This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Lucas’ story is shared by lots of beginner Scala developers, which is why I wanted to post it here on the blog. I’ve watched thousands of developers learn Scala from scratch, and, like Lucas, they love it! If you want to learn Scala well and fast, take a look at my Scala Essentials course at Rock the JVM. sum > 8 ).
In this iteration, we’ll be integrating Redis to keep track of the users and rooms and we’ll also be persisting messages in Postgres so that new users can have access to previous conversations. Next, we’ll create a user.scala file in the following path, src/main/scala/rockthejvm/websockets/domain. cond ( ( value. cond ( ( value.
Access to the data lake and raw data streams is self-provisioned which allows us to work in parallel, and to scale to support multiple protocols (e.g., Accessing on-chain data requires setting up nodes, which turns out to be not as easy as we thought, due to overcoming different quirks we encountered or data discrepancies between versions.
Each dataset needs to be securely stored with minimal access granted to ensure they are used appropriately and can easily be located and disposed of when necessary. Consequently, access control mechanisms also need to scale constantly to handle the ever-increasing diversification.
If you want to master the Typelevel Scala libraries (including Http4s) with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. One Time Password (OTP) A One Time Password is a form of authentication that is used to grant access to a single login session or transaction. SHA256 ) }).
Setting Up Let’s create a new Scala 3 project and add the following to your build.sbt file. The UDP Server Create Fs2Udp.scala in the following path, src/main/scala/com/rockthejvm/fs2Udp/Fs2Udp.scala and add the following code: package com.rockthejvm.fs2Udp import cats.effect. val scala3Version = "3.3.1" lazy val root = project.
Scala is not officially supported at the moment however the ScalaPB library provides a good wrapper around the official gRPC Java implementation, it provides an easy API that enables translation of Protocol Buffers to Scala case classes with support for Scala3, Scala.js, and Java Interoperability. Setting Up. in ( file ( "protobuf" )).
However, this ability to remotely run client applications written in any supported language (Scala, Python) appeared only in Spark 3.4. In any case, all client applications use the same Scala code to initialize SparkSession, which operates depending on the run mode. getOrCreate() // If the client application uses your Scala code (e.g.,
Antonio is an alumnus of Rock the JVM, now a senior Scala developer with his own contributions to Scala libraries and junior devs under his mentorship. Which brings us to this article: Antonio originally started from my Sudoku backtracking article and built a Scala CLI tutorial for the juniors he’s mentoring.
The authorization server provides the user with a prompt, asking the user to grant app1 access to app2 with a list of permissions. The authorization server on app2 will respond with a token id and an access token app1 can now request the user’s information from app2’s API using the access token. Setting Up.
This typically involved a lot of coding with Java, Scala or similar technologies. To summarize, the addition of the Eventador technology and team to Cloudera will enable our customers to democratize cross-organizational access to real-time data. Risk management and real-time fraud analysis for IT and finance teams.
Accessing the necessary resources from cloud providers demands careful planning and up to month-long wait times due to the high demand for GPUs. To expand the capabilities of the Snowflake engine beyond SQL-based workloads, Snowflake launched Snowpark , which added support for Python, Java and Scala inside virtual warehouse compute.
A large number of our data users employ SparkSQL, pyspark, and Scala. Then we’ll segue into the Scala and R use cases. Currently supported workflow RECIPEs are: spark-sql, pyspark, scala and sparklyr. scala-workflow ? ??? It solidifies different recipes or repeatable templates for data extraction. pyspark-workflow ? ???
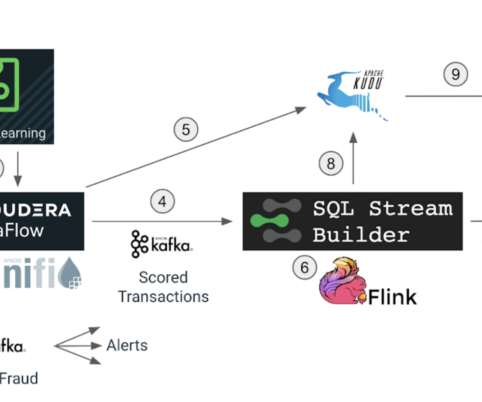
Their flagship product, SQL Stream Builder, made access to real-time data streams easily possible with just SQL (Structured Query Language). They no longer have to depend on any skilled Java or Scala developers to write special programs to gain access to such data streams. . SQL Stream Builder continuously runs SQL via Flink.
