This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
and its potential to revolutionize data flow management. access our free 5-day trial now. introduces new features specifically designed to fuel GenAI initiatives: New AI Processors: Harness the power of cutting-edge AI models with new processors that simplify integration and streamline datapreparation for GenAI applications.
You can access it from here. In order to begin with the data transformation part, it is recommended to create folders where the pipeline components would be placed (else they will be placed in the default directory). This dataset is free to use for commercial and non-commercial purposes.
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. DataPreparation.
Tableau Prep is a fast and efficient datapreparation and integration solution (Extract, Transform, Load process) for preparingdata for analysis in other Tableau applications, such as Tableau Desktop. simultaneously making raw data efficient to form insights. BigQuery), or another data storage solution.
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
At the data platform level, we found: 55% of organizations are hampered by time-consuming data management tasks such as labeling. 52% struggle with data quality including issues of error, bias, irrelevance and timeliness. 51% say datapreparation is too hard. 50% cite issues with data sensitivity.
Cortex AI delivers exceptional quality across a wide range of unstructured data processing tasks through models and specialized functions tailored for different tasks. Best-in-class machine translation : For all digital text and extracted text from documents, organizations often need to make information accessible across languages.
Mishandling this data exposes organizations to significant risks, including regulatory fines and reputational damage. To safeguard sensitive information, compliance with frameworks like GDPR and HIPAA requires encryption, access control, and anonymization techniques.
In seconds, Spotter can create a guide for working with this worksheet, highlighting both its structure (columns) and potential applications (questions) in a way that makes the data more accessible and actionable for further analysis.
Powered by Trino, Starburst runs petabyte-scale SQL analytics fast at a fraction of the cost of traditional methods, helping you meet all your data needs ranging from AI/ML workloads to data applications to complete analytics. What are the features and focus of Pieces that might encourage someone to use it over the alternatives?
As organizations increasingly seek to enhance decision-making and drive operational efficiencies by making knowledge in documents accessible via conversational applications, a RAG-based application framework has quickly become the most efficient and scalable approach. Amazon S3) without copying the original file into Snowflake.
But without a governed data foundation, you can’t trust results or unlock all that’s possible with these breakaway technologies. To ensure data remains protected from unintended use, Snowflake Cortex (now in private preview) gives users access to industry-leading LLMs (e.g.,
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the datapreparation process and thus accelerates the datapreparation by 4x.
Ease of Exploration: Makes it simpler to try out new tools, languages, or frameworks with instant access to relevant code snippets and usage examples. Step 2: Access Extensions To open the Extensions view in Visual Studio Code, click the icon that looks like four small squares arranged in a grid, located in the sidebar.
Snowpark is our secure deployment and processing of non-SQL code, consisting of two layers: Familiar Client Side Libraries – Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use.
Create Snowflake dynamic tables In Snowflake, create dynamic tables by writing SQL queries that define how data should be transformed and materialized. Grant ThoughtSpot access In Snowflake, grant the ThoughtSpot service account USAGE privileges on the schemas containing the dynamic tables. Set refresh schedules as needed.
Harnessing the power of Snowflake Cortex ML-based forecasting and anomaly detection is easy: Simply use them wherever you access your Snowflake data today, whether in Snowsight or your favorite SQL editor. Note: LLM-based functions are still in private preview; reach out to your account team to gain access.)
For example: Custom text summaries in JSON format Turning email domains into rich data sets Building data quality agents using LLMs All of these and more can quickly be accomplished with the power of industry-leading foundation models from Mistral AI ( Mistral Large , Mistral 8x7B , Mistral 7B ), Google (Gemma-7b) and Meta (Llama2 70B).
In this first Google Cloud release, CDP Public Cloud provides built-in Data Hub definitions (see screenshot for more details) for: Data Ingestion (Apache NiFi, Apache Kafka). DataPreparation (Apache Spark and Apache Hive) . Analyze static (Apache Impala) and streaming (Apache Flink) data.
