This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
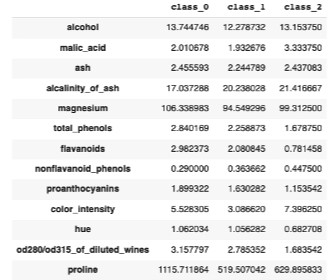
Datasets are the repository of information that is required to solve a particular type of problem. Also called data storage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
The answer lies in the strategic utilization of business intelligence for datamining (BI). DataMining vs Business Intelligence Table In the realm of data-driven decision-making, two prominent approaches, DataMining vs Business Intelligence (BI), play significant roles.
Data is the New Fuel. We all know this , so you might have heard terms like Artificial Intelligence (AI), Machine Learning, DataMining, Neural Networks, etc. Oh wait, how can we forget Data Science? We all have heard of Data Scientist: The Sexiest Job of the 21st century. What is DataMining?
Furthermore, it was difficult to transfer innovations from one model to another, given that most are independently trained despite using common data sources. This scenario underscored the need for a new recommender system architecture where member preference learning is centralized, enhancing accessibility and utility across different models.
In this blog, you will find a list of interesting datamining projects that beginners and professionals can use. Please don’t think twice about scrolling down if you are looking for datamining projects ideas with source code. The dataset has three files, namely features_data, sales_data, and stores_data.
Most Data Analysts do not require a deep understanding of complex mathematics, even though they should have a foundational knowledge of statistics and mathematics. Statistics, linear algebra, and calculus are generally required for Data Analysts. Why is MS Access important in Data Analytics? What is data extraction?
Big Data Analytics in the Industrial Internet of Things 4. DataMining 12. The edge computing system can store vast amounts of data to retrieve in the future. It also provides fast access to information in need. It maintains computing resources from the cloud and data centers while processing. Robotics 1.
Using Data to Gain Future Knowledge In order to evaluate past data and forecast future events, predictive analytics makes use of statistical models, machine learning, and datamining. Cloud-Based Solutions: Large datasets may be effectively stored and analysed using cloud platforms.
The KDD process in datamining is used in business in the following ways to make better managerial decisions: . Data summarization by automatic means . Analyzing raw data to discover patterns. . This article will briefly discuss the KDD process in datamining and the KDD process steps. . What is KDD?
DataMiningData science field of study, datamining is the practice of applying certain approaches to data in order to get useful information from it, which may then be used by a company to make informed choices. It separates the hidden links and patterns in the data.
According to the Cybercrime Magazine, the global data storage is projected to be 200+ zettabytes (1 zettabyte = 10 12 gigabytes) by 2025, including the data stored on the cloud, personal devices, and public and private IT infrastructures. The dataset can be either structured or unstructured or both.
From machine learning algorithms to datamining techniques, these ideas are sure to challenge and engage you. To develop such an app, you will need to have a strong understanding of computer science concepts such as data structures and algorithms. To get started, you'll need to gather data from a variety of sources.
Importing And Cleaning Data This is an important step as a perfect and clean dataset is required for distinct and perfect data visualization. Each has a particular objective while managing images, textual data, datamining, data visualization, and more. Data specialist (Rs.
The techniques of dimensionality reduction are important in applications of Machine Learning, DataMining, Bioinformatics, and Information Retrieval. The main agenda is to remove the redundant and dependent features by changing the dataset onto a lower-dimensional space. In simple terms, they reduce the dimensions (i.e.
Undoubtedly, everyone knows that the only best way to learn data science and machine learning is to learn them by doing diverse projects. Table of Contents What is a dataset in machine learning? Why you need machine learning datasets? Where can I find datasets for machine learning? Why you need machine learning datasets?
Data analytics, datamining, artificial intelligence, machine learning, deep learning, and other related matters are all included under the collective term "data science" When it comes to data science, it is one of the industries with the fastest growth in terms of income potential and career opportunities.
This article will help you understand what data aggregation is, its levels, examples, process, tools, use cases, benefits, types, and differences between data aggregation and datamining. If you would like to learn more about different data aggregation techniques check out a Data Engineer certification program.
They also maintain these systems and datasets that are accessible and easily usable for further uses. They also look into implementing methods that improve data readability and quality, along with developing and testing architectures that enable data extraction and transformation.
Prepare for Your Next Big Data Job Interview with Kafka Interview Questions and Answers Robert Half Technology survey of 1400 CIO’s revealed that 53% of the companies were actively collecting data but they lacked sufficient skilled data analysts to access the data and extract insights.
These will allow you to access things from your wardrobe just by a single tap on your phone. Binary Classification Machine Learning This type of classification involves separating the dataset into two categories. Imbalanced Classification Example: Detecting fraudulent transactions through a credit card in a transaction dataset.
Loading is the process of warehousing the data in an accessible location. The difference here is that warehoused data is in its raw form, with the transformation only performed on-demand following information access. One of the leaders in the space focused on data transforms is dbt.
