This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A list to make evaluating ELT/ETLtools a bit less daunting Photo by Volodymyr Hryshchenko on Unsplash We’ve all been there: you’ve attended (many!) meetings with sales reps from all of the SaaS data integration tooling companies and are granted 14 day access to try their wares.
Apache Sqoop and Apache Flume are two popular open source etltools for hadoop that help organizations overcome the challenges encountered in data ingestion. Table of Contents Hadoop ETLtools: Sqoop vs Flume-Comparison of the two Best Data Ingestion Tools What is Sqoop in Hadoop?
The fact that ETLtools evolved to expose graphical interfaces seems like a detour in the history of data processing, and would certainly make for an interesting blog post of its own. Let’s highlight the fact that the abstractions exposed by traditional ETLtools are off-target.
Whether it is consuming log files, sensor metrics, and other unstructured data, most enterprises manage and deliver data to the data lake and leverage various applications like ETLtools, search engines, and databases for analysis.
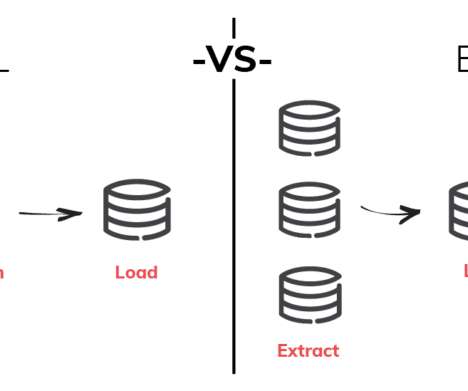
Integration facilitates seamless data flow and accessibility, which is crucial for real-time analytics and decision-making. Engineers often utilize ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) tools for data integration.
We’ll talk about when and why ETL becomes essential in your Snowflake journey and walk you through the process of choosing the right ETLtool. Our focus is to make your decision-making process smoother, helping you understand how to best integrate ETL into your data strategy. But first, a disclaimer.
Large-model AI is becoming more and more influential in the market, and with the well-known tech giants starting to introduce easy-access AI stacks, a lot of businesses are left feeling that although there may be a use for AI in their business, they’re unable to see what use cases it might help them with. Responsible use is key.
After, they leverage the power of the cloud warehouse to perform deep analysis, build predictive models, and feed BI tools and dashboards. However, data warehouses are only accessible to technical users who know how to write SQL. Reverse ETL sits on the opposite side. Why Does Your Business Need Reverse ETL?
Data lineage can be a tremendously useful tool for data engineering and analytics, but is often treated as an afterthought both because of the challenges in implementation and the fact that it has not been broadly available within organizations. Lineage is dependencies – What is upstream of the final data that we are accessing?
The process of data extraction from source systems, processing it for data transformation, and then putting it into a target data system is known as ETL, or Extract, Transform, and Load. ETL has typically been carried out utilizing data warehouses and on-premise ETLtools. But cloud computing is preferred over the other.
Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange. This indicates the growing use of the ETL process and various ETLtools and techniques across multiple industries.
Thus, almost every organization has access to large volumes of rich data and needs “experts” who can generate insights from this rich data. They use technologies like Storm or Spark, HDFS, MapReduce, Query Tools like Pig, Hive, and Impala, and NoSQL Databases like MongoDB, Cassandra, and HBase.
Data Integration and Transformation, A good understanding of various data integration and transformation techniques, like normalization, data cleansing, data validation, and data mapping, is necessary to become an ETL developer. Informatica PowerCenter: A widely used enterprise-level ETLtool for data integration, management, and quality.
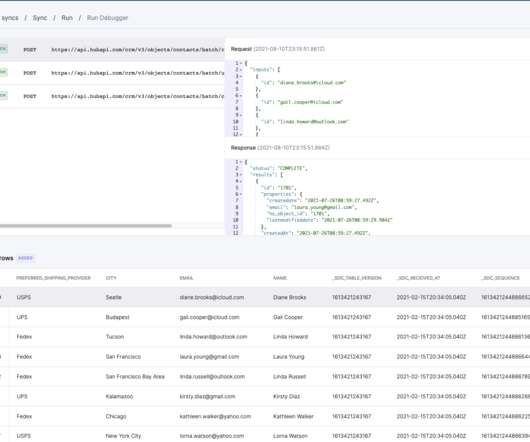
Data Ingestion Data ingestion is the first step of both ETL and data pipelines. In the ETL world, this is called data extraction, reflecting the initial effort to pull data out of source systems. ETLtools usually pride themselves on their ability to extract from many variations of source systems.
