This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Databases come in a variety of formats for different use cases. The default association with the term "database" is relational engines, but non-relational engines are also used quite widely. Can you describe what constitutes a NoSQL database? If you were to start from scratch today, what database would you build?
Modern IT environments require comprehensive data for successful AIOps, that includes incorporating data from legacy systems like IBM i and IBM Z into ITOps platforms. AIOps presents enormous promise, but many organizations face hurdles in its implementation: Complex ecosystems made of multiple, fragmented systems that lack interoperability.
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. and hand-rolled C -code.
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. As you have gone through successive migration projects, how has that influenced the ways that you think about architecting data systems?
Think your customers will pay more for data visualizations in your application? Five years ago they may have. But today, dashboards and visualizations have become table stakes. Discover which features will differentiate your application and maximize the ROI of your embedded analytics. Brought to you by Logi Analytics.
Traditionally, answering this question would require expensive GIS (Geographic Information Systems) software or complex database setups. Today, DuckDB offers a simpler, more accessible approach for data engineers to tackle spatial problems without specialized infrastructure.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
Summary A significant portion of data workflows involve storing and processing information in database engines. Your host is Tobias Macey and today I'm welcoming back Gleb Mezhanskiy to talk about how to reconcile data in database environments Interview Introduction How did you get involved in the area of data management?
Summary Building a database engine requires a substantial amount of engineering effort and time investment. Over the decades of research and development into building these software systems there are a number of common components that are shared across implementations. This was the core of your recent re-write of the InfluxDB engine.
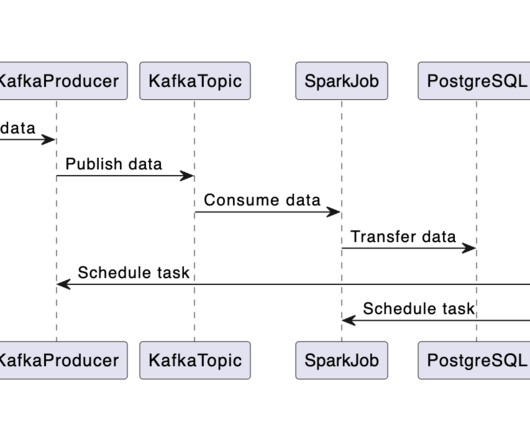
Data transfer systems are a critical component of data enablement, and building them to support large volumes of information is a complex endeavor. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data.
These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. The simple idea was, hey how can we get more value from the transactional data in our operational systems spanning finance, sales, customer relationship management, and other siloed functions.
Data storage has been evolving, from databases to data warehouses and expansive data lakes, with each architecture responding to different business and data needs. Traditional databases excelled at structured data and transactional workloads but struggled with performance at scale as data volumes grew.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products. Hack, C++, Python, etc.)
Summary The purpose of business intelligence systems is to allow anyone in the business to access and decode data to help them make informed decisions. Support Data Engineering Podcast Summary The purpose of business intelligence systems is to allow anyone in the business to access and decode data to help them make informed decisions.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. The current database includes 2,000 server types in 130 regions and 340 zones. Results are stored in git and their database, together with benchmarking metadata. Each benchmarking task is evaluated sequentially.
From Sella’s status page : “Following the installation of an update to the operating system and related firmware which led to an unstable situation. The changes messed up all major databases in some unexpected way. Still, I’m puzzled by how long the system has been down.
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it.
In 2020, anticipating the growing needs of the business and to simplify our storage offerings, we decided to consolidate our different key-value systems in the company into a single unified service called KVStore. Additionally, the last section explains how this new database supports a key platform in the product.
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data. It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of Big Data Storage with HDFS appeared first on Analytics Vidhya.
Todays organizations have access to more data than ever before, and consequently are faced with the challenge of determining how to transform this tremendous stream of real-time information into actionable insights. Encryption, access controls, and regulatory compliance (HIPAA, GDPR, etc.) patient records or geolocation data).
A consolidated data system to accommodate a big(ger) WHOOP When a company experiences exponential growth over a short period, it’s easy for its data foundation to feel a bit like it was built on the fly. This blog post is the second in a three-part series on migrations. million in cost savings annually.
In the early 90’s, DOS programs like the ones my company made had its own Text UI screen rendering system. This rendering system was easy for me to understand, even on day one. Our rendering system was very memory inefficient, but that could be fixed. By doing so, I got to see every screen of the system.
Unify transactional and analytical workloads in Snowflake for greater simplicity Many businesses must maintain two separate databases: one to handle transactional workloads and another for analytical workloads. Sensitive data can have enormous value but is oftentimes locked down due to privacy requirements.
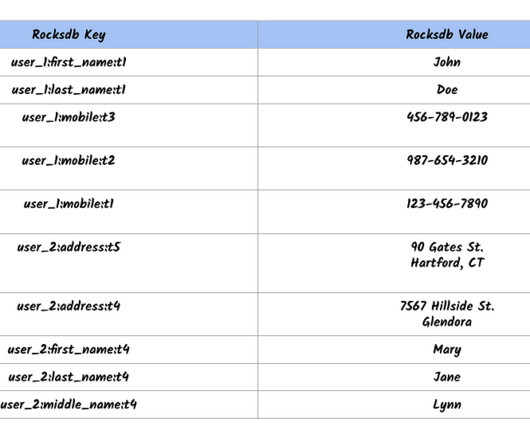
Change Data Capture (CDC) is a crucial technology that enables organizations to efficiently track and capture changes in their databases. In this blog post, we’ll explore what CDC is, why it’s important, and our journey of implementing Generic CDC solutions for all online databases at Pinterest. What is Change Data Capture?
