This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. feature on Facebook.
We expect that over the coming years, structured data is going to become heavily integrated into AI workflows and that dbt will play a key role in building and provisioning this data. We are committed to building the data control plane that enables AI to reliably access structured data from across your entire data lineage.
Analytics Engineers deliver these insights by establishing deep business and product partnerships; translating business challenges into solutions that unblock critical decisions; and designing, building, and maintaining end-to-end analytical systems. DJ acts as a central store where metric definitions can live and evolve.
These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. And then a wide variety of business intelligence (BI) tools popped up to provide last mile visibility with much easier end user access to insights housed in these DWs and data marts.
The Definitive Guide to Embedded Analytics is designed to answer any and all questions you have about the topic. We hope this guide will transform how you build value for your products with embedded analytics. Access the Definitive Guide for a one-stop-shop for planning your application’s future in data.
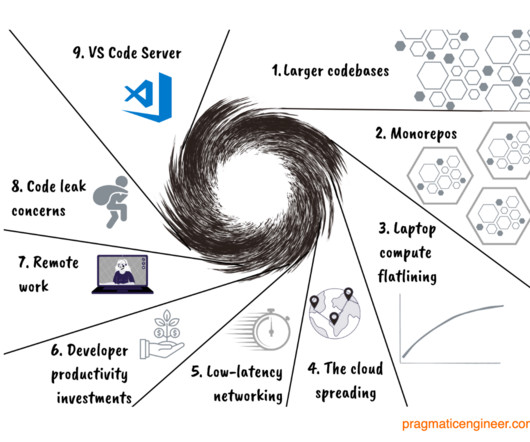
This means more repositories are needed, which are fast enough to build and work with, but which increase fragmentation. Executing a build is much slower while on a call. Plus, a CPU and memory-intensive build can impact the quality of the video call, and make the local environment much less responsive. Larger codebases.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. To start, can you share your definition of what constitutes a "Data Lakehouse"? Your first 30 days are free!
Buck2 is a from-scratch rewrite of Buck , a polyglot, monorepo build system that was developed and used at Meta (Facebook), and shares a few similarities with Bazel. As you may know, the Scalable Builds Group at Tweag has a strong interest in such scalable build systems. invoke build buck2 build //starlark-rust/starlark 6.
Cloudera, together with Octopai, will make it easier for organizations to better understand, access, and leverage all their data in their entire data estate – including data outside of Cloudera – to power the most robust data, analytics and AI applications.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Tune into our webinar Data Engineering Connect: Building Pipelines for Open Lakehouse on April 29, featuring two virtual demos and a hands-on lab.
Data clean rooms have emerged as the technology to meet this need, enabling interoperability where multiple parties can collaborate on and analyze sensitive data in a governed way without exposing direct access to the underlying data and business logic. Snowflake’s acquisition of Samooha is subject to customary closing conditions.
What if you could streamline your efforts while still building an architecture that best fits your business and technology needs? At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Here’s a closer look.
You will learn how to build up Kube-state-metrics system, pull and collect metrics, deploy a Prometheus server and metrics exporters, configure alerts with Alertmanager, and create Grafana dashboards. Monitoring had to be made more accessible, democratized and expanded to include additional stack tiers.
How to Build a Data Dashboard Prototype with Generative AI A book reading data visualization withVizro-AI This article is a tutorial that shows how to build a data dashboard to visualize book reading data taken from goodreads.com. Its still not complete and can definitely be extended and improved upon.
We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. Were upholding that by investing our vast engineering capabilities into building cutting-edge privacy technology. We believe that privacy drives product innovation.
Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. As data management grows increasingly complex, you need modern solutions that allow you to integrate and access your data seamlessly.
In this episode Balaji Ganesan shares how his experiences building and maintaining Ranger in previous roles helped him understand the needs of organizations and engineers as they define and evolve their data governance policies and practices. Can you describe what Privacera is and the story behind it?
He’s solved interesting engineering challenges along the way, too – like building observability for Amazon’s EC2 offering, and being one of the first engineers on Uber’s observability platform. The focus seemed to shift to: invent something new → build a service for it → ship it.
When scaling data science and ML workloads, organizations frequently encounter challenges in building large, robust production ML pipelines. Define an Entity: Define a Feature View: feature_df is a Snowpark DataFrame object containing your feature definition. Producers can create and modify Feature Views.
Summary A data catalog is a critical piece of infrastructure for any organization who wants to build analytics products, whether internal or external. While there are a number of platforms available for building that catalog, many of them are either difficult to deploy and integrate, or expensive to use at scale.
To help customers overcome these challenges, RudderStack and Snowflake recently launched Profiles , a new product that allows every data team to build a customer 360 directly in their Snowflake Data Cloud environment. Now teams can leverage their existing data engineering tools and workflows to build their customer 360.
Integrate data governance and data quality practices to create a seamless user experience and build trust in your data. These architectures have both emerged to accelerate the delivery of trusted data to users so that its actionable and accessible for informed decision-making.