Impala only masquerades as an ETL pipeline tool: use NiFi or Airflow instead It is common for Cloudera Data Platform (CDP) users to ‘test’ pipeline development and creation with Impala because it facilitates fast, iterate development and testing. So which open source pipeline tool is better, NiFi or Airflow?
2: The majority of Flink shops are in earlier phases of maturity We talked to numerous developer teams who had migrated workloads from legacy ETLtools, Kafka streams, Spark streaming, or other tools for the efficiency and speed of Flink. Vendors making claims of being faster than Flink should be viewed with suspicion.
With Direct Connector, access the Data stores in Snowflake without moving or duplicating data in Salesforce. Business wants to move the data from Snowflake to Salesforce without any 3 rd party ETLtools. Initially we proposed Reverse Synch ETLtools, Data Import wizard or Data loader utility to ingest into Salesforce.
In other words, how can data analysts and engineers ensure that transformed, actionable data is actually available to access and use? Here’s where Reverse ETL and Data Observability can help teams go the extra mile when it comes to trusting your data products. Fortunately, there’s a better way: Reverse ETL. What is Reverse ETL?
Row Access Policies : A popular method of allowing access to specific data rows based on functional roles. These are accessible with account usage and organization usage schemas and within the information schema in every database you create.
A couple of important characteristics of a Data Warehouse at this time The ETLtools and Data Warehouse appliances are limited in scope. The footprint of people in an organization directly accessing the Data Warehouse is fairly limited; getting access to query the Data Warehouse directly is a privilege and a specialized skill.
Some sweets are presented on your display cases for quick access while the rest is kept in the storeroom. When dealing with dependent data marts, the central data warehouse already keeps data formatted and cleansed, so ETLtools will do little job. tables, indexes) and setting up data access structures. Hybrid data marts.
At the time, the data engineering team mainly used a data warehouse ETLtool called Ab Initio, and an MPP (Massively Parallel Processing) database for warehousing. We had a small office in Los Angeles focused on content, and significantly more employees at the headquarters in Los Gatos.
In the following examples, we’ll be using Looker, but most modern BI tools enable usage-based reporting in some form (Lightdash also has built in Usage Analytics , Tableau Cloud offers Admin Insights , and Mode’s Discovery Database offers access to usage data, just to name a few). Source: synq.io Source: secoda.co
") Apache Airflow , for example, is not an ETLtool per se but it helps to organize our ETL pipelines into a nice visualization of dependency graphs (DAGs) to describe the relationships between tasks. __version__) table_id = client.dataset(dataset_id).table(table_name) Data Mesh and metadata help to solve this problem.
Middleware can be anything—some custom glue code or framework, a messaging system like RabbitMQ, an ETLtool like Talend, an ESB like WSO2, or an event streaming platform like Apache Kafka. It’s also worth mentioning Confluent’s RBAC features, which allow role-based access control across the Confluent Platform.
The choice of tooling and infrastructure will depend on factors such as the organization’s size, budget, and industry as well as the types and use cases of the data. Data Pipeline vs ETL An ETL (Extract, Transform, and Load) system is a specific type of data pipeline that transforms and moves data across systems in batches.
Salesforce users want to have the access of Snowflake data without moving it. Or we can leverage third party ETLtools but for this scenario me and my colleague Gautam has focused on Salesforce product features. As per the need we don’t want to get data to be ingested into Salesforce from Snowflake.
For example, unlike traditional platforms with set schemas, data lakes adapt to frequently changing data structures at points where the data is loaded , accessed, and used. ELT The ETL to ELT to EtLT Evolution For many years, data warehouses with ETL and data lakes with ELT have evolved in parallel worlds.
The Data Warehouse(s) facilitates data ingestion and enables easy access for end-users. Normally, data mart is the layer where non-technical users may access the data or that feeds visualization layers. Furthermore, CLI or SQL access can foster a culture of data exploration and innovation within your organization.
For governance and security teams, the questions revolve around chain of custody, audit, metadata, access control, and lineage. We had to build the streaming data pipeline that new data has to move through before it can be persisted and then provide business teams access to that pipeline for them to build data products.”
