This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many of our customers — from Marriott to AT&T — start their journey with the Snowflake AI Data Cloud by migrating their data warehousing workloads to the platform. Today we’re focusing on customers who migrated from a cloud datawarehouse to Snowflake and some of the benefits they saw.
(Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today.
With a beautiful and streamlined user interface as well as access to curated AI/BI Genie spaces, Dashboards and Databricks Apps, Databricks One is designed to help business teams make smarter decisions without needing to be expert technical practitioners. The full Databricks One experience will enter beta later this summer.
Whether you are a data engineer, BI engineer , data analyst, or an ETL developer , understanding various ETL use cases and applications can help you make the most of your data by unleashing the power and capabilities of ETL in your organization. You have probably heard the saying, "data is the new oil".
Are you looking to choose the best cloud datawarehouse for your next big data project? This blog presents a detailed comparison of two of the very famous cloud warehouses - Redshift vs. BigQuery - to help you pick the right solution for your data warehousing needs. billion by 2028 from $21.18
The success or failure of a datawarehouse project depends on the time taken to identify the right technology. You are likely to be aware of the two pioneers in datawarehouse technologies, Snowflake and Google BigQuery , if you are a big data developer or simply a business owner who takes big data seriously.
The worldwide data warehousing market is expected to be worth more than $30 billion by 2025. Data warehousing and analytics will play a significant role in a company’s future growth and profitability. Table of Contents What is Data Warehousing? Why DataWarehouse Projects Fail? So let's get started!
Today, businesses use traditional datawarehouses to centralize massive amounts of raw data from business operations. Amazon Redshift is helping over 10000 customers with its unique features and data analytics properties. Table of Contents AWS Redshift DataWarehouse Architecture 1. Client Applications 2.
This helps data scientists and business analysts access and analyze all the data at their disposal. To gain a deeper understanding of Databricks Delta Lake and how it can revolutionize the way we approach data management, read on. But, with the advent of Big Data, datawarehouses alone could not meet the business needs.
AI Functions in SQL: Now Faster and Multi-Modal AI Functions enable users to easily access the power of generative AI directly from within SQL. GPU-powered AI workloads are now more accessible than ever, with this fully managed service eliminating the complexity of GPU management.
Hadoop offers an ideal platform for running BI applications, allowing businesses to uncover hidden patterns, identify trends, and make better decisions by analyzing stored data. For instance, e-commerce companies like Amazon and Flipkart use Hadoop-based BI solutions to gain insights into customer behavior, preferences, etc.,
The first step is to work on cleaning it and eliminating the unwanted information in the dataset so that data analysts and data scientists can use it for analysis. That needs to be done because raw data is painful to read and work with. Knowledge of popular big data tools like Apache Spark, Apache Hadoop, etc.
Data Analyst Skills of a Data Analyst Responsibilities of a Data Analyst Data Analyst Salary How to Transition from ETL Developer to Data Analyst? ETL is a process that involves data extraction, transformation, and loading from multiple sources to a datawarehouse, data lake, or another centralized data repository.
With the ever-growing focus on GenAI, many legacy BI tools have failed to invest in the analyst. By focusing solely on AI experiences for business teams, theyve alienated data teams, relegating analysts to disjointed tools and data silos. Need to perform advanced analytics ? No problem.
In this episode Zeeshan Qureshi and Michelle Ark share their experiences using DBT to manage the datawarehouse for Shopify. Datafold integrates with all major datawarehouses as well as frameworks such as Airflow & dbt and seamlessly plugs into CI workflows. What kinds of data sources are you working with?
The company wants to combine its sales, inventory, and customer data in order to facilitate real-time reporting and predictive analytics. Azure, Power BI, and Microsoft 365 are already widely used by ShopSmart, which is in line with Fabric’s integrated ecosystem. Next, we will see what Snowflake is What is Snowflake?
allow data engineers to acquire, analyze, process, and manage huge volumes of data simply and efficiently. Visualization tools like Tableau and Power BI allow data engineers to generate valuable insights and create interactive dashboards. It can also access structured and unstructured data from various sources.
As the demand for big data grows, an increasing number of businesses are turning to cloud datawarehouses. The cloud is the only platform to handle today's colossal data volumes because of its flexibility and scalability. Launched in 2014, Snowflake is one of the most popular cloud data solutions on the market.
Summary The datawarehouse has become the central component of the modern data stack. This is an interesting conversation about the importance of the datawarehouse and how it can be used beyond just internal analytics. How do you keep data up to date between the warehouse and downstream systems?
Step into the realm of data visualization with a comprehensive exploration of Power BI and Tableau. In a world where data is important, deciding between power bi vs tableau can change your path in analyzing things. We are talking about tableau vs power bi market share using features, interfaces and performance.
Data modeling enables the organization's departments to work together as a unit. It makes data more accessible. What does "data sparsity" imply? The number of blank cells in a database is known as data sparsity. In a data model, it describes the amount of data that is available for a specific dimension.
The Data Team Is Diverse—But Unified By the Need for Quality A modern data team is a mosaic of specialized roles. According to Gartner’s breakdown of analytics and data roles , data teams now span far beyond traditional data engineering and business intelligence (BI) analysts.
