This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
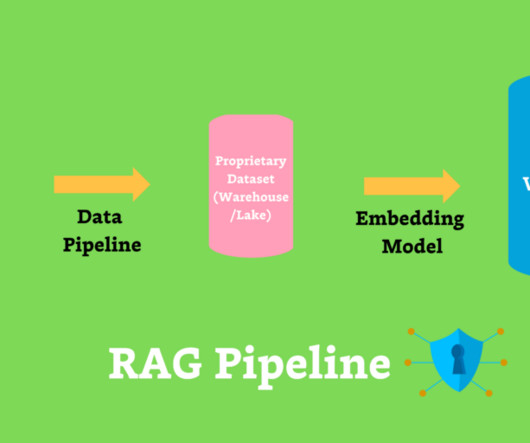
The Critical Role of AI Data Engineers in a Data-Driven World How does a chatbot seamlessly interpret your questions? The answer lies in unstructureddata processing—a field that powers modern artificial intelligence (AI) systems. Adding to this complexity is the sheer volume of data generated daily.
Agents need to access an organization's ever-growing structured and unstructureddata to be effective and reliable. As data connections expand, managing access controls and efficiently retrieving accurate informationwhile maintaining strict privacy protocolsbecomes increasingly complex.
Datasets are the repository of information that is required to solve a particular type of problem. Also called data storage areas , they help users to understand the essential insights about the information they represent. Datasets play a crucial role and are at the heart of all Machine Learning models.
In this episode Davit Buniatyan, founder and CEO of Activeloop, explains why he is spending his time and energy on building a platform to simplify the work of getting your unstructureddata ready for machine learning. Satori has built the first DataSecOps Platform that streamlines dataaccess and security.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms.
In today’s data-driven world, organizations amass vast amounts of information that can unlock significant insights and inform decision-making. A staggering 80 percent of this digital treasure trove is unstructureddata, which lacks a pre-defined format or organization. What is unstructureddata?
MoEs necessitate less compute for pre-training compared to dense models, facilitating the scaling of model and dataset size within similar computational budgets. link] QuantumBlack: Solving data quality for gen AI applications Unstructureddata processing is a top priority for enterprises that want to harness the power of GenAI.
In the mid-2000s, Hadoop emerged as a groundbreaking solution for processing massive datasets. It promised to address key pain points: Scaling: Handling ever-increasing data volumes. Speed: Accelerating data insights. Like Hadoop, it aims to tackle scalability, cost, speed, and data silos.
Are you struggling to manage the ever-increasing volume and variety of data in today’s constantly evolving landscape of modern data architectures? Bucket Layouts in Apache Ozone Interoperability between FS and S3 API Users can store their data in Apache Ozone and can access the data with multiple protocols.
We scored the highest in hybrid, intercloud, and multi-cloud capabilities because we are the only vendor in the market with a true hybrid data platform that can run on any cloud including private cloud to deliver a seamless, unified experience for all data, wherever it lies. Unlike software, ML models need continuous tuning.
Organizations have continued to accumulate large quantities of unstructureddata, ranging from text documents to multimedia content to machine and sensor data. Comprehending and understanding how to leverage unstructureddata has remained challenging and costly, requiring technical depth and domain expertise.
Regardless of industry, data is considered a valuable resource that helps companies outperform their rivals, and healthcare is not an exception. In this post, we’ll briefly discuss challenges you face when working with medical data and make an overview of publucly available healthcare datasets, along with practical tasks they help solve.
As mentioned in my previous blog on the topic , the recent shift to remote working has seen an increase in conversations around how data is managed. Toolsets and strategies have had to shift to ensure controlled access to data. It established a data governance framework within its enterprise data lake.
For example, when processing a large dataset, you can add more EC2 worker nodes to speed up the task. Data transfers between regions or zones incur additional costs that can outweigh the cost savings, not to mention the impact on performance. Databricks clusters contain one driver node and one or more worker nodes. M6i , M7g ).
Decoupling of Storage and Compute : Data lakes allow observability tools to run alongside core data pipelines without competing for resources by separating storage from compute resources. This opens up new possibilities for monitoring and diagnosing data issues across various sources.