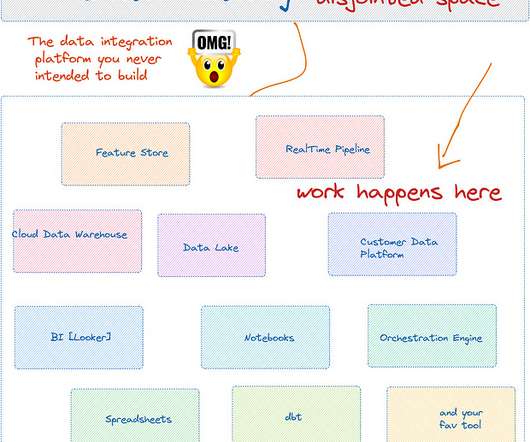
Additionally, Magpie reduces your team’s IT complexity by eliminating the need to use separate data catalog, data exploration, and ETLtools. The whole data engineering process takes place directly within the platform, and eliminates the need to switch between different systems and tools.
Protecting Data Integrity A range of data integrity tools and techniques are available to protect data from unauthorized modification and detect the occurrence of an unexpected change. Access controls are the standard method of protecting integrity by restricting who has access to data and who can alter the data.
Data engineering itself is a process of creating mechanisms for accessing data. The movement of data from its source to analytical tools for end users requires a whole infrastructure, and although this flow of data must be automated, building and maintaining it is a task of a data engineer. Providing data accesstools.
.” Though industry experts are still divided over the advantages and disadvantages of one over the other, we take a look at the top five reasons why ETL professionals should learn Hadoop. Having said that, the data professionals cannot afford to rest on their existing expertise of one or more of the ETLtools.
link] Meta: The Future of the data engineer — Part I Meta introduced a new term, “Accessible Analytics,” - self-describing to the extent that it doesn’t require specialized skills to draw meaningful insights from it. Analytical Engineering is the role often quoted for data engineers who do Accessible Analytics.
The growing number of disparate sources that business analysts and data scientists need access to further complicates efforts. Classic Extract, Transform, & Load (ETL) tools have this functionality, but they typically rely on batching or micro-batching as opposed to moving the data incrementally.
Put simply, it is the process of making raw data usable and accessible to data scientists, business analysts, and other team members who rely on data. Data engineers use this tool to ensure all data is validated, documented, and tested, and is therefore of high quality. Why Is Data Engineering Important? What Does A Data Engineer Do?
Below is a summary table highlighting the core benefits and drawbacks of certain ETLtooling options for getting spreadsheet data in your data warehouse. You’ll need to authenticate your Google Account using an OAuth or a service account key and provide the link of the Google Sheet you want to pull into your data warehouse.
Providing mechanisms to access and compare different versions. We define guidelines for version naming, retention, and access control, considering the impact on our ETL processes. Data Catalog Tools : Platforms such as Collibra and Alation offer versioning as part of their broader data governance and catalog features.
Around 1500 people across a wide range of roles, from accountants and financial controllers to top-level managers, rely on Fortum’s financial data, meaning it has to be highly accessible while remaining completely secure and compliant. The company also uses external tables to directly access the semi-structured data within Snowflake.
Web scraping tools can navigate web pages, locate desired content, and extract it for further analysis. API (Application Programming Interface) Access : Many platforms and services offer APIs that allow for systematic data retrieval. They facilitate the movement of data from various sources into a central data warehouse or repository.
After trying all options existing on the market — from messaging systems to ETLtools — in-house data engineers decided to design a totally new solution for metrics monitoring and user activity tracking which would handle billions of messages a day. Another security measure is an audit log to track access. Large user community.
Data Integration and ETLTools As an Azure Data Engineer, master data integration and ETLtools crucial for seamless data processing. Azure Stream Analytics processes real-time data, while Azure Synapse Analytics provides comprehensive ETL capabilities with its SQL-based ETL processes.
Probably the One You Are Already Using Monitoring ETL with Data Observability Start ETL Monitoring with Monte Carlo The Trouble with Piecemeal Monitoring It’s something I’ve seen a hundred times: Something goes wrong with your ERP connection, and suddenly you can’t access your financial data. The Right ETL Monitoring Tool?
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content