This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
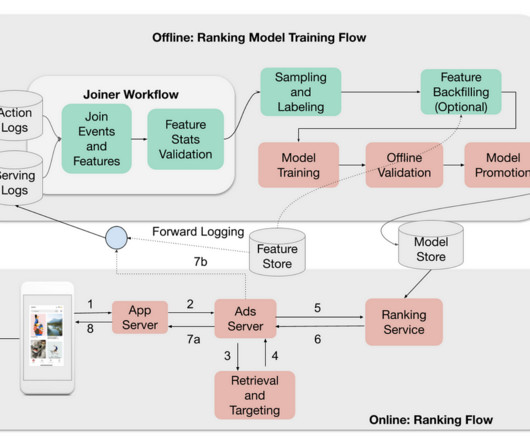
Modern IT environments require comprehensive data for successful AIOps, that includes incorporating data from legacy systems like IBM i and IBM Z into ITOps platforms. AIOps presents enormous promise, but many organizations face hurdles in its implementation: Complex ecosystems made of multiple, fragmented systems that lack interoperability.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products. Hack, C++, Python, etc.)
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. and hand-rolled C -code.
From Sella’s status page : “Following the installation of an update to the operating system and related firmware which led to an unstable situation. Still, I’m puzzled by how long the system has been down. If it was an update to Oracle, or to the operating system, then why not roll back the update?
The name comes from the concept of “spare cores:” machines currently unused, which can be reclaimed at any time, that cloud providers tend to offer at a steep discount to keep server utilization high. The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. Tech stack.
Responsible for building and maintaining developer tools so the programmer and copilot can do their jobs better; such as improving editors, building better debugging functionality, creating utility tools and macros, etc. Brooks discusses software in the context of producing operating systems, pre-internet. The tester.
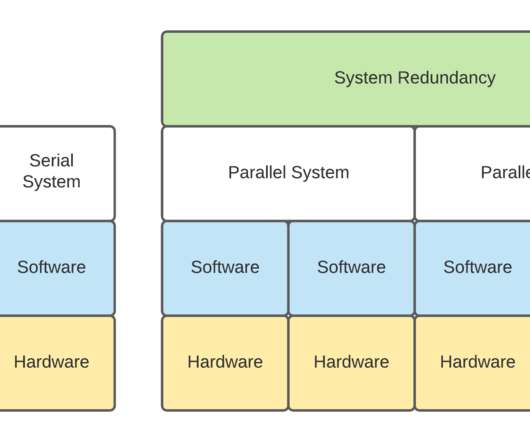
In Part 1, the discussion is related to: Serial and Parallel Systems Reliability as a concept, Kafka Clusters with and without Co-Located Apache Zookeeper, and Kafka Clusters deployed on VMs. . Serial and Parallel Systems Reliability . Serial Systems Reliability. Serial Systems Reliability.
Each dataset needs to be securely stored with minimal access granted to ensure they are used appropriately and can easily be located and disposed of when necessary. Consequently, access control mechanisms also need to scale constantly to handle the ever-increasing diversification.
However, this category requires near-immediate access to the current count at low latencies, all while keeping infrastructure costs to a minimum. Failures in a distributed system are a given, and having the ability to safely retry requests enhances the reliability of the service.
An operating system that allows multiple programmes to run simultaneously on a single processor machine is known as a multiprogramming operating system. This keeps the system from idly waiting for the I/O work to finish, wasting CPU time. We'll explain the multiprogramming operating system in this article.
I have comprehensively analyzed the area of physical security, particularly the ongoing discussion surrounding fail safe vs fail-safe secure electric strike locking systems. On the other hand, fail-secure systems focus on maintaining continuous security, keeping doors locked even in difficult conditions to protect assets.
Our modern approach accelerates digital transformation, connects previously siloed systems, increases operational efficiencies, and can deliver better outcomes for constituents verifying digital credentials. Snowflake’s Data Cloud was crucial in utilizing data to capture real-time information and effectively allocate funds.
Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. With data volumes skyrocketing, and complexities increasing in variety and platforms, traditional centralized data management systems often struggle to keep up.
