions like Hadoop? Danny authored a thought-provoking article comparing Iceberg to Hadoop , not on a purely technical level, but in terms of their hype cycles, implementation challenges, and the surrounding ecosystems.
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data. It is a core component of the Apache Hadoop ecosystem and allows for storing and processing large datasets across multiple commodity servers.
Each dataset needs to be securely stored with minimal access granted to ensure they are used appropriately and can easily be located and disposed of when necessary. Consequently, access control mechanisms also need to scale constantly to handle the ever-increasing diversification.
Hadoop and Spark are the two most popular platforms for Big Data processing. To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop? To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop? scalability.
For organizations considering moving from a legacy data warehouse to Snowflake, looking to learn more about how the AI Data Cloud can support legacy Hadoop use cases, or assessing new options if your current cloud data warehouse just isn’t scaling anymore, it helps to see how others have done it. million in cost savings annually.
Uber stores its data in a combination of Hadoop and Cassandra for high availability and low latency access. Spotify stores much of its data in a wide variety of Google products , like Bigtable , which helps it handle high-speed access and storage.
introduces fine-grained authorization for access to Azure Data Lake Storage using Apache Ranger policies. Cloudera and Microsoft have been working together closely on this integration, which greatly simplifies the security administration of access to ADLS-Gen2 cloud storage. Use case #1: authorize users to access their home directory.
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Fine-grained Data Access Control. Introduction. Capability.
Trusted by the teams at Comcast and Doordash, Starburst delivers the adaptability and flexibility a lakehouse ecosystem promises, while providing a single point of access for your data and all your data governance allowing you to discover, transform, govern, and secure all in one place. Want to see Starburst in action?
Apache Ozone is compatible with Amazon S3 and Hadoop FileSystem protocols and provides bucket layouts that are optimized for both Object Store and File system semantics. Bucket layouts provide a single Ozone cluster with the capabilities of both a Hadoop Compatible File System (HCFS) and Object Store (like Amazon S3).
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud data warehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?
To establish a career in big data, you need to be knowledgeable about some concepts, Hadoop being one of them. Hadoop tools are frameworks that help to process massive amounts of data and perform computation. You can learn in detail about Hadoop tools and technologies through a Big Data and Hadoop training online course.
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. This feature is essential in environments where multiple users or applications access, modify, or analyze the same data simultaneously.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. Spark SQL to access Hive table. STORED AS TEXTFILE.
Prior to 2019, Marriott was an early adopter of Netezza and Hadoop, leveraging the IBM BigInsights platform. Business users have better access to data with less IT oversight needed. And third-party data is easily accessible from Snowflake Marketplace. Resources for modernizing on Snowflake Thinking about a move to Snowflake?
What are the governance policy and enforcement challenges that are added with the expansion of access and responsibility? What are the governance policy and enforcement challenges that are added with the expansion of access and responsibility? How have the responsibilities shifted across different roles?
Trusted by the teams at Comcast and Doordash, Starburst delivers the adaptability and flexibility a lakehouse ecosystem promises, while providing a single point of access for your data and all your data governance allowing you to discover, transform, govern, and secure all in one place.
Cloudera Data Platform (CDP) supports access controls on tables and columns, as well as on files and directories via Apache Ranger since its first release. In a nutshell, Ranger RMS enables automatic translation of access policies from Hive to HDFS, reducing the operational burden of policy management. How does it help?
Your host is Tobias Macey and today I'm interviewing Ryan Blue about the evolution and applications of the Iceberg table format and how he is making it more accessible at Tabular Interview Introduction How did you get involved in the area of data management? Email hosts@dataengineeringpodcast.com ) with your story.
It was designed as a native object store to provide extreme scale, performance, and reliability to handle multiple analytics workloads using either S3 API or the traditional Hadoop API. In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3).
One such major change for CDH users is the replacement of Sentry with Ranger for authorization and access control. . Having access to the right set of information helps users in preparing ahead of time and removing any hurdles in the upgrade process. Apache Sentry is a role-based authorization module for specific components in Hadoop.
If you pursue the MSc big data technologies course, you will be able to specialize in topics such as Big Data Analytics, Business Analytics, Machine Learning, Hadoop and Spark technologies, Cloud Systems etc. There are a variety of big data processing technologies available, including Apache Hadoop, Apache Spark, and MongoDB.
Delta Lake allows businesses to access and break new data down in real time. Introduction Enterprises here and now catalyze vast quantities of data, which can be a high-end source of business intelligence and insight when used appropriately.
Unfortunately, there is still a weak point where attackers can gain access to your unencrypted information. A major reason for never decrypting data is to protect it from attackers and unauthorized access. Unfortunately, there is still a weak point where attackers can gain access to your unencrypted information.