A 2016 data science report from data enrichment platform CrowdFlower found that data scientists spend around 80% of their time in datapreparation (collecting, cleaning, and organizing of data) before they can even begin to build machine learning (ML) models to deliver business value.
Founded on the principle of empowering every stakeholder to make data-driven decisions, Modern’s journey is intricately tied to the ideals of data democratization. This involves delivering data integration solutions that facilitate faster access to trusted data across distributed landscapes.
A database is a structured data collection that is stored and accessed electronically. According to a database model, the organization of data is known as database design. While using Amazon SageMaker datasets are quick to access and load. Kaggle Datasets : It is an online community platform for data science enthusiasts.
How do data protection regulations impact or restrict the technology choices that are viable for the datapreparation layer? Who in the organization is responsible for the proper compliance to GDPR and other data protection regimes? How do the regulations impact the types of analytics that they can use?
Spotlight on Augmented Analytics Also hailed as the future of Business Intelligence, Augmented analytics employs machine learning/ artificial intelligence (ML/AI) techniques to automate datapreparation, insight discovery and sharing, data science and ML model development, management and deployment.
Large-model AI is becoming more and more influential in the market, and with the well-known tech giants starting to introduce easy-access AI stacks, a lot of businesses are left feeling that although there may be a use for AI in their business, they’re unable to see what use cases it might help them with.
All cloud models and resources can be accessible from the internet. Access to these resources is possible using any browser software or internet-connected device. With the rise of new technologies, there has been an overflow of large chunks of data. Cloud Computing Services can be accessed with the help of the internet.
Datapreparation for LOS prediction. As with any ML initiative, everything starts with data. Overall, the MIMIC database features health data from over 40,000 critical care patients and embraces multiple variables. But to get access to this treasure, you must ?omplete Syntegra synthetic data. several others.
Here, data scientists are supported by data engineers. Data engineering itself is a process of creating mechanisms for accessingdata. A data scientist takes part in almost all stages of a machine learning project by making important decisions and configuring the model. Datapreparation and cleaning.
Key Takeaways Leverage location intelligence (LI) to make informed business decisions with spatial data insights. Use accessible LI tools to democratize data and enable competitive advantages. Ensure data accuracy and integrity of your location data to maximize the benefits of location intelligence.
These technologies enable: Automated datapreparation and cleansing Advanced predictive analytics Natural language processing for querying data AI recommendations for insights and visualizations As AI capabilities improve, we can expect BI tools to become more proactive in surfacing relevant insights and automating routine analysis tasks.
It is important to make use of this big data by processing it into something useful so that the organizations can use advanced analytics and insights to their advant age (generating better profits, more customer-reach, and so on). These steps will help understand the data, extract hidden patterns and put forward insights about the data.
We have been investing in development for years to deliver common security, governance, and metadata management across the entire data layer with capabilities to mask data, provide fine grained access, and deliver a single data catalog to view all data across the enterprise. 5-Integrated open data collection.
Founded on the principle of empowering every stakeholder to make data-driven decisions, Modern’s journey is intricately tied to the ideals of data democratization. Augmented data integration, self-service datapreparation, metadata support, and data governance are key strengths.
Ability to use multiple different flexible partitioning schemes to accommodate any real-time data, regardless of each stream’s particular characteristics. Making sure data is able to land in real time and be accessed just as fast requires a “best fit” partitioning scheme. Kudu has this covered.
While it’s important to have the in-house data science expertise and the ML experts on-hand to build and test models, the reality is that the actual data science work — and the machine learning models themselves — are only one part of the broader enterprise machine learning puzzle.
Data Sources Tableau Software can access many data sources and servers. The thing about Power BI is that it supports different data sources. The ease of Using Tableau provides some crucial advantages for detailed data exploration and visualization.
AWS Glue Architecture and Components Source: AWS Glue Documentation AWS Glue Data Catalog Data Catalog is a massively scalable grouping of tables into databases. By using AWS Glue Data Catalog, multiple systems can store and access metadata to manage data in data silos.
