This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Here are several reasons data quality is critical for organizations: Informed decision making: Low-quality data can result in incomplete or incorrect information, which negatively affects an organization’s decision-making process. A complete dataset allows for more comprehensive analysis and decision-making.
As you do not want to start your development with uncertainty, you decide to go for the operational raw data directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the raw data. Does it sound familiar?
What times of the day are busy in the area, and are roads accessible? Data enrichment helps provide a 360 o view which informs better decisions around insuring, purchasing, financing, customer targeting, and more. Together, data validation and enrichment form a powerful combination that delivers even bigger results for your business.
If you want to break into the field of data engineering but don't yet have any expertise in the field, compiling a portfolio of data engineering projects may help. Data pipeline best practices should be shown in these initiatives. Source: Use Stack Overflow Data for Analytic Purposes 4. Which queries do you have?
Spark Streaming Kafka Streams 1 Data received from live input data streams is Divided into Micro-batched for processing. processes per data stream(real real-time) 2 A separate processing Cluster is required No separate processing cluster is required. it's better for functions like row parsing, datacleansing, etc.
AI-driven data quality workflows deploy machine learning to automate datacleansing, detect anomalies, and validate data. Integrating AI into data workflows ensures reliable data and enables smarter business decisions. Data quality is the backbone of successful data engineering projects.
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. Accelerated Decision-Making In today’s fast-paced business environment, where decisions need to be made quickly based on accurate information, having access to reliable and trustworthy data becomes crucial.
Validity: Adherence to predefined formats, rules, or standards for each attribute within a dataset. Uniqueness: Ensuring that no duplicate records exist within a dataset. Integrity: Maintaining referential relationships between datasets without any broken links.
Power BI Desktop Power BI Desktop is free software that can be downloaded and installed to build reports by accessingdata easily without the need for advanced report designing or query skills to build a report. Multiple Data Sources Multiple Data Sources support various data sources like Excel, CSV, SQL Server, Web files, etc.
Consider exploring relevant Big Data Certification to deepen your knowledge and skills. What is Big Data? Big Data is the term used to describe extraordinarily massive and complicated datasets that are difficult to manage, handle, or analyze using conventional data processing methods.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. What level of data pipeline monitoring coverage do we need? What data SLAs should we have in place?
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
There are various ways to ensure data accuracy. Data validation involves checking data for errors, inconsistencies, and inaccuracies, often using predefined rules or algorithms. Datacleansing involves identifying and correcting errors, inconsistencies, and inaccuracies in data sets.
This includes defining roles and responsibilities related to managing datasets and setting guidelines for metadata management. Data profiling: Regularly analyze dataset content to identify inconsistencies or errors. Automated profiling tools can quickly detect anomalies or patterns indicating potential dataset integrity issues.
Cleansing and enriching data due to inefficient cleansing processes, address data inconsistencies, and limited access to external datasets. While each presents its own challenges, they all make it difficult to effectively leverage data for strong, agile decision-making.
We also leverage metadata from another internal tool, Genie , internal job and resource manager, to add job metadata (such as job owner, cluster, scheduler metadata) on lineage data. We are loading the lineage data to a graph database to enable seamless integration with a REST data lineage service to address business use cases.
Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content. Accelerated decision-making In today’s fast-paced business environment, where decisions need to be made quickly based on accurate information, having access to reliable and trustworthy data becomes crucial.
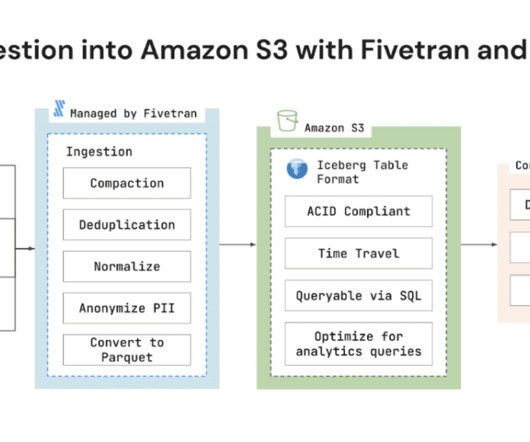
As organizations continue to leverage data lakes to run analytics and extract insights from their data, progressive marketing intelligence teams are demanding more of them, and solutions like Amazon S3 and automated pipeline support are meeting that demand.
The PowerBI Site or service, PowerBI.com , is widely used to share reports, datasets, and dashboards. Data quality Microsoft Power BI does not provide any datacleansing solution. Meaning it assumes that the data you are pulling has been cleaned up well in advance, and is of high quality.
Let's dive into the top data cleaning techniques and best practices for the future – no mess, no fuss, just pure data goodness! What is Data Cleaning? It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data. Why Is Data Cleaning So Important?
You will be able to do something about what data is in the request and send back a custom answer/result to the client. For example, you can use NiFi to access external systems like an FTP server over HTTP. Can a NiFi data flow be blocked or shared based on users’ access and security policy?
Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers Robert Half Technology survey of 1400 CIO’s revealed that 53% of the companies were actively collecting data but they lacked sufficient skilled data analysts to access the data and extract insights.
