This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making dataaccessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. What are data logs?
Enabling Stakeholder dataaccess with RAGs 3.1. Loading: Read rawdata and convert them into LlamaIndex data structures 3.2.1. Read data from structured and unstructured sources 3.2.2. Transform data into LlamaIndex data structures 3.3. Introduction 2. Set up 3.1.1. Pre-requisite 3.1.2.
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. That needs to be done because rawdata is painful to read and work with. Knowledge of popular big data tools like Apache Spark, Apache Hadoop, etc.
(Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. A data lake!
Speaker: Donna Laquidara-Carr, PhD, LEED AP, Industry Insights Research Director at Dodge Construction Network
However, the sheer volume of tools and the complexity of leveraging their data effectively can be daunting. That’s where data-driven construction comes in. It integrates these digital solutions into everyday workflows, turning rawdata into actionable insights.
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ?
For years, Snowflake has been laser-focused on reducing these complexities, designing a platform that streamlines organizational workflows and empowers data teams to concentrate on what truly matters: driving innovation.
For data analysts and engineers, the journey from rawdata to actionable business insights for business users is never as simple as it sounds. The semantic layer is a critical component in this process, serving as the bridge between complex data sources and the business logic required for informed decision-making.
For example: An AWS customer using Cloudera for hybrid workloads can now extend analytics workflows to Snowflake, gaining deeper insights without moving data across infrastructures. Or now customers can combine Cloudera’s rawdata processing and Snowflake’s analytical capabilities to build efficient AI/ML pipelines.
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights.
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. Additionally, we launched cross-region inference , allowing you to access preferred LLMs even if they aren’t available in your primary region.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. As always, I have not been paid to write about this company and have no affiliation with it – see more in my ethics statement. Funding and team size The company got started thanks to a €150K ($165K) EU grant.
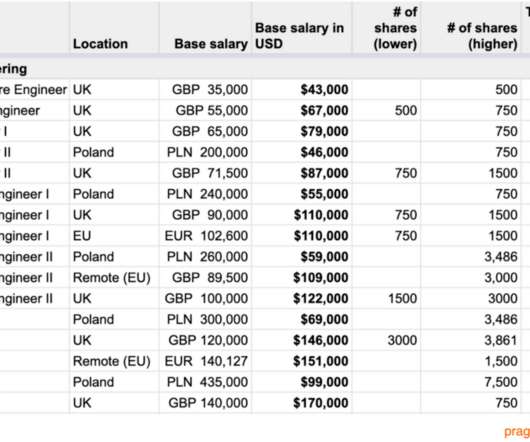
In this week’s The Scoop, I analyzed this information and dissected it, going well beyond the rawdata. Here are a few details from the data points, focusing on software engineering compensation. How can you use this data in budgeting, and what are the caveats to be aware of?
Using familiar SQL as Athena queries on rawdata stored in S3 is easy; that is an important point, and you will explore real-world examples related to this in the latter part of the blog. It is compatible with Amazon S3 when it comes to data storage data as there is no requirement for any other storage mechanism to run the queries.
However, the modern data ecosystem encompasses a mix of unstructured and semi-structured data—spanning text, images, videos, IoT streams, and more—these legacy systems fall short in terms of scalability, flexibility, and cost efficiency. That’s where data lakes come in. Tools such as SQL engines, BI tools (e.g.,
This blog covers the top ten AWS data engineering tools popular among data engineers across the big data industry. Additionally, engineers can build schemas and tables, import data visually, and explore database objects using Query Editor v2. Get Started with Learning Python for Data Engineering Now !
By using the Parquet-based open-format storage layer, Delta Lake is able to solve the shortcomings of data lakes and unlock the full potential of a company's data. This helps data scientists and business analysts access and analyze all the data at their disposal. How to access Delta lake on Azure Databricks?
We will now describe the difference between these three different career titles, so you get a better understanding of them: Data Engineer A data engineer is a person who builds architecture for data storage. They can store large amounts of data in data processing systems and convert rawdata into a usable format.
Infrastructure layout Diagram illustrating the data flow between each component of the infrastructure Prerequisites Before you embark on this integration, ensure you have the following set up: Access to a Vantage instance: If you need a test instance of Vantage, you can provision one for free Python 3.10 dbt-core dagster==1.7.9
Google Analytics, a tool widely used by marketers, provides invaluable insights into website performance, user behavior and critical analytic data that helps marketers understand the customer journey and improve marketing ROI. In the case of rawdata, it replicates it directly from the BigQuery storage layer.
