This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex.
In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Like Hadoop, it aims to tackle scalability, cost, speed, and data silos.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your raw data and transformed datasets optimized for AI-powered analytics with ThoughtSpot. Set refresh schedules as needed.
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. link] Meta: Data logs - The latest evolution in Meta’s access tools Meta writes about its access tool's system design, which helps export individual users’ access logs.
Open Context is an open accessdata publishing service for archaeology. It started because we need better ways of dissminating structureddata and digital media than is possible with conventional articles, books and reports. What are your protocols for determining which data sets you will work with?
Then, based on this information from the sample, defect or abnormality the rate for whole dataset is considered. This process of inferring the information from sample data is known as ‘inferential statistics.’ A database is a structureddata collection that is stored and accessed electronically.
The following are key attributes of our platform that set Cloudera apart: Unlock the Value of Data While Accelerating Analytics and AI The data lakehouse revolutionizes the ability to unlock the power of data. Adopt Data Mesh to Power the New Wave of AI Data is evolving from a valuable asset to being treated as a product.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. High latency of dataaccess. No real-time data processing.
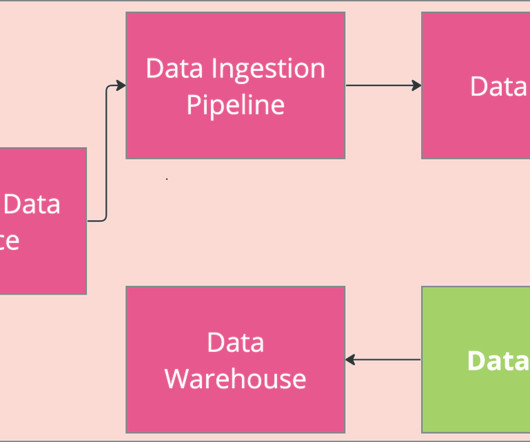
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. In an ETL-based architecture, data is first extracted from source systems, then transformed into a structured format, and finally loaded into data stores, typically data warehouses.
Netflix Scheduler is built on top of Meson which is a general purpose workflow orchestration and scheduling framework to execute and manage the lifecycle of the data workflow. Bulldozer makes data warehouse tables more accessible to different microservices and reduces each individual team’s burden to build their own solutions.
As mentioned in my previous blog on the topic , the recent shift to remote working has seen an increase in conversations around how data is managed. Toolsets and strategies have had to shift to ensure controlled access to data. It established a data governance framework within its enterprise data lake.
When it comes to the early stages in the data science process, data scientists often find themselves jumping between a wide range of tooling. First of all, there’s the question of what data is currently available within their organization, where it is, and how it can be accessed.
In modern enterprises, the exponential growth of data means organizational knowledge is distributed across multiple formats, ranging from structureddata stores such as data warehouses to multi-format data stores like data lakes.
Prerequisites Before you begin with few-shot learning, make sure you have the following: Access to a High-Powered GPU: Use a strong NVIDIA GPU, like the H100 or A100-80G, to run deep learning models effectively. Access to Cloud-Based Resources (Optional): If you don’t have a powerful GPU, you might want to use cloud services.
Typically, as shown in the image above, Dataform takes raw data, transform it with all the engineering best practices and output a properly structureddata ready for consumption. In Part 2, I would provide a walkthrough of the Terraform setup showing how to implement the least access control when provisioning Dataform.
paintings, songs, code) Historical data relevant to the prediction task (e.g., Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data.
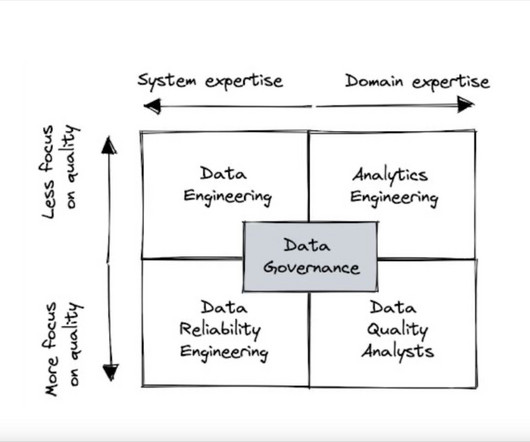
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Having the data engineering team lead the response to data quality is by far the most common pattern. It is deployed by about half of all organizations that use a modern data stack.
Now, let’s take a closer look at the strengths and weaknesses of the most popular data quality team structures. Data engineering Photo by Luke Chesser on Unsplash Having the data engineering team lead the response to data quality is by far the most common pattern. Quality falls under their remit as well.
Lesson 5: Splitting tasks horizontally reduces runtime Lets say we have two tasks we want to perform (pink and blue) on a large dataset. For example, when theres an issue, only the ML, BE, or engineers have access to the AI stack, system, and logs to understand the issue, and only the data scientists have the expertise to actually solve it.
Lesson 5: Splitting tasks horizontally reduces runtime Lets say we have two tasks we want to perform (pink and blue) on a large dataset. For example, when theres an issue, only the ML, BE, or engineers have access to the AI stack, system, and logs to understand the issue, and only the data scientists have the expertise to actually solve it.
According to the Cybercrime Magazine, the global data storage is projected to be 200+ zettabytes (1 zettabyte = 10 12 gigabytes) by 2025, including the data stored on the cloud, personal devices, and public and private IT infrastructures. The dataset can be either structured or unstructured or both.
Big Data vs Small Data: Volume Big Data refers to large volumes of data, typically in the order of terabytes or petabytes. It involves processing and analyzing massive datasets that cannot be managed with traditional data processing techniques.