Data Processing and Cleaning : Preprocessing and data cleaning are important steps since raw data frequently has errors, duplication, missing information, and inconsistencies. To make sure the data is precise and suitable for analysis, data processing analysts use methods including datacleansing, imputation, and normalisation.
Enhancing Data Quality Data ingestion plays an instrumental role in enhancing data quality. During the data ingestion process, various validations and checks can be performed to ensure the consistency and accuracy of data. Another way data ingestion enhances data quality is by enabling data transformation.
The architecture is three layered: Database Storage: Snowflake has a mechanism to reorganize the data into its internal optimized, compressed and columnar format and stores this optimized data in cloud storage. This stage handles all the aspects of data storage like organization, file size, structure, compression, metadata, statistics.
As we move firmly into the data cloud era, data leaders need metrics for the robustness and reliability of the machine–the data pipelines, systems, and engineers–just as much as the final (data) product it spits out. What level of data pipeline monitoring coverage do we need? What data SLAs should we have in place?
Integrity is crucial for meeting regulatory requirements, maintaining user confidence, and preventing data breaches or loss. How Do You Maintain Data Integrity? Data integrity issues can arise at multiple points across the data pipeline. How Do You Maintain Data Validity?
Data Transformation and ETL: Handle more complex data transformation and ETL (Extract, Transform, Load) processes, including handling data from multiple sources and dealing with complex data structures. Ensure compliance with data protection regulations. Define data architecture standards and best practices.
Whether it's aggregating customer interactions, analyzing historical sales trends, or processing real-time sensor data, data extraction initiates the process. What is the purpose of extracting data? The purpose of data extraction is to transform large, unwieldy datasets into a usable and actionable format.
Due to its strong data analysis and manipulation skills, it has significantly increased its prominence in the field of data science. Python offers a strong ecosystem for data scientists to carry out activities like datacleansing, exploration, visualization, and modeling thanks to modules like NumPy, Pandas, and Matplotlib.
You need to clean your data before you begin analyzing it so that you don’t end up with false conclusions or inaccurate results. . There are two main ways to clean your data: manual and automatic. Data cleaning and data transformation are processes that help transform data from its original state into a more useful format.
A data scientist’s job needs loads of exploratory data research and analysis on a daily basis with the help of various tools like Python, SQL, R, and Matlab. This role is an amalgamation of art and science that requires a good amount of prototyping, programming and mocking up of data to obtain novel outcomes.
Engineers ensure the availability of clean, structured data, a necessity for AI systems to learn from patterns, make accurate predictions, and automate decision-making processes. Through the design and maintenance of efficient data pipelines , data engineers facilitate the seamless flow and accessibility of data for AI processing.
Hadoop and Spark: The cavalry arrived in the form of Hadoop and Spark, revolutionizing how we process and analyze large datasets. Cloud Era: Cloud platforms like AWS and Azure took center stage, making sophisticated data solutions accessible to all.
Use cases for memory-optimized instances include- Database Servers- Applications like relational databases benefit from the higher memory capacity to store and retrieve data efficiently. In-Memory Caching- Memory-optimized instances are suitable for in-memory caching solutions, enhancing the speed of dataaccess.
Organizing, storing, and accessingdata is important for AI. Incorporating AI into data modeling relies on fundamental techniques and principles that enhance the synergy between data and AI models. Techniques like outlier detection and imputation help make sure your data is reliable and ready for analysis.
The insights derived from the data in hand are then turned into impressive business intelligence visuals such as graphs or charts for the executive management to make strategic decisions. In this post, we will discuss the top power BI developer skills required to access Microsoft’s power business intelligence software.
It effectively works with Tableau Desktop and Tableau Server to allow users to publish bookmarked, cleaned-up data sources that can be accessed by other personnel within the same organization. This capability underpins sustainable, chattel datacleansing practices requisite to data governance.
Step 2: Extract data: The next step is to extract the data from the sources using tools such as ETL (Extract, Transform, Load) or API (Application Programming Interface). Step 5: Summarize data: The aggregated data is then summarized into meaningful metrics such as averages, sums, and count or any useful data operation.
As per Microsoft, “A Power BI report is a multi-perspective view of a dataset, with visuals representing different findings and insights from that dataset. ” Reports and dashboards are the two vital components of the Power BI platform, which are used to analyze and visualize data. Back up your data regularly.
For example: Aggregating Data: This includes summing up numerical values and applying mathematical functions to create summarized insights from the raw data. Data Type Conversion: Adjusting data types for consistency across the dataset, which can involve altering date formats, numeric values, or other types.
And if you are aspiring to become a data engineer, you must focus on these skills and practice at least one project around each of them to stand out from other candidates. Explore different types of Data Formats: A data engineer works with various dataset formats like.csv,josn,xlx, etc.
When crucial information is omitted or unavailable, the analysis or conclusions drawn from the data may be flawed or misleading. Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies. This can include contradictory information or data points that do not align with established patterns or trends.
For Silicon Valley startups launching a big data platform, the best way to reduce expenses is to pay remote workers so that they can distribute tasks to people who have internet access anywhere in the world. However, it is important to understand the fact that big data analytics is not merely for big corporate IT giants.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content