Designing and testing for accessibility in GIS and mapping
ArcGIS
MAY 13, 2024
Review best practices for designing and testing for accessibility maps and apps throughout the ArcGIS system during the development process.
This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
 Accessible Designing Systems
Accessible Designing Systems 
ArcGIS
MAY 13, 2024
Review best practices for designing and testing for accessibility maps and apps throughout the ArcGIS system during the development process.

Data Engineering Podcast
DECEMBER 3, 2023
Data transfer systems are a critical component of data enablement, and building them to support large volumes of information is a complex endeavor. With Datafold, you can seamlessly plan, translate, and validate data across systems, massively accelerating your migration project. When is DoubleCloud Data Transfer the wrong choice?

ArcGIS
MAY 13, 2024
Review best practices for designing and testing for accessibility maps and apps throughout the ArcGIS system during the development process.

Data Engineering Podcast
APRIL 14, 2024
In this episode Oren Eini, CEO and creator of RavenDB, explores the nuances of relational vs. non-relational engines, and the strategies for designing a non-relational database. When designing and building a database, what are the initial set of questions that need to be answered? Can you describe what constitutes a NoSQL database?

Data Engineering Podcast
MAY 26, 2024
Summary Any software system that survives long enough will require some form of migration or evolution. When that system is responsible for the data layer the process becomes more challenging. As you have gone through successive migration projects, how has that influenced the ways that you think about architecting data systems?

Engineering at Meta
APRIL 6, 2023
Buck2, our new open source, large-scale build system , is now available on GitHub. Buck2 is an extensible and performant build system written in Rust and designed to make your build experience faster and more efficient. In particular, we support Sapling-based file systems. Why rebuild Buck?

Knowledge Hut
JANUARY 11, 2024
In today's digital age, the rise of the internet has given us two powerful mediums for expressing creativity: web design & graphic design. Web design involves creating websites, interfaces, & online applications while graphic design entails creating visual designs for print & digital media.

Tweag
JULY 5, 2023
Buck2 is a from-scratch rewrite of Buck , a polyglot, monorepo build system that was developed and used at Meta (Facebook), and shares a few similarities with Bazel. As you may know, the Scalable Builds Group at Tweag has a strong interest in such scalable build systems. Meta recently announced they have made Buck2 open-source.

The Pragmatic Engineer
NOVEMBER 21, 2023
If you had a continuous deployment system up and running around 2010, you were ahead of the pack: but today it’s considered strange if your team would not have this for things like web applications. We dabbled in network engineering, database management, and system administration. Subscribe here. and hand-rolled C -code.

Knowledge Hut
MARCH 22, 2024
I have comprehensively analyzed the area of physical security, particularly the ongoing discussion surrounding fail safe vs fail-safe secure electric strike locking systems. On the other hand, fail-secure systems focus on maintaining continuous security, keeping doors locked even in difficult conditions to protect assets.

Data Engineering Podcast
MAY 18, 2024
Summary The purpose of business intelligence systems is to allow anyone in the business to access and decode data to help them make informed decisions. Powered by Trino, the query engine Apache Iceberg was designed for, Starburst is an open platform with support for all table formats including Apache Iceberg, Hive, and Delta Lake.

Start Data Engineering
MAY 28, 2024
Use DuckDB to process data, not for multiple users to access data 4.2. Distributed systems are scalable, resilient to failures, & designed for high availability 4.5. Building efficient data pipelines with DuckDB 4.1. Cost calculation: DuckDB + Ephemeral VMs = dirt cheap data processing 4.3. Processing data less than 100GB?

Netflix Tech
MARCH 7, 2024
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.

Striim
SEPTEMBER 11, 2024
A data pipeline is a systematic sequence of components designed to automate the extraction, organization, transfer, transformation, and processing of data from one or more sources to a designated destination. Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures.

DoorDash Engineering
FEBRUARY 22, 2023
Additionally, the Fulfillment engineering team recently released this article about how they use the CockroachDB to scale their system. We also got similar benefits by using the CockroachDB in our system. This system would ensure that we could provide an accurate and fresh view of all sellable items in stores to our customers.

Data Engineering Podcast
NOVEMBER 20, 2022
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. The biggest challenge with modern data systems is understanding what data you have, where it is located, and who is using it.

Data Engineering Podcast
FEBRUARY 18, 2024
What are the pain points that are still prevalent in lakehouse architectures as compared to warehouse or vertically integrated systems? What are the differences in terms of pipeline design/access and usage patterns when using a Trino/Iceberg lakehouse as compared to other popular warehouse/lakehouse structures?

