This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. capitalization).
What times of the day are busy in the area, and are roads accessible? Data enrichment helps provide a 360 o view which informs better decisions around insuring, purchasing, financing, customer targeting, and more. Together, data validation and enrichment form a powerful combination that delivers even bigger results for your business.
As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the raw data. Does it sound familiar?
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. In addition to this, they make sure that the data is always readily accessible to consumers.
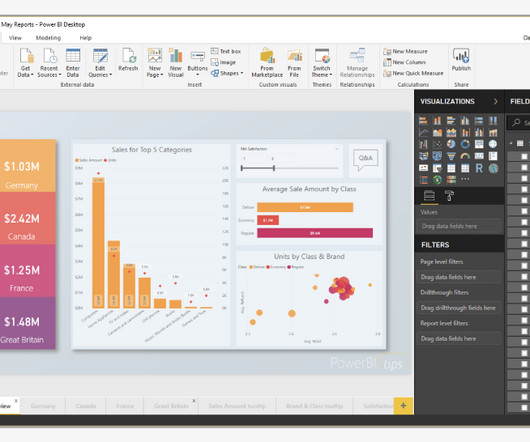
Power BI Desktop Power BI Desktop is free software that can be downloaded and installed to build reports by accessingdata easily without the need for advanced report designing or query skills to build a report. Multiple Data Sources Multiple Data Sources support various data sources like Excel, CSV, SQL Server, Web files, etc.
Data validation helps organizations maintain a high level of data quality by preventing errors and inconsistencies from entering the system. Datacleansing: This involves identifying and correcting errors or inaccuracies in the data. This can lead to more efficient decision-making and better overall performance.
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
Accelerated Decision-Making In today’s fast-paced business environment, where decisions need to be made quickly based on accurate information, having access to reliable and trustworthy data becomes crucial.
After cleansingdata from all devices, the events can be dynamically routed to new Kafka topics, each of which represents a single device type. That device type may be extracted from a field in the original sensor data. final KStream<String, Event>[] cleansedEvents = events // …some datacleansing….
Finally, you should continuously monitor and update your data quality rules to ensure they remain relevant and effective in maintaining data quality. DataCleansingDatacleansing, also known as data scrubbing or data cleaning, is the process of identifying and correcting errors, inconsistencies, and inaccuracies in your data.
These datasets typically involve high volume, velocity, variety, and veracity, which are often referred to as the 4 v's of Big Data: Volume: Volume refers to the vast amount of data generated and collected from various sources. Managing and analyzing such large volumes of data requires specialized tools and technologies.
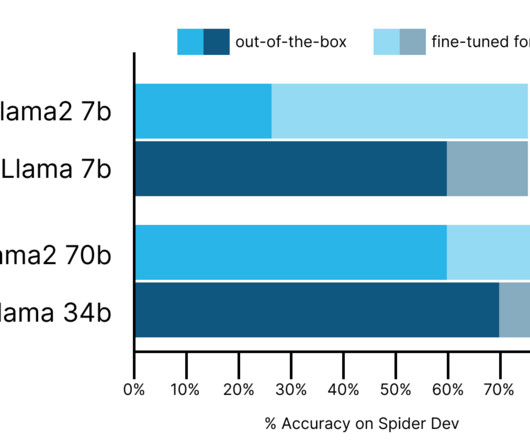
Our Code Llama fine-tuned (7b, 34b) for text-to-SQL outperforms base Code Llama (7b, 34b) by 16 and 9 percent-accuracy points respectively Evaluating performance of SQL-generation models Performance of our text-to-SQL models is reported against the “dev” subset of the Spider data set.
There are various ways to ensure data accuracy. Data validation involves checking data for errors, inconsistencies, and inaccuracies, often using predefined rules or algorithms. Datacleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
Cleansing and enriching data due to inefficient cleansing processes, address data inconsistencies, and limited access to external datasets. While each presents its own challenges, they all make it difficult to effectively leverage data for strong, agile decision-making. How many of these resonate with you?
The ingestions (ETL) pipelines transform enriched datasets to a common data model (design based on a graph structure stored as vertices and edges) to serve lineage use cases. We are loading the lineage data to a graph database to enable seamless integration with a REST data lineage service to address business use cases.
The top-line benefits of a hybrid data platform include: Cost efficiency. A hybrid data platform enables the preservation of existing investments in legacy applications and workloads without modifying them. Improved scalability and agility. A radically improved security posture.
Data pipelines often involve a series of stages where data is collected, transformed, and stored. This might include processes like data extraction from different sources, datacleansing, data transformation (like aggregation), and loading the data into a database or a data warehouse.
The mix of people, procedures, technologies, and systems ensures that the data within a company is reliable, safe, and simple for employees to access. It is a tool used by businesses to protect their data, manage who has access to it, who oversees it, and how to make it available to staff members for everyday usage.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. What level of data pipeline monitoring coverage do we need? What data SLAs should we have in place?
Lets dive into the components of data quality assurance and best practices. Table of Contents What is Data Quality Assurance? Data profiling and auditing Auditing and profiling your data can help your team to identify issues in the data that needs to be addressed, like data thats out-of-date, missing, or simply incorrect in any way.
