This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
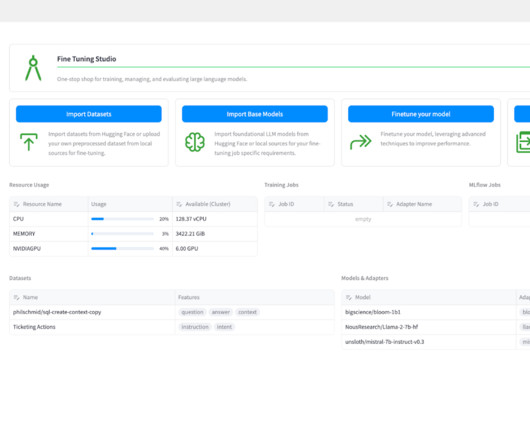
Several LLMs are publicly available through APIs from OpenAI , Anthropic , AWS , and others, which give developers instant access to industry-leading models that are capable of performing most generalized tasks. Fine Tuning Studio enables users to track the location of all datasets, models, and model adapters for training and evaluation.
For example: Text Data: Natural Language Processing (NLP) techniques are required to handle the subtleties of human language, such as slang, abbreviations, or incomplete sentences. Images and Videos: Computer vision algorithms must analyze visual content and deal with noisy, blurry, or mislabeled datasets.
Level 2: Understanding your dataset To find connected insights in your business data, you need to first understand what data is contained in the dataset. This is often a challenge for business users who arent familiar with the source data. Thats where ThoughtSpots architecture comes in.
Williams on Unsplash Data pre-processing is one of the major steps in any Machine Learning pipeline. Tensorflow Transform helps us achieve it in a distributed environment over a huge dataset. This dataset is free to use for commercial and non-commercial purposes. You can access it from here.
Tableau Prep is a fast and efficient datapreparation and integration solution (Extract, Transform, Load process) for preparingdata for analysis in other Tableau applications, such as Tableau Desktop. simultaneously making raw data efficient to form insights. BigQuery), or another data storage solution.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your raw data and transformed datasets optimized for AI-powered analytics with ThoughtSpot. Set refresh schedules as needed.
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structured data collection that is stored and accessed electronically.
The platform converges data cataloging, data ingestion, data profiling, data tagging, data discovery, and data exploration into a unified platform, driven by metadata. Modak Nabu automates repetitive tasks in the datapreparation process and thus accelerates the datapreparation by 4x.
Ease of Exploration: Makes it simpler to try out new tools, languages, or frameworks with instant access to relevant code snippets and usage examples. Step 2: Access Extensions To open the Extensions view in Visual Studio Code, click the icon that looks like four small squares arranged in a grid, located in the sidebar.
There are two main steps for preparingdata for the machine to understand. Any ML project starts with datapreparation. You can’t simply feed the system your whole dataset of emails and expect it to understand what you want from it. What should it be like and how to prepare a great one?
Datapreparation for LOS prediction. As with any ML initiative, everything starts with data. The main sources of such data are electronic health record ( EHR ) systems which capture tons of important details. Yet, there’re a few essential things to keep in mind when creating a dataset to train an ML model.
Nonetheless, it is an exciting and growing field and there can't be a better way to learn the basics of image classification than to classify images in the MNIST dataset. Table of Contents What is the MNIST dataset? Test the Trained Neural Network Visualizing the Test Results Ending Notes What is the MNIST dataset?
Here, data scientists are supported by data engineers. Data engineering itself is a process of creating mechanisms for accessingdata. Distinction between data scientists and engineers is similar. Data scientist’s responsibilities — Datasets and Models. Datapreparation and cleaning.
Data Sources Tableau Software can access many data sources and servers. The thing about Power BI is that it supports different data sources. The ease of Using Tableau provides some crucial advantages for detailed data exploration and visualization.
All cloud models and resources can be accessible from the internet. Access to these resources is possible using any browser software or internet-connected device. With the rise of new technologies, there has been an overflow of large chunks of data. Cloud Computing Services can be accessed with the help of the internet.