Analytics Vidhya
FEBRUARY 6, 2023
Introduction HDFS (Hadoop Distributed File System) is not a traditional database but a distributed file system designed to store and process big data. It provides high-throughput access to data and is optimized for […] The post A Dive into the Basics of Big Data Storage with HDFS appeared first on Analytics Vidhya.

The Pragmatic Engineer
MARCH 12, 2024
Tools and approaches at our disposal, which didn’t exist in 1975, or were not widespread in 1995, include: Git – the now-dominant version control system used by much of the industry, with exceptions for projects with very large assets, like video games Code reviews : these became common in parallel with version control.
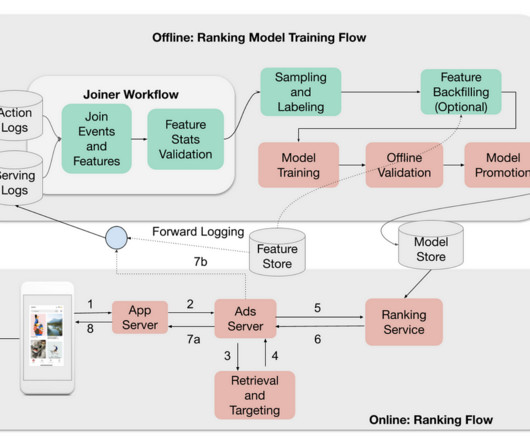
Pinterest Engineering
JANUARY 18, 2024
In particular, our machine learning powered ads ranking systems are trying to understand users’ engagement and conversion intent and promote the right ads to the right user at the right time. Specifically, such discrepancies unfold into the following scenarios: Bug-free scenario : Our ads ranking system is working bug-free.

Snowflake
MAY 16, 2024
Connecting government agencies through the power of integrated technologies By design, government and education programs are regulated and complex. Together, we drive success for our government partners, local and national businesses, and hundreds of thousands of families who can receive access to important academic support.

Data Engineering Podcast
DECEMBER 24, 2023
Summary Kafka has become a ubiquitous technology, offering a simple method for coordinating events and data across different systems. When a cluster's usage expands beyond the original designed capacity, what are the options/procedures for expanding that capacity? Operating it at scale, however, is notoriously challenging.

Data Engineering Weekly
SEPTEMBER 26, 2024
The collective design choices and ideas lead to a comprehensive overview of thinking about designing data infrastructure with a privacy-first approach. Privacy and access management within data infrastructure is not just a best practice; it's a necessity. Why care about privacy? Let's examine them in more detail.

Data Engineering Podcast
FEBRUARY 4, 2024
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. There are numerous stream processing engines, near-real-time database engines, streaming SQL systems, etc. How have the design and goals/scope changed since you first started working on it?

The Pragmatic Engineer
MARCH 19, 2024
Today, full subscribers got access to a comprehensive Senior-and-above tech compensation research. Source: Cognition So far, all we have is video demos, and accounts of those with access to this tool. In 1959, the programming language COBOL was designed by software engineer Grace Hopper. And COBOL was just one of many attempts.

The Pragmatic Engineer
OCTOBER 17, 2024
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. OpenSSL : the cryptography and SSL/TLS toolkit comes with a built-in performance benchmarking capability Lmbench : tools for performance analysis for UNIX/POSIX system.

Data Engineering Podcast
JUNE 30, 2024
Petr shares his journey from being an engineer to founding Synq, emphasizing the importance of treating data systems with the same rigor as engineering systems. He discusses the challenges and solutions in data reliability, including the need for transparency and ownership in data systems. Want to see Starburst in action?

The Pragmatic Engineer
SEPTEMBER 19, 2024
In the early 90’s, DOS programs like the ones my company made had its own Text UI screen rendering system. This rendering system was easy for me to understand, even on day one. Our rendering system was very memory inefficient, but that could be fixed. By doing so, I got to see every screen of the system.

Engineering at Meta
MARCH 12, 2024
We are sharing details on the hardware, network, storage, design, performance, and software that help us extract high throughput and reliability for various AI workloads. We use this cluster design for Llama 3 training. We have been openly designing our GPU hardware platforms beginning with our Big Sur platform in 2015.

The Pragmatic Engineer
APRIL 9, 2024
On top of the ability to post jobs, they had access to The Pragmatic Engineer Talent Collective. Companies stayed customers longer, as they were interested in having access to the "latest drops" in the talent collective. (A There was a similar trend in companies paying to access the talent collective and job board.

Data Engineering Podcast
JUNE 9, 2024
To address this shortcoming Datorios created an observability platform for Flink that brings visibility to the internals of this popular stream processing system. How have the requirements of generative AI shifted the demand for streaming data systems? What role does Flink play in the architecture of generative AI systems?