High-quality, accessible and well-governed data enables organizations to realize the efficiency and productivity gains executives seek. By establishing data standardization, accessibility, and integration, partners help clients overcome the barriers that often derail AI initiatives.
I have confirmed this through talking with software engineers there, who told me there’s a top-down mandate to utilize AI wherever possible in an effort to drive more efficiency, and product improvements. With clever-enough probing, this system prompt can be revealed. ” What is the system prompt for Klarna’s bot?
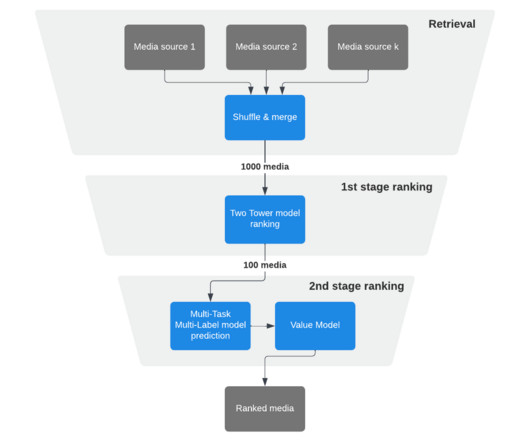
Explore is one of the largest recommendation systems on Instagram. Using more advanced machine learning models, like Two Towers neural networks, we’ve been able to make the Explore recommendation system even more scalable and flexible. locally popular media), which further contributes to system scalability.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
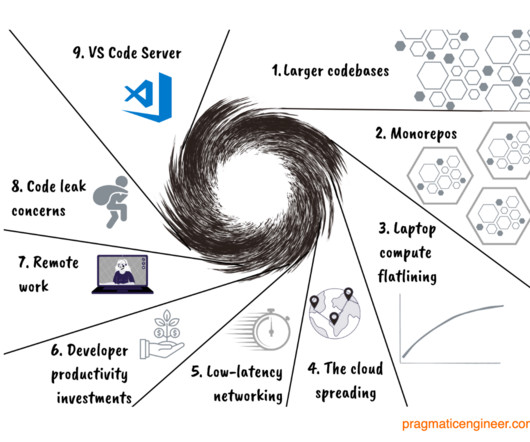
With remote work, engineers spend more time on video calls, which utilizes laptop resources like CPU, memory, and more. With full-remote work, the risk is higher that someone other than the employee accesses the codebase. Full subscribers can access a list with links here. Remote work. Open source VS Code Server.
This has been forcing data center engineers to meet their storage performance needs by shifting hot (frequently accessed) data to a TLC flash tier or by overprovisioning storage. As discussed above, our QLC systems are very high in density. In other words, the bandwidth per TB for HDDs has been dropping.
The author emphasizes the importance of mastering state management, understanding "local first" data processing (prioritizing single-node solutions before distributed systems), and leveraging an asset graph approach for data pipelines. I honestly don’t have a solid answer, but this blog is an excellent overview of upskilling.
Optimize performance and cost with a broader range of model options Cortex AI provides easy access to industry-leading models via LLM functions or REST APIs, enabling you to focus on driving generative AI innovations. We offer a broad selection of models in various sizes, context window lengths and language supports.
Many of these projects are under constant development by dedicated teams with their own business goals and development best practices, such as the system that supports our content decision makers , or the system that ranks which language subtitles are most valuable for a specific piece ofcontent.
This elasticity allows data pipelines to scale up or down as needed, optimizing resource utilization and cost efficiency. Utilize Cloud-Native Tools: Leverage cloud-native data pipeline tools like Ascend to build and orchestrate scalable workflows. Regularly review usage patterns and adjust cloud resource allocation as needed.
In particular, our machine learning powered ads ranking systems are trying to understand users’ engagement and conversion intent and promote the right ads to the right user at the right time. Specifically, such discrepancies unfold into the following scenarios: Bug-free scenario : Our ads ranking system is working bug-free.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance.
