This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
But is it truly revolutionary, or is it destined to repeat the pitfalls of past solutions like Hadoop? Danny authored a thought-provoking article comparing Iceberg to Hadoop , not on a purely technical level, but in terms of their hype cycles, implementation challenges, and the surrounding ecosystems.
Each dataset needs to be securely stored with minimal access granted to ensure they are used appropriately and can easily be located and disposed of when necessary. Consequently, access control mechanisms also need to scale constantly to handle the ever-increasing diversification.
Apache Hadoop and Apache Spark fulfill this need as is quite evident from the various projects that these two frameworks are getting better at faster data storage and analysis. These Apache Hadoopprojects are mostly into migration, integration, scalability, data analytics, and streaming analysis. Why Apache Spark?
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are HadoopProjects So Important?
If you've learned something or tried out a project from the show then tell us about it! If you've learned something or tried out a project from the show then tell us about it! The Machine Learning Podcast helps you go from idea to production with machine learning. Email hosts@dataengineeringpodcast.com with your story.
Prior the introduction of CDP Public Cloud, many organizations that wanted to leverage CDH, HDP or any other on-prem Hadoop runtime in the public cloud had to deploy the platform in a lift-and-shift fashion, commonly known as “Hadoop-on-IaaS” or simply the IaaS model. Fine-grained Data Access Control. Introduction. Capability.
If you've learned something or tried out a project from the show then tell us about it! Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud data warehouses. Email hosts@dataengineeringpodcast.com ) with your story.
Data projects are notoriously complex. I especially like the ability to combine your technical diagrams with data documentation and dependency mapping, allowing your data engineers and data consumers to communicate seamlessly about your projects. Find simplicity in your most complex projects with Miro.
Projects like Apache Iceberg provide a viable alternative in the form of data lakehouses that provide the scalability and flexibility of data lakes, combined with the ease of use and performance of data warehouses. What are the notable changes in the Iceberg project and its role in the ecosystem since our last conversation October of 2018?
With their launch of Dagster+ as the redesigned commercial companion to the open source project they are investing in that capability with a suite of new features. What are the notable enhancements beyond the Dagster Core project that this updated platform provides? What problems are you trying to solve with Dagster+?
After taking comprehensive hands-on hadoop training, the placement season is finally upon you. You applied for a Cognizant Hadoop Job interview and fortunately, were shortlisted. It is just the technical hadoop job interview that separates you from your big data career.
News on Hadoop- March 2016 Hortonworks makes its core more stable for Hadoop users. PCWorld.com Hortonworks is going a step further in making Hadoop more reliable when it comes to enterprise adoption. Source: [link] ) Syncsort makes Hadoop and Spark available in native Mainframe. March 1, 2016. March 4, 2016.
News on Hadoop-April 2016 Cutting says Hadoop is not at its peak but at its starting stages. Datanami.com At his keynote address in San Jose, Strata+Hadoop World 2016, Doug Cutting said that Hadoop is not at its peak and not going to phase out. Source: [link] ) Dr. Elephant will now solve your Hadoop flow problems.
Choosing the right Hadoop Distribution for your enterprise is a very important decision, whether you have been using Hadoop for a while or you are a newbie to the framework. Different Classes of Users who require Hadoop- Professionals who are learning Hadoop might need a temporary Hadoop deployment.
All the components of the Hadoop ecosystem, as explicit entities are evident. All the components of the Hadoop ecosystem, as explicit entities are evident. The holistic view of Hadoop architecture gives prominence to Hadoop common, Hadoop YARN, Hadoop Distributed File Systems (HDFS ) and Hadoop MapReduce of the Hadoop Ecosystem.
News on Hadoop – November 2015 2nd Generation Hadoop has become the most critical cloud applications platform, Nov 2, 2015, TechRepublic.com Hadoop version of 1.0 Hadoop second generation is designed to support real time applications where Hadoop is used not just as a storage system but as an application platform.
