This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
dbt is the standard for creating governed, trustworthy datasets on top of your structureddata. We expect that over the coming years, structureddata is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. What is MCP?
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structureddata and transactional workloads but struggled with performance at scale as data volumes grew.
The next evolution in data is making it AI ready. For years, an essential tenet of digital transformation has been to make dataaccessible, to break down silos so that the enterprise can draw value from all of its data. For this reason, internal-facing AI will continue to be the focus for the next couple of years.
Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex.
Bridging the data gap In todays data-driven landscape, organizations can gain a significant competitive advantage by effortlessly combining insights from unstructured sources like text, image, audio, and video with structureddata are gaining a significant competitive advantage.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Compute Engines: Tools that query and process data stored in Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Trino, Spark, Snowflake, DuckDB).
To give customers flexibility for how they fit Snowflake into their architecture, Iceberg Tables can be configured to use either Snowflake or an external service like AWS Glue as the tables’s catalog to track metadata, with an easy one-line SQL command to convert to Snowflake in a metadata-only operation.
Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structureddata) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”.
We live in a hybrid data world. In the past decade, the amount of structureddata created, captured, copied, and consumed globally has grown from less than 1 ZB in 2011 to nearly 14 ZB in 2020. Impressive, but dwarfed by the amount of unstructured data, cloud data, and machine data – another 50 ZB.
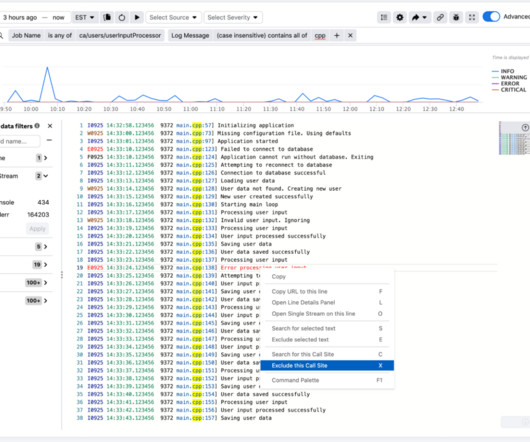
Users can query using regular expressions on log lines, arbitrary metadata fields attached to logs, and across log files of hosts and services. Logarithm’s data model Logarithm represents logs as a named log stream of (host-local) time-ordered sequences of immutable unstructured text, corresponding to a single log file. in PyTorch).
Studio is accessible within Snowsight to access interactive interfaces for teams to quickly combine multiple models with their data and compare results to accelerate deployment to applications in production. For details on pricing and what models are supported, check out more details in our documentation.
Today’s platform owners, business owners, data developers, analysts, and engineers create new apps on the Cloudera Data Platform and they must decide where and how to store that data. Structureddata (such as name, date, ID, and so on) will be stored in regular SQL databases like Hive or Impala databases.
As a result, a Big Data analytics task is split up, with each machine performing its own little part in parallel. Hadoop hides away the complexities of distributed computing, offering an abstracted API to get direct access to the system’s functionality and its benefits — such as. HDFS master-slave structure. Dataaccess options.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies.
So I decided to focus my energies in research data management. Open Context is an open accessdata publishing service for archaeology. It started because we need better ways of dissminating structureddata and digital media than is possible with conventional articles, books and reports.
A fundamental requirement for any lasting data system is that it should scale along with the growth of the business applications it wishes to serve. NMDB is built to be a highly scalable, multi-tenant, media metadata system that can serve a high volume of write/read throughput as well as support near real-time queries.
Open source data lakehouse deployments are built on the foundations of compute engines (like Apache Spark, Trino, Apache Flink), distributed storage (HDFS, cloud blob stores), and metadata catalogs / table formats (like Apache Iceberg, Delta, Hudi, Apache Hive Metastore). Tables are governed as per agreed upon company standards.
Automation , because the same loader patterns are used for both and the same metadata tags are expected from both, meaning the applied date timestamp in the business vault will match up with the raw date timestamp where it came from. These methods can be applied to structured and semi-structureddata as well.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. Specification of access conditions for specific users and groups.
Challenges & Opportunities in the Infra Data Space Security Events Platform for Anomaly Detection How can we develop a complex event processing system to ingest semi-structureddata predicated on schema contracts from hundreds of sources and transform it into event streams of structureddata for downstream analysis?
Understanding the Object Hierarchy in Metastore Identifying the Admin Roles in Unity Catalog Unveiling Data Lineage in Unity Catalog: Capture and Visualize Simplifying DataAccess using Delta Sharing 1. Improved Data Discovery The tagging and documentation features in Unity Catalog facilitate better data discovery.
Modernizing your data warehousing experience with the cloud means moving from dedicated, on-premises hardware focused on traditional relational analytics on structureddata to a modern platform. Beyond there being a number of choices each with very different strengths, the parameters for your decision have also changed.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google. Choosing the right model depends on your dataaccess patterns and compression capabilities. So, which model should you choose?