Scale Existing Python Code with Ray Python is popular among data scientists and developers because it is user-friendly and offers extensive built-in data processing libraries. For analyzing huge datasets, they want to employ familiar Python primitive types. The limitation here is we can attach the trigger to only 2 crawlers.
It enables models to stay updated by automatically retraining on incrementally larger and more recent data with a pre-defined periodicity. In content moderation classifier development, there are Data ETL (Export, Transform, Load) pipelines that collect data from various sources and store it in offline locations like a data lake or HDFS.
Snowpark is our secure deployment and processing of non-SQL code, consisting of two layers: Familiar Client Side Libraries – Snowpark brings deeply integrated, DataFrame-style programming and OSS compatible APIs to the languages data practitioners like to use.
Key Takeaways Leverage location intelligence (LI) to make informed business decisions with spatial data insights. Use accessible LI tools to democratize data and enable competitive advantages. Ensure data accuracy and integrity of your location data to maximize the benefits of location intelligence.
While it’s important to have the in-house data science expertise and the ML experts on-hand to build and test models, the reality is that the actual data science work — and the machine learning models themselves — are only one part of the broader enterprise machine learning puzzle. Laurence Goasduff, Gartner.
Data testing tools: Key capabilities you should know Helen Soloveichik August 30, 2023 Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing and maintaining data quality. There are several types of data testing tools.
What is Data Cleaning? Data cleaning, also known as data cleansing, is the essential process of identifying and rectifying errors, inaccuracies, inconsistencies, and imperfections in a dataset. It involves removing or correcting incorrect, corrupted, improperly formatted, duplicate, or incomplete data.
Time-saving: SageMaker automates many of the tasks, by creating a pipeline starting from datapreparation and ML model training, which saves time and resources. Amazon SageMaker provides various tools and features to help prepare the data for machine learning tasks. It provides Processing Jobs to prepare the data.
For machine learning algorithms to predict prices accurately, people who do the datapreparation must consider these factors and gather all this information to train the model. Data relevance. Data sources In developing hotel price prediction models, gathering extensive data from different sources is crucial.
The insights derived from the data in hand are then turned into impressive business intelligence visuals such as graphs or charts for the executive management to make strategic decisions. In this post, we will discuss the top power BI developer skills required to access Microsoft’s power business intelligence software.
Over the years, the field of data engineering has seen significant changes and paradigm shifts driven by the phenomenal growth of data and by major technological advances such as cloud computing, data lakes, distributed computing, containerization, serverless computing, machine learning, graph database, etc.
As you now know the key characteristics, it gets clear that not all data can be referred to as Big Data. What is Big Data analytics? Big Data analytics is the process of finding patterns, trends, and relationships in massive datasets that can’t be discovered with traditional data management techniques and tools.
In today's data-driven world, the ability to transform raw data into meaningful insights is paramount, and Power BI empowers users to achieve just that. This article serves as your essential primer, offering a structured and accessible pathway to navigate the intricacies of Power BI.
MapReduce is a Hadoop framework used for processing large datasets. Another name for it is a programming model that enables us to process big datasets across computer clusters. This program allows for distributed data storage, simplifying complex processing and vast amounts of data. Explain the datapreparation process.
Its records modeling prowess and overall performance with large datasets make it ideal for companies. Power BI vs Excel: Size of Data Size of the Data Power BI: Power BI is optimized for coping with massive datasets effectively. Excel: Excel files are typically saved locally or on shared network drives.
Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing, and maintaining data quality. There are several types of data testing tools. Data profiling tools: Profiling plays a crucial role in understanding your dataset’s structure and content.
To answer the three fundamental questions outlined above, telecoms rely on business-friendly GIS to create a single view of the network that’s accessible, easily understood, and trusted by internal stakeholders to drive better, data-informed decisions. They also need a strong foundation of data science to underpin those efforts.