Diagnosis: Customers may be unable to access Cloud resources in europe-west9-a Workaround: Customers can fail over to other zones.” I asked Google if europe-west9-a and europe-west9-c are in the same building, at least partially. Regional Spanner should have had one replica in each of the three buildings in the region.
A Step-by-Step Guide to Building an Effective Data Quality Strategy from Scratch How to build an interpretable data quality framework based on user expectations Photo by Rémi Müller on Unsplash As data engineers, we are (or should be) responsible for the quality of the data we provide. How much should we worry about data quality?
Thus, to facilitate our job it is possible to consolidate all the datasets into a single dataframe and create the “ city ” and “ weekday_or_weekend ” features, which definitely will be essential features to the model. Image 2— Starting the Databricks cluster. Source: The author.
Addressing the challenges of data-intensive apps Using the combined capabilities of Snowflake Native Apps and Snowpark Container Services, you can build sophisticated apps and deploy them to a customer’s account. All these platform functionalities allow for providers to build trust with their consumers when running inside Snowflake.
By focusing on these attributes, data engineers can build pipelines that not only meet current demands but are also prepared for future challenges. Each section will provide actionable insights and practical tips to help you build pipelines that are robust, efficient, and ready for whatever the future holds.
To safeguard sensitive information, compliance with frameworks like GDPR and HIPAA requires encryption, access control, and anonymization techniques. The AI Data Engineer: A Role Definition AI Data Engineers play a pivotal role in bridging the gap between traditional data engineering and the specialized needs of AI workflows.
Type-checkers validate these annotations, helping prevent bugs and improving IDE functions like autocomplete and jump-to-definition. Free-threaded Python (FTP) is an experimental build of CPython that allows multiple threads to interact with the VM in parallel. What is free-threaded Python ?
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. Go to dataengineeringpodcast.com/dagster today to get started. Your first 30 days are free! Data lakes are notoriously complex.
Such a log would build confidence that Glassdoor is a neutral platform which is only enforcing its own terms and conditions, and could validate this. However, there’s a definite and ongoing uptick since the mid-2021. Meanwhile, Amazon has announced Bedrock, but more than a month later not even its own developers have access.
Building a maintainable and modular LLM application stack with Hamilton in 13 minutes LLM Applications are dataflows, use a tool specifically designed to express them LLM stacks. Hamilton is great for describing any type of dataflow , which is exactly what you’re doing when building an LLM powered application. Image from pixabay.
It's supposed to make building smarter, faster, and more flexible data infrastructures a breeze. By bringing all the layers of the data stack together, TimeXtender helps you build data solutions up to 10 times faster and saves you 70-80% on costs. We feel your pain. It ends up being anything but that. We feel your pain.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Dagster offers a new approach to building and running data platforms and data pipelines. What are some of the useful clarifying/scoping questions to address when deciding the path to deployment for different definitions of "AI"?
Embedded Accessibility is a vision of buildingaccessible products by default. We can consider accessibility embedded when it no longer needs to be prioritised because it is already at the core of the delivery process. Our products will also be more accessible by default. Does this sound familiar?
As Per the Project Management Institute (PMI) definition, "Project" signifies "a temporary endeavor with a definite beginning and end." While it may look relatively simpler on the outer aspect of determining what outputs a project can have, several stacked deliverables may require definition En route to achieving the final output.
We’re excited to provide all Snowflake customers with the core building blocks needed to streamline development workflows, aligned with DevOps best practices, paving a seamless path to production. A simple pip install snowflake grants developers access, eliminating the need to juggle between SQL and Python or wrestle with cumbersome syntax.
Well, more specifically, LLaMA (Large Language Model Meta AI), along with other large language models (LLMs) that have suddenly become more open and accessible for everyday applications. And I would definitely agree that, in my mind at least, this will have a big, big impact on our world, perhaps even bigger than the internet.
We will explore the challenges we encounter and unveil how we are building a resilient solution that transforms these client-side impressions into a personalized content discovery experience for every Netflixviewer. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
Apache Nifi is a powerful tool to build data movement pipelines using a visual flow designer. Ultimately these challenges force NiFi teams to spend a lot of time on managing the cluster infrastructure instead of building new data flows which slows down use case adoption. The need for a cloud-native Apache NiFi service. and later).
This means that you can always know exactly where your data is stored and how it is accessed. This system is designed to provide a way for applications to access data stored on a remote server without having to copy the data to the local machine. This maintains order and hierarchy when accessing data from the etcd component.
By bringing governed data directly to end business users in a familiar and search-friendly BI solution like ThoughtSpot, you can democratize access to safe, reliable, self-service insights across your organization. Self service: Ensure there is a single, trusted definition of your data models across the business.
The reality is that business has always been defined by rapid change, and change, by definition, is always disruptive to something. This includes accelerating data access and, crucially, enriching internal data with external information. You can feel secure knowing that all data you access has met rigorous criteria on these fronts.
Dustin Dorsey and Cameron Cyr co-authored a practical guide to building your dbt project. In this episode they share their hard-won wisdom about how to build and scale your dbt projects. Summary The dbt project has become overwhelmingly popular across analytics and data engineering teams. Introducing RudderStack Profiles.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content