Machine Learning in AWS SageMaker Machine learning in AWS SageMaker involves steps facilitated by various tools and services within the platform: DataPreparation: SageMaker comprises tools for labeling the data and data and feature transformation. This ensures that the data is secured from its generation to its disposal.
Read Common Data Challenges in Telecommunications As natural innovators, telecommunications firms have been early adopters of advanced analytics. Despite that fact, valuable data often remains locked up in various silos across the organization. This shortfall in effective data governance inhibits visibility and transparency.
Key Takeaways Data Fabric is a modern data architecture that facilitates seamless dataaccess, sharing, and management across an organization. Data management recommendations and data products emerge dynamically from the fabric through automation, activation, and AI/ML analysis of metadata.
Data wrangling offers several benefits, such as: Usable Data: Data wrangling converts raw data into a format suitable for analysis, ensuring the quality and integrity of the data used for downstream processes. Tabula : A versatile tool suitable for all data types, making it accessible for a wide range of users.
CPUs and GPUs can be used in tandem for data engineering and data science workloads. A typical machine learning workflow involves datapreparation, model training, model scoring, and model fitting. To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deep learning workloads. .
It enables models to stay updated by automatically retraining on incrementally larger and more recent data with a pre-defined periodicity. One of the key functions of the framework is enabling the publishing of the newly-trained model to the model artifactory, so that the production machines access these models seamlessly.
The insights derived from the data in hand are then turned into impressive business intelligence visuals such as graphs or charts for the executive management to make strategic decisions. In this post, we will discuss the top power BI developer skills required to access Microsoft’s power business intelligence software.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



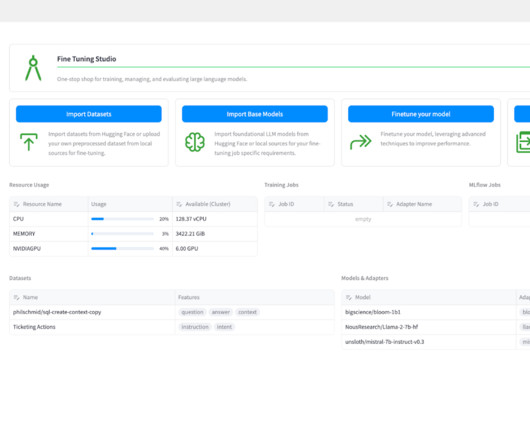





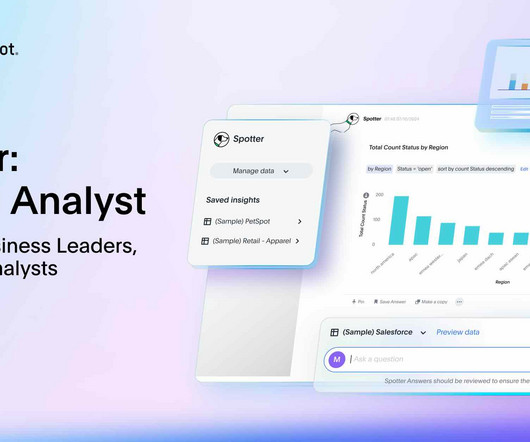


















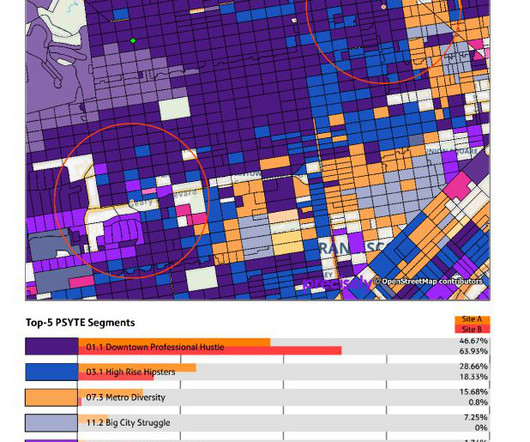



















Let's personalize your content