SageMaker, on the other hand, works well with other AWS services and provides a sound foundation to deal with large datasets and computations effectively. For data storage and warehousing, users can use Amazon S3 service, while for cataloging the data, users can use Amazon Glue and perform ETL operations.
Data wrangling offers several benefits, such as: Usable Data: Data wrangling converts raw data into a format suitable for analysis, ensuring the quality and integrity of the data used for downstream processes. Tabula : A versatile tool suitable for all data types, making it accessible for a wide range of users.
Top 5 Loan Prediction Datasets to Practice Loan Prediction Projects Univ.AI Top 5 Loan Prediction Datasets to Practice Loan Prediction Projects Univ.AI A machine learning model can look at this data, which could be static or time-series, and give a probability estimate of whether this loan will be approved.
Top 20 Python Projects for Data Science Without much ado, it’s time for you to get your hands dirty with Python Projects for Data Science and explore various ways of approaching a business problem for data-driven insights. 1) Music Recommendation System on KKBox Dataset Music in today’s time is all around us.
It transforms data from many sources in order to create dynamic dashboards and Business Intelligence reports. Datapreparation, modelling, and visualization are expedited by this simple, low-cost method. Modern data privacy technology is also considerably more affordable than its competitors.
Modern problems require modern solutions — which is why businesses across industries are moving away from batch processing and towards real-time data streams, or streaming data. Today, we’ll walk you through the close connection between successful machine learning and streaming data. Here’s how it can make a difference.
That is why data scarcity has become a significant problem, particularly in research domains like healthcare and finance, where the data is confidential or not easily accessible for machine learning professionals who want to leverage it. Given enough training data, machine learning models can smoothly solve challenging problems.
We also scaled the dataset size to 100 GB and 600M rows of data, a scale factor of 100, just like Altinity and Imply did. As Altinity and Imply released detailed SSB performance results on denormalized data, we followed suit. RocksDB divides data into blocks. Rockset stores its indexes on RocksDB.
While the prediction target varies depending on a hotel’s goals and the type of dataaccessible, there are two primary steps to benchmark as part of maximizing profit. For machine learning models to predict ADR effectively, a comprehensive understanding of these variables is required in the datapreparation stage.
By examining these factors, organizations can make informed decisions on which approach best suits their data analysis and decision-making needs. Parameter Data Mining Business Intelligence (BI) Definition The process of uncovering patterns, relationships, and insights from extensive datasets.
We’re introducing a new Rockset Integration for Apache Kafka that offers native support for Confluent Cloud and Apache Kafka, making it simpler and faster to ingest streaming data for real-time analytics. Rockset indexes the entire data stream so when new fields are added, they are immediately exposed and made queryable using SQL.
csv) – They are simplified text fields with rows of data. Database SQL database Access database Oracle database IBM Netezza MySQL database Sybase database Power Platform Power BI dataset Dataflows 4. Advanced Analytics and AI with Azure: Power BI requirements for dataflows can store data in Azure data lake storage Gen2.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















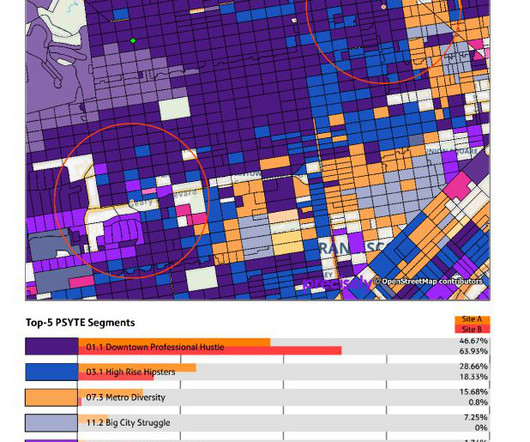





























Let's personalize your content