Http4s is one of the most powerful libraries in the Scala ecosystem, and it’s part of the Typelevel stack. If you want to master the Typelevel Scala libraries with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. by Herbert Kateu Hey, it’s Daniel here. val scala3Version = "3.2.2"
Http4s is one of the most powerful libraries in the Scala ecosystem, and it’s part of the Typelevel stack. If you want to master the Typelevel Scala libraries with real-life practice, check out the Typelevel Rite of Passage course, a full-stack project-based course. by Herbert Kateu Hey, it’s Daniel here. val scala3Version = "3.2.2"
But what if the script does not exist in the given path, or what if it existed initially but then Alice let Bob access her home directory and he accidentally deleted it? It could be a JAR compiled from Scala, a Python script or module, or a simple SQL file. scala-workflow ??? Example: 0 0 * * MON /home/alice/backup.sh
Contrast this with the skills honed over decades for gaining access, building data warehouses, performing ETL, creating reports and/or applications using structured query language (SQL). Organizational Access. This data engineering skill set typically consists of Java or Scala programming skills mated with deep DevOps acumen.
Snowpark is the set of libraries and runtimes that enables data engineers, data scientists and developers to build data engineering pipelines, ML workflows, and data applications in Python, Java, and Scala. With this announcement, External Access is in public preview on Amazon Web Services (AWS) regions.
REST APIs provide a simple and uniform way to access data and not only through URLs, across the web. Play Framework “makes it easy to build web applications with Java & Scala”, as it is stated on their site, and it’s true. In this article we will try to develop a basic skeleton for a REST API using Play and Scala.
If you’re new to Snowpark, this is Snowflake ’s set of libraries and runtimes that securely deploy and process non-SQL code including Python, Java, and Scala. ThoughtSpot is taking Snowpark use cases to the next level with generative AI, connecting the dots between ML-powered insights and business action. Here’s how it works.
The backend of Quala is called “tinbox” and is written in Scala , using many type-intensive libraries such as Shapeless , Circe , Grafter , and http4s/rho. One important design goal behind these libraries is to reduce boilerplate by letting the Scala compiler generate as much ceremony code as possible. versus Hydra. compiler is used!
CDE supports Scala, Java, and Python jobs. All the job management features available in the UI uses a consistent set of APIs that are accessible through a CLI and REST allowing for seamless integration with existing CI/CD workflows and 3rd party tools.
These speeds up the development process by facilitating accessible communication and reusability of code. Remote Access Solutions As remote work becomes more prevalent, collaboration for DevOps across diverse platforms and geographies becomes challenging.
Previous posts have looked at Algebraic Data Types with Java Variance, Phantom and Existential types in Java and Scala Intersection and Union Types with Java and Scala One of the difficult things for modern programming languages to get right is around providing flexibility when it comes to expressing complex relationships.
cache, local space) 8 It supports multiple languages such as Java, Scala, R, and Python. RDDs can include any kind of Python, Java, or Scala object, including classes that the user has specified. DB/Models would be accessed via any other streaming application, which in turn is using Kafka streams here.
In medicine, lower sequencing costs and improved clinical access to NGS technology has been shown to increase diagnostic yield for a range of diseases, from relatively well-understood Mendelian disorders, including muscular dystrophy and epilepsy , to rare diseases such as Alagille syndrome.
However, in the typical enterprise, only a small team has the core skills needed to gain access and create value from streams of data. This data engineering skillset typically consists of Java or Scala programming skills mated with deep DevOps acumen. A rare breed.
What are the options for access control when running queries against the data stored in S3? What are some of the most interesting or unexpected uses of Chaos Search and access to large amounts of historical log information that you have seen? What are the options for access control when running queries against the data stored in S3?