We also integrate GenAI into the Monte Carlo product itself to make the lives of data teams easier through AI-powered monitor recommendations , fixes with AI, and soon, Gen-AI powered root cause analysis (stay tuned for more on that soon). This workflow creates a good balance between speed, cost, and quality of results.
We also integrate GenAI into the Monte Carlo product itself to make the lives of data teams easier through AI-powered monitor recommendations , fixes with AI, and soon, Gen-AI powered root cause analysis (stay tuned for more on that soon). This workflow creates a good balance between speed, cost, and quality of results.
Imagine having self-service access to all business data, anywhere it may be, and being able to explore it all at once. Imagine quickly answering burning business questions nearly instantly, without waiting for data to be found, shared, and ingested. An architectural innovation: Cloudera Data Platform (CDP) and Apache Iceberg.
In my opinion, enterprise ready generative AI must be: Secure & private: Your AI application must ensure that your data is secure, private, and compliant, with proper access controls. We *know* what we’re putting in (raw, often unstructureddata) and we *know* what we’re getting out, but we don’t know how it got there.
paintings, songs, code) Historical data relevant to the prediction task (e.g., Generative AI leverages the power of deep learning to build complex statistical models that process and mimic the structures present in different types of data.
Apache Hadoop is an open-source framework written in Java for distributed storage and processing of huge datasets. The keyword here is distributed since the data quantities in question are too large to be accommodated and analyzed by a single computer. High latency of dataaccess. No real-time data processing.
Attribute-based access control and SparkSQL fine-grained access control. Lineage and chain of custody, advanced data discovery and business glossary. Store and access schemas across clusters and rebalance clusters with Cruise Control. Relevance-based text search over unstructureddata (text, pdf,jpg, …).
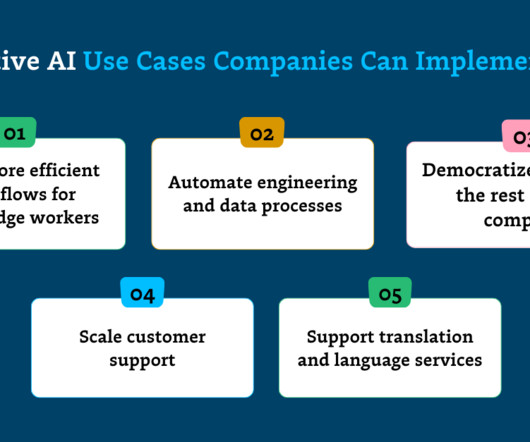
Given LLMs’ capacity to understand and extract insights from unstructureddata, businesses are finding value in summarizing, analyzing, searching, and surfacing insights from large amounts of internal information. Let’s explore how a few key sectors are putting gen AI to use.
Scale Existing Python Code with Ray Python is popular among data scientists and developers because it is user-friendly and offers extensive built-in data processing libraries. For analyzing huge datasets, they want to employ familiar Python primitive types. Glue works absolutely fine with structured as well as unstructureddata.
We’ll build a data architecture to support our racing team starting from the three canonical layers : Data Lake, Data Warehouse, and Data Mart. Data Lake A data lake would serve as a repository for raw and unstructureddata generated from various sources within the Formula 1 ecosystem: telemetry data from the cars (e.g.
The tool processes both structured and unstructureddata associated with patients to evaluate the likelihood of their leaving for a home within 24 hours. The main sources of such data are electronic health record ( EHR ) systems which capture tons of important details. Inpatient data anonymization. Factors impacting LOS.
Limit access and capabilities initially. Improve dataset quality. Ensure you can trust your data by using only diverse, high-quality training data that represents different demographics and viewpoints. Our government leaders had several suggestions: Start small. Start with narrow, low-risk use cases.
DataOps needs a directed graph-based workflow that contains all the dataaccess, integration, model and visualization steps in the data analytic production process. It orchestrates complex pipelines, toolchains, and tests across teams, locations, and data centers. Meta-Orchestration . Other Vendors Talking DataOps.
Python UnstructuredData Processing (PuPr) – Unstructureddata processing is now natively supported with Python. External Network Access (PrPr) – Allows users to seamlessly connect to external endpoints from their Snowpark code (UDFs/UDTFs and Stored procedures) while maintaining high security and governance.