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. Get all of the details and try the new product today at dataengineeringpodcast.com/rudderstack You shouldn't have to throw away the database to build with fast-changing data.
Were sharing details about Glean , Metas open source system for collecting, deriving and working with facts about source code. In this blog post well talk about why a system like Glean is important, explain the rationale for Gleans design, and run through some of the ways were using Glean to supercharge our developer tooling at Meta.
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. Then you begin researching database objects and find a couple of views, but there are some inconsistencies between them so you do not know which one to use. Your first step might be to locate the orders. Does it sound familiar?
A quick summary of these technologies: Prometheus : a time series database. A very popular open-source solution for systems and services monitoring. A fast and open-source column-oriented database management system, which is a popular choice for log management. It evaluates rules and can trigger alerts.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. What is Atlas?
This involves getting data from an API and storing it in a PostgreSQL database. In the second phase, we’ll develop an application that uses a language model to interact with this database. The second article, which will come later, will delve into creating agents using tools like LangChain to communicate with external databases.
Optimize performance and cost with a broader range of model options Cortex AI provides easy access to industry-leading models via LLM functions or REST APIs, enabling you to focus on driving generative AI innovations. We offer a broad selection of models in various sizes, context window lengths and language supports.
Our hope is that making salary ranges more accessible on Comprehensive.io For AI, we’ve built a system to efficiently use GPT-4 for this purpose, including auto-crafting prompts and performing pre and post-processing. on the backend, and Postgres for database storage.” ” How does Comprehensive.io
Astasia Myers: The three components of the unstructured data stack LLMs and vector databases significantly improved the ability to process and understand unstructured data. I never thought of PDF as a self-contained document database, but that seems a reality that we can’t deny. What are you waiting for?
Furthermore, most vendors require valuable time and resources for cluster spin-up and spin-down, disruptive upgrades, code refactoring or even migrations to new editions to access features such as serverless capabilities and performance improvements.
For transactional databases, it’s mostly the Microsoft SQL Server, but also other databases like PostgreSQL, ScyllaDB and Couchbase. queries per second as total load, spread across its managed database-as-a-service (DBAAS.) It uses Spark for the data platform. At peak load, Agoda sees around 7.5M
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. Can you describe what RisingWave is and the story behind it?
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. This foundational layer is a repository for various data types, from transaction logs and sensor data to social media feeds and system logs.
Different roles and tasks in the business need their own ways to access and analyze the data in the organization. In order to enable this use case, while maintaining a single point of access, the semantic layer has evolved as a technological solution to the problem. dbt, BI, warehouse marts, etc.)
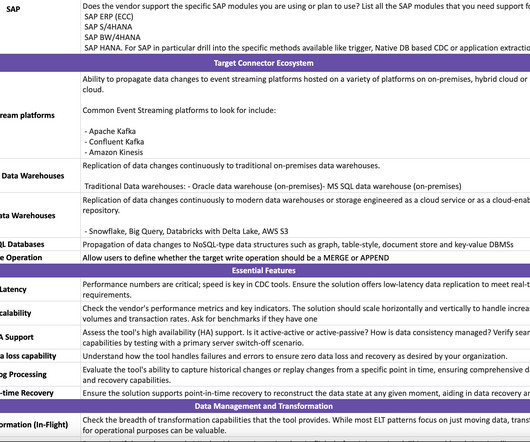
CDC Evaluation Guide Google Sheet Link: [link] CDC Evaluation Guide Github Link: [link] Change Data Capture (CDC) is a powerful technology in data engineering that allows for continuously capturing changes (inserts, updates, and deletes) made to source systems. However, managing data consistency across microservices can be challenging.
TL;DR Take advantage of old school database tricks, like ENUM data types, and column constraints. Some positives (Microsoft Access comes to mind), but some are questionable at best, such as traditional data design principles and data quality and validation at ingestion. Lets get toit! Generate data lineage with one small Pythonscript.
The answer lies in unstructured data processing—a field that powers modern artificial intelligence (AI) systems. To address these challenges, AI Data Engineers have emerged as key players, designing scalable data workflows that fuel the next generation of AI systems. Experience with vector databases (e.g.,
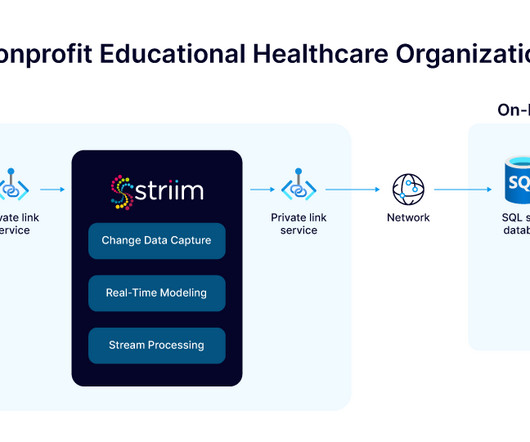
A nonprofit educational healthcare organization is faced with the challenge of modernizing its critical systems while ensuring uninterrupted access to essential services. However, while the SIS migration was a significant step forward, the institution’s on-premise SQL Server systems remained vital.
Ensure the provider supports the infrastructure necessary for your data needs, such as managed databases, storage, and data pipeline services. Leverage Built-In Partitioning Features: Use built-in features provided by databases like Snowflake or Databricks to automatically partition large datasets.
To address this shortcoming Datorios created an observability platform for Flink that brings visibility to the internals of this popular stream processing system. How have the requirements of generative AI shifted the demand for streaming data systems? What role does Flink play in the architecture of generative AI systems?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content