Snowflake
APRIL 24, 2024
Members of the Snowflake AI Research team pioneered systems such as ZeRO and DeepSpeed , PagedAttention / vLLM , and LLM360 which significantly reduced the cost of LLM training and inference, and open sourced them to make LLMs more accessible and cost-effective for the community. license provides ungated access to weights and code.
Engineering at Meta
JUNE 27, 2023
Sapling: Scaling version control Sapling is a version control system that can scale to huge sizes, but also emphasizes usability. There are three main components to Sapling – a server, a client, and a virtual file system. The final component is the virtual file system.

Data Engineering Podcast
APRIL 21, 2024
How have the design and goals of the product changed since you started it? How do you manage the personalization of the AI functionality in your system for each user/team? How have the design and goals of the product changed since you started it? Can you describe how you have architected the Shortwave platform?

Engineering at Meta
OCTOBER 15, 2024
At the Open Compute Project (OCP) Global Summit 2024, we’re showcasing our latest open AI hardware designs with the OCP community. These innovations include a new AI platform, cutting-edge open rack designs, and advanced network fabrics and components. By sharing our designs, we hope to inspire collaboration and foster innovation.
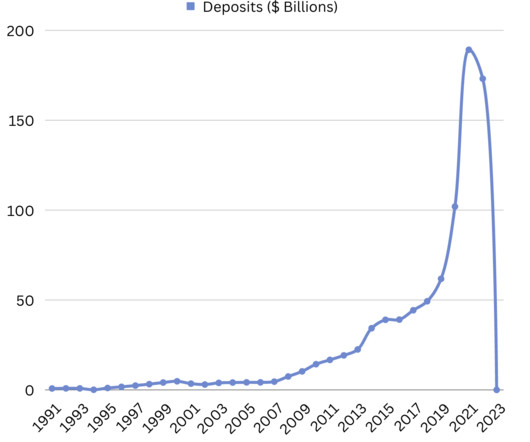
The Pragmatic Engineer
MARCH 13, 2023
The issue is that banks (not only SVB) aren’t designed to work like this: they cannot fulfil simultaneous requests for withdrawals by all (or even most) customers. The bank’s systems start to be overloaded to the point of customers not being able to log on and transfer. It's an all out bank run.

Engineering at Meta
DECEMBER 6, 2023
Our aim is to ensure that everyone’s personal messages on Messenger can only be accessed by the sender and the intended recipients, and that everyone can be sure the messages they receive are from an authentic sender. End-to-end encryption isn’t about the technology at its core.

Data Engineering Podcast
JUNE 16, 2024
For data engineers who battle to build and scale high quality data workflows on the data lake, Starburst is an end-to-end data lakehouse platform built on Trino, the query engine Apache Iceberg was designed for, with complete support for all table formats including Apache Iceberg, Hive, and Delta Lake. Want to see Starburst in action?

Data Engineering Podcast
JUNE 2, 2024
Summary Modern businesses aspire to be data driven, and technologists enjoy working through the challenge of building data systems to support that goal. number/scale of systems, types of data, AI) Data governance can often become an exercise in boiling the ocean. Trusted by teams of all sizes, including Comcast and Doordash.

phData: Data Engineering
NOVEMBER 8, 2024
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.

Robinhood
OCTOBER 10, 2024
When Robinhood was founded, we set out to build a platform that gives everyone access to the financial markets. Throughout the design process, we channeled the bold and disruptive spirit that defines Robinhood to create something completely different that elevates our brand and challenges the industry as a whole.

Data Engineering Podcast
FEBRUARY 25, 2024
Over the decades of research and development into building these software systems there are a number of common components that are shared across implementations. What were the design goals and constraints that led you to this architecture? What were the design goals and constraints that led you to this architecture?

Netflix Tech
NOVEMBER 12, 2024
By: Rajiv Shringi , Oleksii Tkachuk , Kartik Sathyanarayanan Introduction In our previous blog post, we introduced Netflix’s TimeSeries Abstraction , a distributed service designed to store and query large volumes of temporal event data with low millisecond latencies. Today, we’re excited to present the Distributed Counter Abstraction.

Data Engineering Podcast
MAY 12, 2024
The services and systems need to be kept up to date, but so does the code that controls their behavior. Powered by Trino, the query engine Apache Iceberg was designed for, Starburst is an open platform with support for all table formats including Apache Iceberg, Hive, and Delta Lake. Want to see Starburst in action?

Expert insights. Personalized for you.
We have resent the email to
Are you sure you want to cancel your subscriptions?





Let's personalize your content