Consider taking a certification or advanced degree Being a certified data analyst gives you an edge in grabbing high-paying remote entry level data analyst jobs. It is always better to choose certifications that are globally recognized and build skills like datacleansing, data visualization, and so on.
It involves implementing robust measures to safeguard the integrity of data. By ensuring confidentiality and reliability through stringent security protocols, organizations can protect their data from unauthorized access, instilling trust in their data management practices.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
ETL Developer Roles and Responsibilities Below are the roles and responsibilities of an ETL developer: Extracting data from various sources such as databases, flat files, and APIs. Data Warehousing Knowledge of data cubes, dimensional modeling, and data marts is required. PREVIOUS NEXT <
Data quality Microsoft Power BI does not provide any datacleansing solution. Meaning it assumes that the data you are pulling has been cleaned up well in advance, and is of high quality. So, in case you need datacleansing aptitude, you might need to look for an alternate solution to cleanse your data.
AI can help improve prediction accuracy by analyzing large data sets and identifying patterns humans may miss. In addition to these two examples, AI can also help to improve the efficiency of other data management activities such as datacleansing, classification, and security.
Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Datacleansing: Implement corrective measures to address identified issues and improve dataset accuracy levels. Automated cleansing tools can correct common errors, such as duplicates or missing values, without manual intervention.
Enhancing Data Quality Data ingestion plays an instrumental role in enhancing data quality. During the data ingestion process, various validations and checks can be performed to ensure the consistency and accuracy of data. Another way data ingestion enhances data quality is by enabling data transformation.
Data storage and processing. Based on the complexity of data, it can be moved to the storages such as cloud data warehouses or data lakes from where business intelligence tools can access it when needed. Datacleansing. Before getting thoroughly analyzed, data ? whether small or big ?
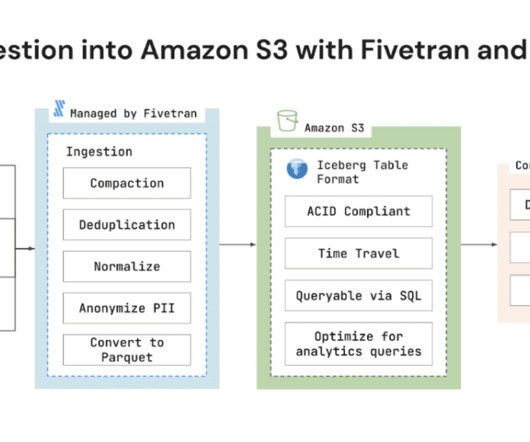
As organizations continue to leverage data lakes to run analytics and extract insights from their data, progressive marketing intelligence teams are demanding more of them, and solutions like Amazon S3 and automated pipeline support are meeting that demand.
It plays a critical role in ensuring that users of the data can trust the information they are accessing. There are several ways to ensure data consistency, including implementing data validation rules, using data standardization techniques, and employing data synchronization processes.
However, with the rise of the internet and cloud computing, data is now generated and stored across multiple sources and platforms. This dispersed data environment creates a challenge for businesses that need to access and analyze their data. This can be achieved through datacleansing and data validation.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
You will be able to do something about what data is in the request and send back a custom answer/result to the client. For example, you can use NiFi to access external systems like an FTP server over HTTP. Can a NiFi data flow be blocked or shared based on users’ access and security policy?
Integrity is crucial for meeting regulatory requirements, maintaining user confidence, and preventing data breaches or loss. How Do You Maintain Data Integrity? Data integrity issues can arise at multiple points across the data pipeline. Learn more in our blog post Data Validity: 8 Clear Rules You Can Use Today.
If you're wondering how the ETL process can drive your company to a new era of success, this blog will help you discover what use cases of ETL make it a critical component in many data management and analytic systems. Business Intelligence - ETL is a key component of BI systems for extracting and preparing data for analytics.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
Accelerated decision-making In today’s fast-paced business environment, where decisions need to be made quickly based on accurate information, having access to reliable and trustworthy data becomes crucial. IBM® Databand® is a powerful and comprehensive data testing tool that offers a wide range of features and functions.
Poor data quality can lead to incorrect or misleading insights, which can have significant consequences for an organization. DataOps tools help ensure data quality by providing features like data profiling, data validation, and datacleansing.
Transformation: Shaping Data for the Future: LLMs facilitate standardizing date formats with precision and translation of complex organizational structures into logical database designs, streamline the definition of business rules, automate datacleansing, and propose the inclusion of external data for a more complete analytical view.
Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers Robert Half Technology survey of 1400 CIO’s revealed that 53% of the companies were actively collecting data but they lacked sufficient skilled data analysts to access the data and extract insights.
Data Transformation and ETL: Handle more complex data transformation and ETL (Extract, Transform, Load) processes, including handling data from multiple sources and dealing with complex data structures. Ensure compliance with data protection regulations. Identify and address bottlenecks and performance issues.
Due to its strong data analysis and manipulation skills, it has significantly increased its prominence in the field of data science. Python offers a strong ecosystem for data scientists to carry out activities like datacleansing, exploration, visualization, and modeling thanks to modules like NumPy, Pandas, and Matplotlib.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content