Today, data engineers are constantly dealing with a flood of information and the challenge of turning it into something useful. The journey from rawdata to meaningful insights is no walk in the park. It requires a skillful blend of data engineering expertise and the strategic use of tools designed to streamline this process.
OneLake Data Lake OneLake provides a centralized data repository and is the fundamental storage layer of Microsoft Fabric. It preserves security and governance while facilitating smooth dataaccess across all Fabric services. Transform Your Data Analytics with Microsoft Fabric!
Thats why were excited to announce the launch of Analyst Studio , the collaborative creator space where data teams can come together to transform rawdata into actionable insights. Now you can join data from multiple sources and directly manipulate raw datamaximizing flexibility and enabling quick iterations.
But this data is not that easy to manage since a lot of the data that we produce today is unstructured. In fact, 95% of organizations acknowledge the need to manage unstructured rawdata since it is challenging and expensive to manage and analyze, which makes it a major concern for most businesses.
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Significance of Data Preparation Process in Machine Learning Data Preparation Steps for Machine Learning Projects Machine Learning Data Preparation Tools Project Ideas for Data Preparation in Machine Learning FAQs on Preparing Data for Machine Learning What is Data Preparation for Machine Learning?
Independent, Isolated Data Processing Resources: Independence and isolation of data processing resources within the pipeline ensure resilience and reliability, minimizing the risk of failures or disruptions and preserving data integrity and operational stability.
Security AWS offers various security features companies can use to protect their data, such as encryption, access controls, and network isolation. This ensures that companies' data is always protected and secure. AWS provides various relational and non-relational data stores that act as data sources in an ETL pipeline.
Load- The pipeline copies data from the source into the destination system, which could be a data warehouse or a data lake. Transform- Organizations routinely transform rawdata in various ways and use it with multiple tools or business processes. Scalability ELT can be highly adaptable when using rawdata.
Today, businesses use traditional data warehouses to centralize massive amounts of rawdata from business operations. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties. Organizations use cloud data warehouses like AWS Redshift to organize such information at scale.
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. Accessing this information lets you engage in profitable stocks and ventures and make better financial decisions.
The source function, on the other hand, is used to reference external data sources that are not built or transformed by DBT itself but are brought into the DBT project from external systems, such as rawdata in a data warehouse.
View full parsed rawdata") print("2. The PDF I’m using is publicly accessible, and you can download it using the link. View full parsed rawdata 2. print("What would you like to do?") Extract full plain text") print("3. Get LangChain documents (no chunking)") print("4. Show document metadata") print("6.
The Data Cleaning Pipeline Let's assume we have clients sending hotel booking demand data from multiple data sources to a scalable storage solution. Before analyzing the rawdata, we need to clean it and then load it into a database where it can be accessed for analysis. Our Airflow DAG will have two tasks.
Emily is an experienced big data professional in a multinational corporation. As she deals with vast amounts of data from multiple sources, Emily seeks a solution to transform this rawdata into valuable insights. dbt and Snowflake: Building the Future of Data Engineering Together."
Key Features: Along with direct connections to Google Cloud's streaming services like Dataflow, BigQuery includes built-in streaming capabilities that instantly ingest streaming data and make it readily accessible for querying. Get Started with Learning Python for Data Engineering Now !
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace. PREVIOUS NEXT <
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
They often deal with big data (structured, unstructured, and semi-structured) to generate reports to identify patterns, gain valuable insights, and produce visualizations easily deciphered by stakeholders and non-technical business users. Creating dashboards and tools for business users based on analysis by data analysts and data scientists.
Your SQL skills as a data engineer are crucial for data modeling and analytics tasks. Making dataaccessible for querying is a common task for data engineers. Collecting the rawdata, cleaning it, modeling it, and letting their end users access the clean data are all part of this process.
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata. What is a Big Data Pipeline?
In this edition, discover how Houssam Fahs, CEO and Co-founder of KAWA Analytics , is on a mission to revolutionize the creation of data-driven applications with a cutting-edge, AI-native platform built for scalability. The drive to democratize powerful tools and redefine how enterprises engage with data motivates me every day.
Feature Store : Feature stores are used to store variations on the feature set leveraged for machine learning models t hat multiple teams can access. Focus on performing a preliminary analysis of the data using Python, leveraging pandas profiling and sweetviz. The source code for inspiration can be found here.
Building data pipelines is a core skill for data engineers and data scientists as it helps them transform rawdata into actionable insights. You’ll walk through each stage of the data processing workflow, similar to what’s used in production-grade systems. b64encode(creds.encode()).decode()
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content