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structureddata and the file system underneath is Colossus, the distributed file system by Google. Also, storage is much cheaper than compute and that means: With pre-joined datasets, you exchange compute for storage resources!
The motivation for Machine Unlearning is critical from the privacy perspective and for model correction, fixing outdated knowledge, and access revocation of the training dataset. link] Daniel Beach: Delta Lake - Map and Array data types Having a well-structureddata model is always great, but we often handle semi-structureddata.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Data warehousing offers several advantages.
We index only top-tier tables, promoting the use of these higher-quality datasets. I strongly believe the concept of Data Product will play a bigger role in data engineering. The highlight for me is, There is an ongoing table standardization effort at Pinterest to add tiering for the tables.
No Transformation: The input layer only passes data on to the hidden layer below; it does not process or alter the data in any way. Dimensionality: The number of characteristics in the dataset is directly proportional to the number of neurons in the input layer. How are neural networks used in AI? Is GAN a neural network?
Parameter Data Mining Business Intelligence (BI) Definition The process of uncovering patterns, relationships, and insights from extensive datasets. Process of analyzing, collecting, and presenting data to support decision-making. Focus Exploration and discovery of hidden patterns and trends in data.
Big data has revolutionized the world of data science altogether. With the help of big data analytics, we can gain insights from large datasets and reveal previously concealed patterns, trends, and correlations. Learn more about the 4 Vs of big data with examples by going for the Big Data certification online course.
Using easy-to-define policies, Replication Manager solves one of the biggest barriers for the customers in their cloud adoption journey by allowing them to move both tables/structureddata and files/unstructured data to the CDP cloud of their choice easily. Specification of access conditions for specific users and groups.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Data storing and processing is nothing new; organizations have been doing it for a few decades to reap valuable insights. Compared to that, Big Data is a much more recently derived term. So, what exactly is the difference between Traditional Data and Big Data? This is a good approach as it allows less space for error.
In an identity/access management application, it’s the relationships between roles and their privileges that matters most. If you’ve found yourself needing to write very large JOIN statements or dealing with long paths through your data, then you are probably facing a graph problem. Relationships act like verbs in your graph.
Perform iteration with enumerate() instead of range() Consider a situation during a coding interview: You have a list of elements, and you have to iterate over the list with the access to both the indices and values. Replace all integers divisible by 5 with “buzz”. Replace all integers divisible by 3 and 5 with “fizzbuzz”.
A single car connected to the Internet with a telematics device plugged in generates and transmits 25 gigabytes of data hourly at a near-constant velocity. And most of this data has to be handled in real-time or near real-time. Variety is the vector showing the diversity of Big Data. What is Big Data analytics?
Overwhelmed with log files and sensor data? It is a cloud-based service by Amazon Web Services (AWS) that simplifies processing large, distributed datasets using popular open-source frameworks, including Apache Hadoop and Spark. Businesses can run these workflows on a recurring basis, which keeps data fresh and analysis-ready.
In summary, data extraction is a fundamental step in data-driven decision-making and analytics, enabling the exploration and utilization of valuable insights within an organization's data ecosystem. What is the purpose of extracting data? The process of discovering patterns, trends, and insights within large datasets.
The recommendation models improved engagement when the models had access to more recent actions of its users. Data that used to be batch-loaded daily into Hadoop for model serving started to get loaded continuously, at first hourly and then in fifteen minutes intervals. Why is that?
The datasets are usually present in Hadoop Distributed File Systems and other databases integrated with the platform. Hive is built on top of Hadoop and provides the measures to read, write, and manage the data. Apache Spark , on the other hand, is an analytics framework to process high-volume datasets.
We’ll particularly explore data collection approaches and tools for analytics and machine learning projects. What is data collection? It’s the first and essential stage of data-related activities and projects, including business intelligence , machine learning , and big data analytics. No wonder only 0.5
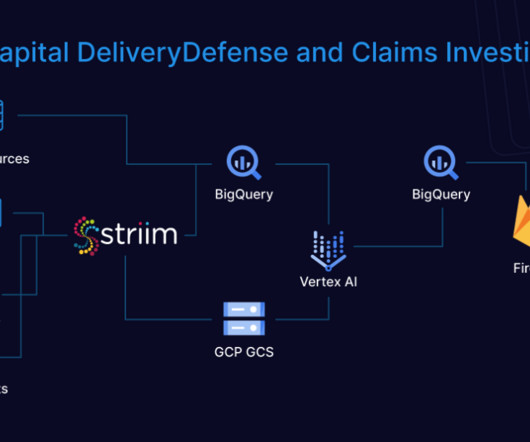
UPS Capital recognizes the challenges faced by its customers in securing their package delivery ecosystem and is harnessing digital capabilities and dataaccess to redefine traditional approaches, ensuring improved customer experiences and combating shipping loss.
Instead, working on a sentiment analysis project with real datasets will help you stand out in job applications and improve your chances of receiving a call back from your dream company. The dataset for Amazon Product Reviews: Amazon Product Reviews Dataset. Beginners can use the small IMDb reviews dataset to test their skills.
Google AI: The Data Cards Playbook: A Toolkit for Transparency in Dataset Documentation Google published Data Cards , a dataset documentation framework aimed at increasing transparency across dataset lifecycles. link] The short YouTube video gives a nice overview of the Data Cards.
Furthermore, PySpark allows you to interact with Resilient Distributed Datasets (RDDs) in Apache Spark and Python. Because of its interoperability, it is the best framework for processing large datasets. Easy Processing- PySpark enables us to process data rapidly, around 100 times quicker in memory and ten times faster on storage.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content