This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cloudera, together with Octopai, will make it easier for organizations to better understand, access, and leverage all their data in their entire data estate – including data outside of Cloudera – to power the most robust data, analytics and AI applications.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. feature on Facebook.
Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. As data management grows increasingly complex, you need modern solutions that allow you to integrate and access your data seamlessly.
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
IoT devices in every industry; geolocation information on our phones, watches, cars, and every other mobile device; every website or app we access—all are collecting data. A single organization may have access to millions of attributes. For the future, our automation tools must collect and manage metadata at the column level.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There
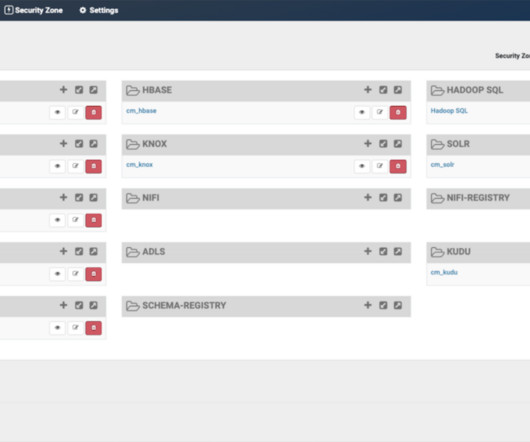
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. In a good data governance strategy, it is important to define roles that allow the business to limit the level of access that users can have to their strategic data assets.
This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models. Therefore, its also important to let foundation models use metadata information of entities and inputs, not just member interaction data.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadataaccess and management are critical for optimal system performance. Any delays in metadata retrieval can negatively impact user experience, resulting in decreased productivity and satisfaction.
For years, an essential tenet of digital transformation has been to make data accessible, to break down silos so that the enterprise can draw value from all of its data. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
However, these tools are limited by their lack of access to runtime data, which can lead to false positives from unexecuted code. Improving consumption experience : streamline the consumption experience to make it easier for developers and stakeholders to access and utilize data lineage information.
These enhancements improve data accessibility, enable business-friendly governance, and automate manual processes. Many businesses face roadblocks within their critical enterprise data, including struggles to achieve greater accessibility, business-friendly governance, and automation.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Metadata Overhead: Iceberg relies heavily on metadata to track table changes and enable features like time travel.
Ultimately, they are trying to serve data in their marketplace and make it accessible to business and data consumers,” Yoğurtçu says. With the rise of cloud-based data management, many organizations face the challenge of accessing both on-premises and cloud-based data. Focus on metadata management.
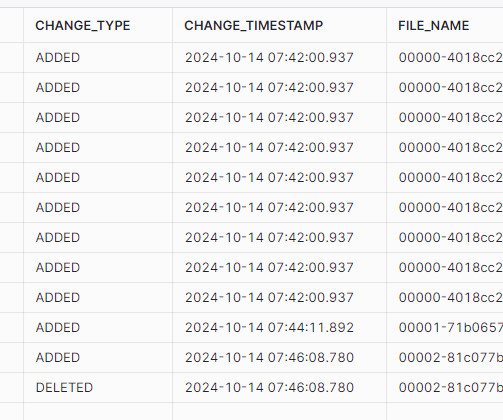
When using Iceberg tables, every Data Definition Language ( DDL ) operation triggers the generation of a new metadata JSON file that captures the updated structure. This article outlines a process for efficiently tracking schema changes in Iceberg tables by leveraging Snowflake’s powerful metadata storage capabilities.
what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? What were the requirements and selection criteria that led to the selection of that combination of technologies? Want to see Starburst in action?
Ingest data more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
It serves as a vital protective measure, ensuring proper data access while managing risks like data breaches and unauthorized use. Challenges and Considerations Balancing data access and protection is essential as GenAI tools require broad access while still adhering to governance policies. No problem!
Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. Hence, the metadata files record schema and partition changes, enabling systems to process data with the correct schema and partition structure for each relevant historical dataset.
Sign up now for early access to Materialize and get started with the power of streaming data with the same simplicity and low implementation cost as batch cloud data warehouses. Go to [dataengineeringpodcast.com/materialize]([link] Support Data Engineering Podcast
and he/she has different actions to execute (reading, calling a vision API, transform, create metadata, store them, etc…). The core idea of Data Mesh is how you can develop the data usages and remove the centralized and monolitich data warehouse where you have very less access. What you have to code is this workflow !
Unlike traditional planners that need to consider accessing a table via a variety of types of index, Impala’s planner always starts with a full table scan and then applies pruning techniques to reduce the data scanned. Metadata Caching. See the performance results below for an example of how metadata caching helps reduce latency.
Are your tools simple to implement and accessible to users with diverse skill sets? Have you considered whether your data platform allows easy access, integration, and management of data by different teams? Assign cross-functional teams to manage these data products end-to-end to maintain quality, accessibility, and reliability.
Snowflake Horizon is Snowflake’s built-in governance solution with a unified set of compliance, security, privacy, interoperability, and access capabilities. Snowflake continues to advance Snowflake Horizon with additional capabilities for compliance, security, privacy, interoperability, and access.
Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex. text, audio) and structured (e.g.,
In every step,we do not just read, transform and write data, we are also doing that with the metadata. Every data governance policy about this topic must be read by a code to act in your data platform (access management, masking, etc.) Who has an access to this Data ? Last part, it was added the data security and privacy part.
At the same time, organizations must ensure the right people have access to the right content, while also protecting sensitive and/or Personally Identifiable Information (PII) and fulfilling a growing list of regulatory requirements. Additional built-in UI’s and privacy enhancements make it even easier to understand and manage sensitive data.
Shane Gibson co-founded AgileData to make analytics accessible to companies of all sizes. Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities.
Your host is Tobias Macey and today I'm interviewing Ryan Blue about the evolution and applications of the Iceberg table format and how he is making it more accessible at Tabular Interview Introduction How did you get involved in the area of data management?
In medicine, lower sequencing costs and improved clinical access to NGS technology has been shown to increase diagnostic yield for a range of diseases, from relatively well-understood Mendelian disorders, including muscular dystrophy and epilepsy , to rare diseases such as Alagille syndrome.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Many conversations around data and analytics are focused on self-service access. Atlan is the metadata hub for your data ecosystem.
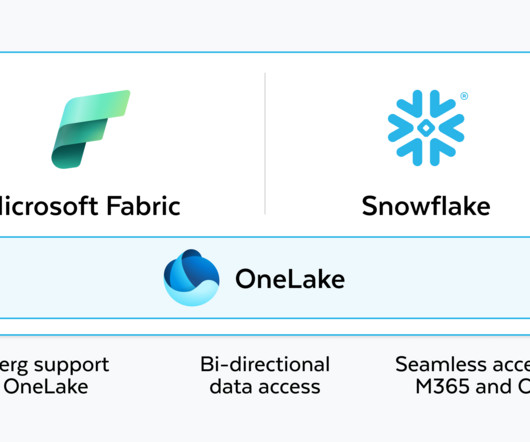
This will enable our joint customers to experience bidirectional data access between Snowflake and Microsoft Fabric, with a single copy of data with OneLake in Fabric. Data written by either platform, Snowflake or Fabric, will be accessible from both the platforms.
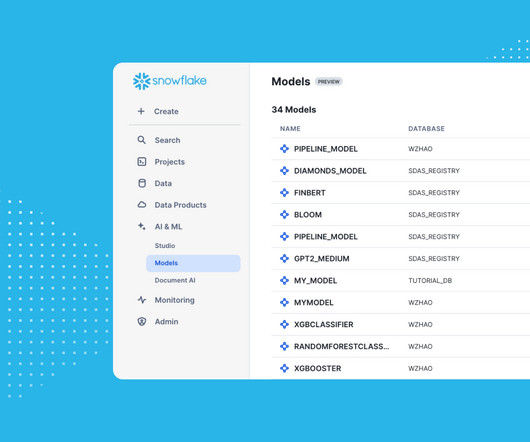
The Snowflake Model Registry , in general availability, provides a centralized repository to manage all models and their related artifacts and metadata. Models are first-class, schema-level Snowflake objects that provide fine-grained role-based access control (RBAC).
How ThoughtSpot builds trust with data catalog connectors For many, the data catalog is still the primary home for metadata enrichment and governance. Our data catalog integrations allow you to tap into this metadata wealth and surface it in the context where it’s needed most—when conducting business analytics.
It supports “fuzzy” search — the service takes in natural language queries and returns the most relevant text results, along with associated metadata. Governed : Cortex Search services are schema-level objects in Snowflake and integrate with existing role-based access control (RBAC) policies in a Snowflake account.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem. Atlan is the metadata hub for your data ecosystem.
Are your tools simple to implement and accessible to users with diverse skill sets? Have you considered whether your data platform allows easy access, integration, and management of data by different teams? Assign cross-functional teams to manage these data products end-to-end to maintain quality, accessibility, and reliability.
Zero Ingest with Zero Silos : Iceberg data already managed in a data lake can be accessed directly by Snowflake via an Iceberg catalog integration. You can quickly and easily access Iceberg data in Snowflake without the additional latency that comes with ingesting or copying data.
s architecture, key capabilities (discoverability, access control, resource management, monitoring), client interfaces (UI, APIs, CLIs), benefits (agility, ownership, performance, security), and future considerations like self-serve onboarding, infrastructure as code, and an AI assistant. and then to Nuage 3.0,
To give customers flexibility for how they fit Snowflake into their data architecture, Iceberg Tables can be configured to use either Snowflake or an external service such as AWS Glue as the table’s catalog to track metadata, with an easy, one-line SQL command to convert the table’s catalog to Snowflake in a metadata-only operation.
This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps. DDL Often, the first step in a data pipeline is to define the target table structure and column metadata via a DDL statement. For the workflow orchestration we use Netflix homegrown Maestro scheduler.
[link] Yousry Mohamed: Delta Lake Liquid Clustering — A visual explanation Liquid clustering liberates the hive-style static partitioning and organizes the data layout from the accessing pattern. Apply for early access and achieve effective data orchestration in under 10 minutes!
Snowpark ML Operations: Model management The path to production from model development starts with model management, which is the ability to track versioned model artifacts and metadata in a scalable, governed manner. The Snowpark Model Registry API provides simple catalog and retrieval operations on models.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content