When screening resumes, most hiring managers prioritize candidates who have actual experience working on data engineering projects. Top Data Engineering Projects with Source Code Data engineers make unprocessed dataaccessible and functional for other data professionals. Which queries do you have?
This facilitates improved collaboration across departments via data virtualization, which allows users to view and analyze data without needing to move or replicate it. And through this partnership, we can offer clients cost-effective AI models and well-governed datasets as this industry charges into the future.”
Organizations across industries moved beyond experimental phases to implement production-ready GenAI solutions within their data infrastructure. Natural Language Interfaces Companies like Uber, Pinterest, and Intuit adopted sophisticated text-to-SQL interfaces, democratizing dataaccess across their organizations.
Linear Algebra Linear Algebra is a mathematical subject that is very useful in data science and machine learning. A dataset is frequently represented as a matrix. Statistics Statistics are at the heart of complex machine learning algorithms in data science, identifying and converting data patterns into actionable evidence.
Big data has revolutionized the world of data science altogether. With the help of big data analytics, we can gain insights from large datasets and reveal previously concealed patterns, trends, and correlations. Learn more about the 4 Vs of big data with examples by going for the Big Data certification online course.
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Data warehouses offer high performance and scalability, enabling organizations to manage large volumes of structured data efficiently.
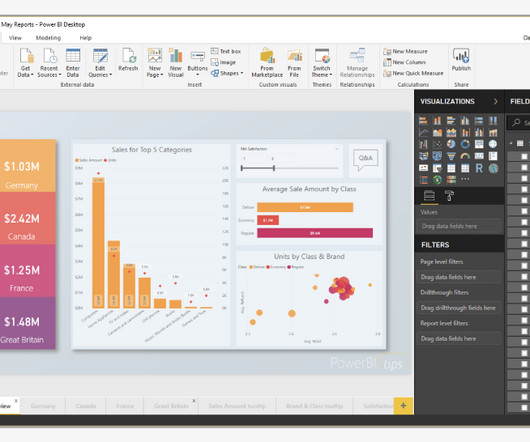
Power BI Desktop Power BI Desktop is free software that can be downloaded and installed to build reports by accessingdata easily without the need for advanced report designing or query skills to build a report. Multiple Data Sources Multiple Data Sources support various data sources like Excel, CSV, SQL Server, Web files, etc.
[link] Matt Turck: Full Steam Ahead: The 2024 MAD (Machine Learning, AI & Data) Landscape Coninue the week of insights into the world of data & AI landscape, the 2024 MAD landscape is out. We index only top-tier tables, promoting the use of these higher-quality datasets.
In the modern data-driven landscape, organizations continuously explore avenues to derive meaningful insights from the immense volume of information available. Two popular approaches that have emerged in recent years are data warehouse and big data. Big data offers several advantages.
In the present-day world, almost all industries are generating humongous amounts of data, which are highly crucial for the future decisions that an organization has to make. This massive amount of data is referred to as “big data,” which comprises large amounts of data, including structured and unstructureddata that has to be processed.
According to the Cybercrime Magazine, the global data storage is projected to be 200+ zettabytes (1 zettabyte = 10 12 gigabytes) by 2025, including the data stored on the cloud, personal devices, and public and private IT infrastructures. The dataset can be either structured or unstructured or both.
Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. The data lakehouse’s semantic layer also helps to simplify and open dataaccess in an organization.
Data lakehouse architecture combines the benefits of data warehouses and data lakes, bringing together the structure and performance of a data warehouse with the flexibility of a data lake. The data lakehouse’s semantic layer also helps to simplify and open dataaccess in an organization.
If we look at history, the data that was generated earlier was primarily structured and small in its outlook. A simple usage of Business Intelligence (BI) would be enough to analyze such datasets. However, as we progressed, data became complicated, more unstructured, or, in most cases, semi-structured.
No Transformation: The input layer only passes data on to the hidden layer below; it does not process or alter the data in any way. Dimensionality: The number of characteristics in the dataset is directly proportional to the number of neurons in the input layer. How are neural networks used in AI?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content