Apache HBase is an effective data storage system for many workflows but accessing this data specifically through Python can be a struggle. Python is used extensively among Data Engineers and Data Scientists to solve all sorts of problems from ETL/ELT pipelines to building machine learning models. Restart Region Servers.
By using AWS Glue Data Catalog, multiple systems can store and access metadata to manage data in data silos. You can use the Data Catalog, AWS Identity and Access Management rules, and Lake Formation to restrict access to the databases and tables. The limitation here is we can attach the trigger to only 2 crawlers.
Spark offers over 80 high-level operators that make it easy to build parallel apps and one can use it interactively from the Scala, Python, R, and SQL shells. The core is the distributed execution engine and the Java, Scala, and Python APIs offer a platform for distributed ETL application development.
ScalaScala has become one of the most popular languages for AI and data science use cases. Because it is statically typed and object-oriented, Scala has often been considered a hybrid language used for data science between object-oriented languages like Java and functional ones like Haskell or Lisp.
Links Quilt Data GitHub Jobs Reproducible Data Dependencies in Jupyter Reproducible Machine Learning with Jupyter and Quilt Allen Institute: Programmatic Data Access with Quilt Quilt Example: MissingNo Oracle Pandas Jupyter Ycombinator Data.World Podcast Episode with CTO Bryon Jacob Kaggle Parquet HDF5 Arrow PySpark Excel Scala Binder Merkle Tree Allen (..)
Enter the new Event Tables feature, which helps developers and data engineers easily instrument their code to capture and analyze logs and traces for all languages: Java, Scala, JavaScript, Python and Snowflake Scripting. But previously, developers didn’t have a centralized, straightforward way to capture application logs and traces.
The application is written in Scala and using a Java High Level REST Client, which got deprecated in Elasticsearch 7.15.0 Of course, a lot of these files are the configs and tests and test resources, so the actual number of Scala files is much lower. But still, it's a lot of code, and a lot of it is dealing with Elasticsearch.
In this blog we will explore how we can use Apache Flink to get insights from data at a lightning-fast speed, and we will use Cloudera SQL Stream Builder GUI to easily create streaming jobs using only SQL language (no Java/Scala coding required). It provides flexible and expressive APIs for Java and Scala. Use case recap.
External Network Access (PrPr) – Allows users to seamlessly connect to external endpoints from their Snowpark code (UDFs/UDTFs and Stored procedures) while maintaining high security and governance. Native Git Integration (PrPr Soon) – Snowflake now supports native integration with git repos!
But even without the catalog, Iceberg Tables are still accessible if the user directly points at appropriate file locations. This new Snowflake catalog is ideal for accessing Iceberg Tables managed and written by Snowflake’s engine. First, let’s see what tables are available to query.
For use cases involving files like PDF documents, images, videos, and audio files, you can also now use Snowpark for Python and Scala (generally available) to dynamically process any type of file. For any features above in private preview, please contact your Snowflake account manager to apply for access.
On top of that you’ll get access to Analytics Academy for the educational resources you need to become an expert in data analytics for measuring product-market fit. On top of that you’ll get access to Analytics Academy for the educational resources you need to become an expert in data analytics for measuring product-market fit.
With their open-source foundation, fixed pricing, and unlimited volume, they are enterprise ready, but accessible to everyone. Go to dataengineeringpodcast.com/rudder to request a demo and get one free month of access to the hosted platform along with a free t-shirt.
Scala or Java), this naming convention is probably second nature to you. The syntax is quite similar to many other languages (identical to Scala for example). This feature is called templating or interpolation (a feature borrowed from Scala). Values, Variables, and Types What’s programming without variables? Nothing fancy.
Data scientists require on-demand access to data, powerful processing infrastructure, and multiple tools and libraries for development and experimentation. With Cloudera Data Science Workbench, data scientists can: Use R, Python, or Scala along with the scale-out processing capabilities of Apache Spark 2.X What is CDSW? What is CDSW?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content