Professionals looking for a richly rewarded career, Hadoop is the big data technology to master now. Big Data Hadoop Technology has paid increasing dividends since it burst business consciousness and wide enterprise adoption. According to statistics provided by indeed.com there are 6000+ Hadoop jobs postings in the world.
Hadoop certifications are recognized in the industry as a confident measure of capable and qualified big data experts. Some of the commonly asked questions are - “Is hadoop certification worth the investment? Some of the commonly asked questions are - “Is hadoop certification worth the investment?”
With widespread enterprise adoption, learning Hadoop is gaining traction as it can lead to lucrative career opportunities. There are several hurdles and pitfalls students and professionals come across while learning Hadoop. How much Java is required to learn Hadoop? How much Java is required to learn Hadoop?
Data Versioning and Time Travel Open Table Formats empower users with time travel capabilities, allowing them to access previous dataset versions. This feature is essential in environments where multiple users or applications access, modify, or analyze the same data simultaneously.
News on Hadoop - Janaury 2018 Apache Hadoop 3.0 The latest update to the 11 year old big data framework Hadoop 3.0 The latest update to the 11 year old big data framework Hadoop 3.0 This new feature of YARN federation in Hadoop 3.0 This new feature of YARN federation in Hadoop 3.0
Big Data Hadoop skills are most sought after as there is no open source framework that can deal with petabytes of data generated by organizations the way hadoop does. 2014 was the year people realized the capability of transforming big data to valuable information and the power of Hadoop in impeding it. The talent pool is huge.”
The Hadoop online training session at ProjectPro is conducted through 42 hours of live webinar session where an industry expert explains all the tools in Hadoop in detail. HDFS, MapReduce, Hive and Pig are taught using hands on examples and projects. “Session was good in depth.
Ozone natively provides Amazon S3 and Hadoop Filesystem compatible endpoints in addition to its own native object store API endpoint and is designed to work seamlessly with enterprise scale data warehousing, machine learning and streaming workloads. Spark SQL to access Hive table. STORED AS TEXTFILE. spark = SparkSession. .
Hadoop was first made publicly available as an open source in 2011, since then it has undergone major changes in three different versions. Apache Hadoop 3 is round the corner with members of the Hadoop community at Apache Software Foundation still testing it. The major release of Hadoop 3.x x vs. Hadoop 3.x
Hadoop has now been around for quite some time. But this question has always been present as to whether it is beneficial to learn Hadoop, the career prospects in this field and what are the pre-requisites to learn Hadoop? The availability of skilled big data Hadoop talent will directly impact the market.
Apache Hadoop is synonymous with big data for its cost-effectiveness and its attribute of scalability for processing petabytes of data. Data analysis using hadoop is just half the battle won. Getting data into the Hadoop cluster plays a critical role in any big data deployment. then you are on the right page.
What is a Hadoop Cluster? “A hadoop cluster is a collection of independent components connected through a dedicated network to work as a single centralized data processing resource. Table of Contents What is a Hadoop Cluster? Hadoop cluster setup is inexpensive as they are held down by cheap commodity hardware.
Privacera is an enterprise grade solution for cloud and hybrid data governance built on top of the robust and battle tested Apache Ranger project. The most important piece of any data project is the data itself, which is why it is critical that your data source is high quality. Email hosts@dataengineeringpodcast.com ) with your story.
News on Hadoop-April 2017 AI Will Eclipse Hadoop, Says Forrester, So Cloudera Files For IPO As A Machine Learning Platform. Apache Hadoop was one of the revolutionary technology in the big data space but now it is buried deep by Deep Learning. Forbes.com, April 3, 2017. The new platform named Daily IQ 2.0 Hortonworks HDP 2.6
With increased enterprise adoption of Hadoop, organizations are in need of hadoop administrators to take care of the large hadoop clusters they have. The job role of a Hadoop administrator is strong and the job’s outlook is healthy, with an average of 4300 hadoop admin jobs in US as of 13 th Sept, 2016.