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Support Data Engineering Podcast Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
But there’s no “one size fits all” strategy when it comes to deciding the right balance between utilizing the cloud and operating your infrastructure on-premises. What are the use cases where the company already utilizes public cloud? Agoda utilizes Akamai as its CDN vendor. Agoda in numbers Agoda lists 3.6M
Ingest data more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
This includes accelerating data access and, crucially, enriching internal data with external information. Unlocking Value with Pre-Linked Datasets Today, youre able to access You can pick the best data for your needs, without being limited by a specific vendors ID system or fearing the complexity of managing all the overhead.
This is crucial for applications that require up-to-date information, such as fraud detection systems or recommendation engines. Data Integration : By capturing changes, CDC facilitates seamless data integration between different systems. Finally, the control plane emits enriched metrics to enable effective monitoring of the system.
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. We can utilize this prompt to give the model more context on possible selections. Creating a Training Prompt.
AI agents, autonomous systems that perform tasks using AI, can enhance business productivity by handling complex, multi-step operations in minutes. Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. text, audio) and structured (e.g.,
impactdatasummit.com Uber: Streamlining Financial Precision - Uber’s Advanced Settlement Accounting System Possibly one of the complicated pipelines to build is the Financial reconciliation engine. Wix's systemutilizes over 200 models daily, necessitating a scalable and robust solution. What are you waiting for?
Decoders create the most statistically likely output sequence by utilizing this self-attention mechanism in conjunction with the encoders’ embeddings. It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks.
DeepSeek development involves a unique training recipe that generates a large dataset of long chain-of-thought reasoning examples, utilizes an interim high-quality reasoning model, and employs large-scale reinforcement learning (RL). Many articles explain how DeepSeek works, and I found the illustrated example much simpler to understand.
Privacy and access management within data infrastructure is not just a best practice; it's a necessity. Robust privacy and access management protocols are crucial for GDPR compliance, protecting sensitive information, and maintaining user trust. For example, GDPR and HIPAA require strict access controls to protect sensitive data.
Kafka is designed to be a black box to collect all kinds of data, so Kafka doesn't have built-in schema and schema enforcement; this is the biggest problem when integrating with schematized systems like Lakehouse. This capability, termed Union Read, allows both layers to work in tandem for highly efficient and accurate data access.
We focused on building end-to-end AI systems with a major emphasis on researcher and developer experience and productivity. With this in mind, we built one cluster with a remote direct memory access (RDMA) over converged Ethernet (RoCE) network fabric solution based on the Arista 7800 with Wedge400 and Minipack2 OCP rack switches.
As this is rolled out, security-conscious users who utilize the verify security code page will notice this verification process occurs quickly and automatically. This system is a new service provided by WhatsApp that relies on public auditing to verify the end-to-end encryption status of personal conversations.
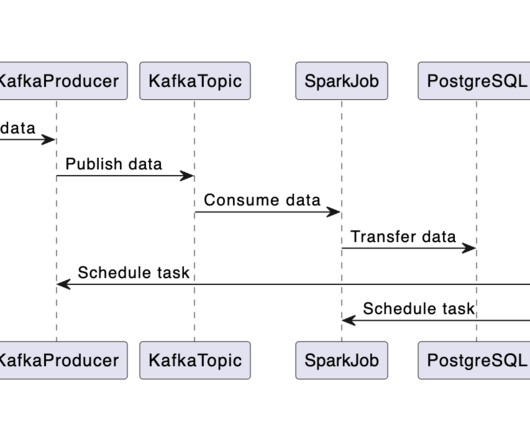
Ideal for those new to data systems or language model applications, this project is structured into two segments: This initial article guides you through constructing a data pipeline utilizing Kafka for streaming, Airflow for orchestration, Spark for data transformation, and PostgreSQL for storage. You can also leave the port at 5432.
What are the other systems that feed into and rely on the Trino/Iceberg service? what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? Want to see Starburst in action? Want to see Starburst in action?
Top Mobile Security Threats Cybercriminals target mobile devices on multiple fronts by exploiting vulnerabilities in mobile operating systems, malicious applications, and network infrastructures. Operating System and App Vulnerabilities No operating system is immune to flaws.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content