With the help of these tools, analysts can discover new insights into the data. Hadoop helps in datamining, predictive analytics, and ML applications. Why are Hadoop Big Data Tools Needed? Features: HDFS incorporates concepts like blocks, data nodes, node names, etc. The files stored in HDFS are easily accessible.
The vast majority of big data analytics used by organizations falls into descriptive analytics. Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization A company learns from its actions in the past to predict future events. Root Cause Analysis-Why this happen?
Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Hadoop can store data and run applications on cost-effective hardware clusters.
Aside from that, users can also generate descriptive visualizations through graphs, and other SAS versions provide reporting on machine learning, datamining, time series, and so on. DATA Step: The data step includes all SAS statements, beginning with line data and ending with line datalines.
Data science professionals are scattered across various industries. This data science tool helps in digital marketing & the web admin can easily access, visualize, and analyze the website traffic, data, etc., A lot of MNCs and Fortune 500 companies are utilizing this tool for statistical modeling and data analysis.
2014 Kaggle Competition Walmart Recruiting – Predicting Store Sales using Historical Data Description of Walmart Dataset for Predicting Store Sales What kind of big data and hadoop projects you can work with using Walmart Dataset? petabytes of unstructured data from 1 million customers every hour.
In summary, data extraction is a fundamental step in data-driven decision-making and analytics, enabling the exploration and utilization of valuable insights within an organization's data ecosystem. What is the purpose of extracting data? The process of discovering patterns, trends, and insights within large datasets.
Business Intelligence refers to the toolkit of techniques that leverage a firm’s data to understand the overall architecture of the business. This understanding is achieved by using data visualization , datamining, data analytics, data science, etc. methodologies. influence the land prices.
It explores techniques to protect sensitive data while maintaining its usefulness for analysis and reporting, considering factors such as data masking algorithms, data classification, and access control mechanisms. They manage dataaccess, monitor data quality, and enforce data protection measures.
Data wrangling offers several benefits, such as: Usable Data: Data wrangling converts raw data into a format suitable for analysis, ensuring the quality and integrity of the data used for downstream processes. Tabula : A versatile tool suitable for all data types, making it accessible for a wide range of users.
It is a group of resources and services for turning data into usable knowledge and information. Descriptive analytics, performance benchmarking, process analysis, and datamining fall under the business intelligence (BI) umbrella. Once the budget reports are authorized, users can transfer the budget data to ERP.
Having multiple hadoop projects on your resume will help employers substantiate that you can learn any new big data skills and apply them to real life challenging problems instead of just listing a pile of hadoop certifications. Creating query to populate and filter the data. Analysis large datasets easily and efficiently.
Data Management and Storage: Data processing analysts are frequently in charge of setting up and maintaining data warehouses, databases, and other storage facilities. Data security, access restrictions, and data retention policies must all be taken into account.
Knowing SQL allows you to alter data structures as well as modify, organize, and query data contained in relational databases (schema). SQL is likely the most necessary skill to master to gain a job because practically all data analysts will need to accessdata from a company's database.
Embracing data science isn't just about understanding numbers; it's about wielding the power to make impactful decisions. Imagine having the ability to extract meaningful insights from diverse datasets, being the architect of informed strategies that drive business success. That's the promise of a career in data science.
Get FREE Access to Machine Learning Example Codes for Data Cleaning, Data Munging, and Data Visualization Java vs Python for Data Science- Frameworks and Tools Python and Java provide a good collection of built-in libraries which can be used for data analytics, data science, and machine learning.
So, focus on enhancing modularity, and your data management will become utterly convenient. Every time the new datasets get extracted, make sure you segregate them into modules based on their use or category. Automate Data Pipelines Data pipelines are the data engineering architecture patterns through which the information travels.
The Rossmann Stores dataset is one of the most popular datasets used by Data Science beginners. You can use the dataset and the linear regression machine-learning algorithm to forecast retail sales in this project. You will train and test the data model using the cross-validation method.
This process is called lead scoring and with access to data analytics, it allows you to predict how much each lead matters with utmost accuracy. When combined with machine learning and datamining , it can make forecasts based on historical and existing data to identify the likelihood of conversion. Data security.
TensorFlow clusters together machine learning and deep learning models and renders them through large datasets to train these models to think and create sensible outcomes on their own. It helps in implementing predictive analytics with mathematics to make decisions based on granular data. It is Spark's fundamental data structure.
Hence, learning and developing the required data engineer skills set will ensure a better future and can even land you better salaries in good companies anywhere in the world. After all, data engineer skills are required to collect data, transform it appropriately, and make it accessible to data scientists.
Machine Learning is receiving so much traction because it reveals insightful facts from a given dataset that would not have been gained access to by using other tools. It simplifies complex problems by making probabilistic predictions for specific parameters in the dataset. Is Coding required for Machine Learning?
Applications of DataMining in Software Engineering Mining Software Engineering Data The mining of software engineering data is one of the significant research paper topics for software engineering, involving the application of datamining techniques to extract insights from enormous datasets that are generated during software development processes.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content