To differentiate and expand the usefulness of these models, organizations must augment them with first-party data – typically via a process called RAG (retrieval augmented generation). Today, this first-party data mostly lives in two types of data repositories.
Here’s how Cloudera makes it possible: One unified system: Cloudera’s open data lakehouse consolidates all critical log data into one system. Whether they need to query data from today or from years past, the system scales up or down to meet their needs.
As the magnitude and role of data in society has changed, so have the tools for dealing with it. While a +3500 year data retention capability for data stored on clay tablets is impressive, the access latency and forward compatibility of clay tablets fall a little short. Book a Demo!
So, instead of replacing or rebuilding the existing infrastructure, you add a new, ML-powered abstraction layer on top of the underlying data sources, enabling various users to access and manage the information they need without duplication. Data fabric architecture example. Unified dataaccess. Data and metadata.
Data Governance and Security By defining data models, organizations can establish policies, access controls, and security measures to protect sensitive data. Data models can also facilitate compliance with regulations and ensure proper data handling and protection. Want to learn more about data governance?
In an identity/access management application, it’s the relationships between roles and their privileges that matters most. If you’ve found yourself needing to write very large JOIN statements or dealing with long paths through your data, then you are probably facing a graph problem. Relationships act like verbs in your graph.
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. Traditional data warehouse platform architecture. Key features of a data lakehouse. Unstructured and streaming data support.
Understanding data warehouses A data warehouse is a consolidated storage unit and processing hub for your data. Teams using a data warehouse usually leverage SQL queries for analytics use cases. This same structure aids in maintaining data quality and simplifies how users interact with and understand the data.
Netflix Scheduler is built on top of Meson which is a general purpose workflow orchestration and scheduling framework to execute and manage the lifecycle of the data workflow. Bulldozer makes data warehouse tables more accessible to different microservices and reduces each individual team’s burden to build their own solutions.
Read More: AI Data Platform: Key Requirements for Fueling AI Initiatives How Data Engineering Enables AI Data engineering is the backbone of AI’s potential to transform industries , offering the essential infrastructure that powers AI algorithms.
These are key in nearly all data pipelines, allowing for efficient data storage and easier querying and information extraction. They are designed to handle the challenges of big data like size, speed, and structure. Data engineers often face a plethora of choices.
Instead of relying on traditional hierarchical structures and predefined schemas, as in the case of data warehouses, a data lake utilizes a flat architecture. This structure is made efficient by data engineering practices that include object storage. Watch our video explaining how data engineering works.
Data integration with ETL has evolved from structureddata stores with high computing costs to natural state storage with read operation alterations thanks to the agility of the cloud. Data integration with ETL has changed in the last three decades. This ensures that companies' data is always protected and secure.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Over the past few years, data lakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind. Who has access to it?
A combination of structured and semi structureddata can be used for analysis and loaded into the cloud database without the need of transforming into a fixed relational scheme first. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
Traditionally, after being stored in a data lake, raw data was then often moved to various destinations like a data warehouse for further processing, analysis, and consumption. Databricks Data Catalog and AWS Lake Formation are examples in this vein. AWS is one of the most popular data lake vendors.
This means that a data warehouse is a collection of technologies and components that are used to store data for some strategic use. Data is collected and stored in data warehouses from multiple sources to provide insights into business data. Data from data warehouses is queried using SQL.
Data-driven organizations generate, collect, and store vast amounts of data. To effectively manage and analyze this data, data engineering teams must navigate a wide range of challenges, including dataaccess, security, compliance, and data observability. Automating self-service access.
Does not have a dedicated metadata database. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Hadoop technology is the buzz word these days but most of the IT professionals still are not aware of the key components that comprise the Hadoop Ecosystem.
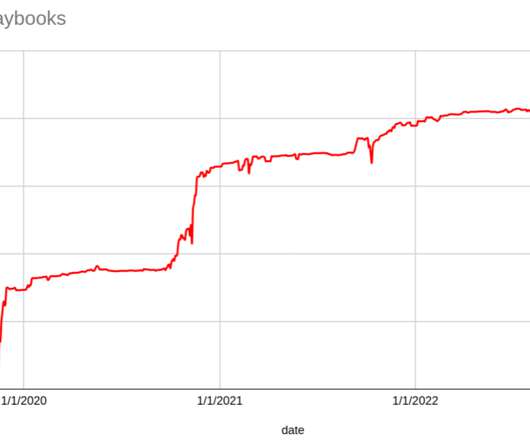
This structure allows all stakeholders involved in incident response to clearly understand the executed actions and target state of the system to expect. Lastly, by having playbooks in a single location, our Incident Responders and Incident Commanders have easy access to all available emergency procedures in a consistent format.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content