OneLake Data Lake OneLake provides a centralized data repository and is the fundamental storage layer of Microsoft Fabric. It preserves security and governance while facilitating smooth dataaccess across all Fabric services. Throughout the Fabric ecosystem, it facilitates smooth orchestration.
Azure Synapse and Databricks are two of the most popular datawarehouse platforms that offer features of ETL pipelines, machine learning , and enterprise data warehousing. But when it comes to choosing the two platforms, it is up to the organization to assess its data management needs.
Microsoft's Azure Synapse Analytics (formerly SQL DataWarehouse) is a cloud datawarehouse that combines data integration , data exploration, enterprise data warehousing, and big data analytics to offer a unified workspace for creating end-to-end analytics solutions.
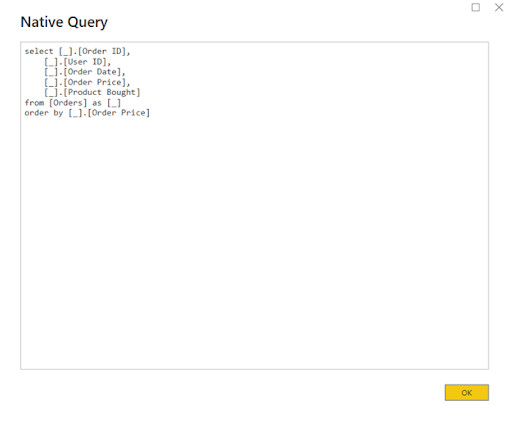
Power BI has a feature named Query Folding at the backend that can significantly improve your analysis. Understanding Query Folding How to Find If Your Power BIData Source Supports Query Folding? In other words, it acted as an input data source, taking much of the work on data processing and transferring within Power BI.
Underpinning Honeydew's approach is our shared vision that semantics should live in the datawarehouse. A shared truth starts with a shared language for people, for tools, for data transformation, says Honeydews Co-Founder and CEO, David Krakov. The tangible impact of Honeydew is clear. Just ask Pizza Hut.
Designing and managing data flows to support analytical initiatives is the core responsibility of a data engineer. The main challenge is creating a flow that merges data from multiple sources into a datawarehouse or shared location. It quickly integrates and transforms cloud-based data.
Want to know who is a business intelligence engineer, what does a business intelligence engineer do, and how these BI engineers turn mountains of data into actionable insights? Multiple career options are available in the business intelligence domain- BI analysts , BI engineers, BI developers, etc.
This fully managed service leverages Striim Cloud’s integration with the Microsoft Fabric stack for seamless data mirroring to Fabric DataWarehouse and Lake House. Microsoft Azure Fabric is an end-to-end analytics and data platform designed for enterprises that require a unified solution.
Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern datawarehouse solution, one that balances speed with platform cost management, performance, and reliability.
Decide the process of Data Extraction and transformation, either ELT or ETL (Our Next Blog) Transforming and cleaning data to improve data reliability and usage ability for other teams from Data Science or Data Analysis. Dealing With different data types like structured, semi-structured, and unstructured data.
The article advocates for a "shift left" approach to data processing, improving dataaccessibility, quality, and efficiency for operational and analytical use cases. link] Get Your Guide: From Snowflake to Databricks: Our cost-effective journey to a unified datawarehouse.
Here's an overview of the key components within Microsoft Fabric: Data Engineering The Data Engineering component provides a top-tier Spark platform with intuitive authoring tools that enable data engineers to conduct large-scale data transformations and democratize dataaccess through the lakehouse.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn raw data into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace. What is Business Intelligence?
I'll speak about "How to build the data dream team" Let's jump onto the news. Ingredients of a DataWarehouse Going back to basics. Kovid wrote an article that tries to explain what are the ingredients of a datawarehouse. And he does it well. The end-game dataset.
The need for speed to use Hadoop for sentiment analysis and machine learning has fuelled the growth of hadoop based data stores like Kudu and adoption of faster databases like MemSQL and Exasol. 2) Big Data is no longer just Hadoop A common misconception is that Big Data and Hadoop are synonymous.
Summary Business intellingence has been chasing the promise of self-serve data for decades. As the capabilities of these systems has improved and become more accessible, the target of what self-serve means changes. Self-serve data exploration has been attempted in myriad ways over successive generations of BI and data platforms.
With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started.
With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started.
With a PostgreSQL-compatible interface, you can now work with real-time data using ANSI SQL including the ability to perform multi-way complex joins, which support stream-to-stream, stream-to-table, table-to-table, and more, all in standard SQL. Go to dataengineeringpodcast.com/materialize today and sign up for early access to get started.
Take advantage of old school databasetricks In the last 1015 years weve seen massive changes to the data industry, notably big data, parallel processing, cloud computing, datawarehouses, and new tools (lots and lots of newtools). Consequently, weve had to say goodbye to some things to make room for all this new stuff.
In MetaMap’s customer identity platform, MetaMap makes it available for its merchants to access real-time usage and verification metrics. Furthermore, it enables MetaMap’s customer success and data teams to address questions and issues related to the merchant usage metrics more quickly.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content