Hadoop has continued to grow and develop ever since it was introduced in the market 10 years ago. Every new release and abstraction on Hadoop is used to improve one or the other drawback in data processing, storage and analysis. Apache Hive is an abstraction on Hadoop MapReduce and has its own SQL like language HiveQL.
To establish a career in big data, you need to be knowledgeable about some concepts, Hadoop being one of them. Hadoop tools are frameworks that help to process massive amounts of data and perform computation. You can learn in detail about Hadoop tools and technologies through a Big Data and Hadoop training online course.
Large commercial banks like JPMorgan have millions of customers but can now operate effectively-thanks to big data analytics leveraged on increasing number of unstructured and structured data sets using the open source framework - Hadoop. Hadoop allows us to store data that we never stored before.
Let’s help you out with some detailed analysis on the career path taken by hadoop developers so you can easily decide on the career path you should follow to become a Hadoop developer. What do recruiters look for when hiring Hadoop developers? Do certifications from popular Hadoop distribution providers provide an edge?
News on Hadoop - June 2017 Hadoop Servers Expose Over 5 Petabytes of Data. According to John Matherly, the founder of Shodan, a search engine used for discovering IoT devices found that Hadoop installed improperly configured HDFS based servers exposed over 5 PB of information. BleepingComputer.com, June 2, 2017. PB of data.
Most Popular Programming Certifications C & C++ Certifications Oracle Certified Associate Java Programmer OCAJP Certified Associate in Python Programming (PCAP) MongoDB Certified Developer Associate Exam R Programming Certification Oracle MySQL Database Administration Training and Certification (CMDBA) CCA Spark and Hadoop Developer 1.
For those interested in studying this programming language, several best books for python data science are accessible. There are many books on Python for data science accessible; in this article, we'll look at the top 8 of such Python books for data science as rated by Goodreads users. Let's have a look at some of the top ones.
As I look forward to the next decade of transformation, I see that innovating in open source will accelerate along three dimensions — project, architectural, and system. These are innovations by developers, for developers, and as adoption of OSS projects has grown, innovation at the project level has accelerated sharply.
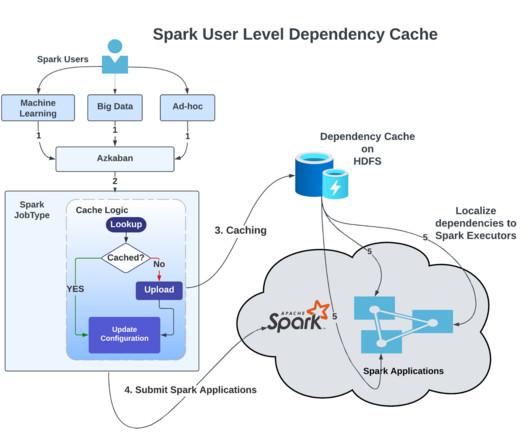
We execute nearly 100,000 Spark applications daily in our Apache Hadoop YARN (more on how we scaled YARN clusters here ). Every day, we upload nearly 30 million dependencies to the Apache Hadoop Distributed File System (HDFS) to run Spark applications. Conclusion Our project aligns with the " doing more with less " philosophy.
Summary When working with large volumes of data that you need to access in parallel across multiple instances you need a distributed filesystem that will scale with your workload. Ceph is a highly available, highly scalable, and performant system that has support for object storage, block storage, and native filesystem access.
Preamble Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out Linode. What is the governance model for the project?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management When you’re ready to build your next pipeline, or want to test out the projects you hear about on the show, you’ll need somewhere to deploy it, so check out our friends at Linode. What is the current state of the project?
hadoop-aws since we almost always have interaction with S3 storage on the client side). FROM openjdk:11-jre-slim WORKDIR /app # Here, we copy the common artifacts required for any of our Spark Connect # clients (primarily spark-connect-client-jvm, as well as spark-hive, # hadoop-aws, scala-library, etc.).
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content