Robinhood was founded on a simple idea: that our financial markets should be accessible to all. With customers at the heart of our decisions, Robinhood is lowering barriers and providing greater access to financial information and investing. For one-off jobs, we provided access through development gateways. Authored by: Grace L.,
or higher with Kerberos enabled and admin access to both Ranger and Atlas. For example, my data volume could contain multiple buckets for every stage of the data, and I can control who accesses each stage. Using the Hadoop CLI. I mentioned at the beginning that you’d require a user with fairly open access in Hive and Ozone.
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
For example, a user can ingest data into Apache Ozone using FileSystem API, and the same data can be accessed via Ozone S3 API*. We ran Apache Hadoop Teragen benchmark tests in a conventional Hadoop stack consisting of YARN and HDFS side by side with Apache Ozone. which contains Hadoop 3.1.1, ZooKeeper 3.5.5
hadoop-aws since we almost always have interaction with S3 storage on the client side). FROM openjdk:11-jre-slim WORKDIR /app # Here, we copy the common artifacts required for any of our Spark Connect # clients (primarily spark-connect-client-jvm, as well as spark-hive, # hadoop-aws, scala-library, etc.).
For those interested in studying this programming language, several best books for python data science are accessible. There are many books on Python for data science accessible; in this article, we'll look at the top 8 of such Python books for data science as rated by Goodreads users. Let's have a look at some of the top ones.
To help other people find the show please leave a review on iTunes and tell your friends and co-workers Links Privacera Hadoop Hortonworks Apache Ranger Oracle Teradata Presto / Trino Starburst Podcast Episode Ahana Podcast Episode The intro and outro music is from The Hug by The Freak Fandango Orchestra / CC BY-SA Sponsored By: Acryl : !
Spark installations can be done on any platform but its framework is similar to Hadoop and hence having knowledge of HDFS and YARN is highly recommended. Spark standalone node cluster can be installed on the same nodes and configure Spark and Hadoop memory and CPU usage accordingly to avoid any interference. Basic knowledge of SQL.
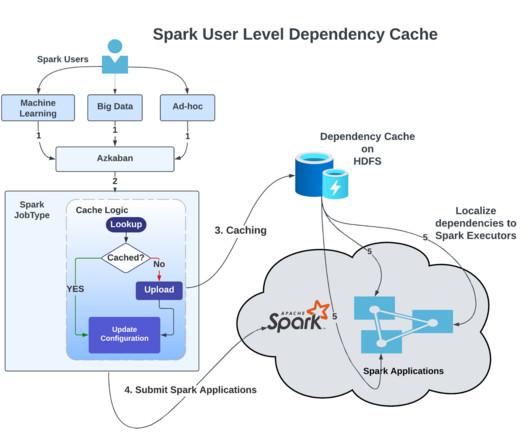
We execute nearly 100,000 Spark applications daily in our Apache Hadoop YARN (more on how we scaled YARN clusters here ). Every day, we upload nearly 30 million dependencies to the Apache Hadoop Distributed File System (HDFS) to run Spark applications.
Ten years ago, this data cluster was 300GB as a Hadoop cluster; that’s around a 100,000-fold increase in data stored! The CDN manages caching and path optimization from the customer to Agoda, mitigating some common local access problems of remote locations. The company runs 4 data centers: in the US and Europe, with two in Asia.
In this episode Daniel Mintz explains how the product is architected, the features that make it easy for any business user to access and explore their reports, and how you can use it for your organization today. Looker is a modern tool for building and sharing reports that makes it easy to get everyone on the same page.
A good Data Engineer will also have experience working with NoSQL solutions such as MongoDB or Cassandra, while knowledge of Hadoop or Spark would be beneficial. They are also responsible for ensuring that the data is clean and organized, as well as making sure that it’s easily accessible to other departments within the company.
Hadoop Gigabytes to petabytes of data may be stored and processed effectively using the open-source framework known as Apache Hadoop. Hadoop enables the clustering of many computers to examine big datasets in parallel more quickly than a single powerful machine for data storage and processing.
Summary When working with large volumes of data that you need to access in parallel across multiple instances you need a distributed filesystem that will scale with your workload. Ceph is a highly available, highly scalable, and performant system that has support for object storage, block storage, and native filesystem access.
Often it is simpler to set up perimeter security when you allow corporate network traffic to only flow to these nodes, as opposed to allowing access to Masters and Workers directly. . Apache Ranger provides the key policy framework that defines user access rights to resources. IPV6 is not supported and should be disabled.
Co-authors: Arjun Mohnot , Jenchang Ho , Anthony Quigley , Xing Lin , Anil Alluri , Michael Kuchenbecker LinkedIn operates one of the world’s largest Apache Hadoop big data clusters. Historically, deploying code changes to Hadoop big data clusters has been complex. Accessibility of all namenodes. 0 missing blocks.
Two of the more painful things in your everyday life as an analyst or SQL worker are not getting easy access to data when you need it, or not having easy to use, useful tools available to you that don’t get in your way! We have done so through smart integration and abstractions aimed to ease the backend complexity. Efficient Query Design.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content