This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. The transformations we apply under feature engineering prepares the data for ML model training.
The process of data extraction from source systems, processing it for data transformation, and then putting it into a target data system is known as ETL, or Extract, Transform, and Load. ETL has typically been carried out utilizing data warehouses and on-premise ETLtools.
If you work at a relatively large company, you've seen this cycle happening many times: Analytics team wants to use unstructured data on their models or analysis. For example, an industrial analytics team wants to use the logs from rawdata. The Data Warehouse(s) facilitates data ingestion and enables easy access for end-users.
What Is Data Engineering? Data engineering is the process of designing systems for collecting, storing, and analyzing large volumes of data. Put simply, it is the process of making rawdata usable and accessible to data scientists, business analysts, and other team members who rely on data.
It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. Over the past few years, data-driven enterprises have succeeded with the Extract Transform Load (ETL) process to promote seamless enterprise data exchange.
The Data Lake Pattern Emerging in contrast to the structured world of warehousing, data lakes cater to the dynamic and diverse nature of modern internet-based applications. These fluid conditions require unstructured data environments that natively operate with constantly changing formats, data structures, and data semantics.
ETL, or Extract, Transform, Load, is a process that involves extracting data from different data sources , transforming it into more suitable formats for processing and analytics, and loading it into the target system, usually a data warehouse. ETLdata pipelines can be built using a variety of approaches.
Loading is the process of warehousing the data in an accessible location. The difference here is that warehoused data is in its raw form, with the transformation only performed on-demand following information access. One of the leaders in the space focused on data transforms is dbt.
In today's data-driven world, where information reigns supreme, businesses rely on data to guide their decisions and strategies. However, the sheer volume and complexity of rawdata from various sources can often resemble a chaotic jigsaw puzzle.
In today's world, where data rules the roost, data extraction is the key to unlocking its hidden treasures. As someone deeply immersed in the world of data science, I know that rawdata is the lifeblood of innovation, decision-making, and business progress. What is data extraction?
The choice of tooling and infrastructure will depend on factors such as the organization’s size, budget, and industry as well as the types and use cases of the data. Data Pipeline vs ETL An ETL (Extract, Transform, and Load) system is a specific type of data pipeline that transforms and moves data across systems in batches.
A DataOps engineer must be familiar with extract, load, transform (ELT) and extract, transform, load (ETL) tools. Using automation to streamline data processing. To reduce development time and increase data reliability, DataOps engineers automate manual processes, such as data extraction and testing.
However, with the rise of the internet and cloud computing, data is now generated and stored across multiple sources and platforms. This dispersed data environment creates a challenge for businesses that need to access and analyze their data. The Transform Phase During this phase, the data is prepared for analysis.
Data testing tools: Key capabilities you should know Helen Soloveichik August 30, 2023 Data testing tools are software applications designed to assist data engineers and other professionals in validating, analyzing and maintaining data quality. There are several types of data testing tools.
A company’s production data, third-party ads data, click stream data, CRM data, and other data are hosted on various systems. An ETLtool or API-based batch processing/streaming is used to pump all of this data into a data warehouse. Snowflake is the pioneer in cloud data warehousing.
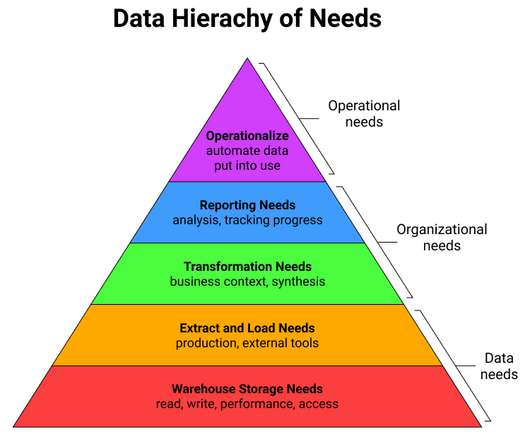
Like the core human needs, the ability to easily read and write warehouse data is fundamental. The rest of the steps are all built on this base by having all the key data in one accessible place. For example, a data engineer might load in data about purchases and returns from Stripe, their payments vendor.
DataOps Automation (Orchestration, Environment Management, Deployment Automation) DataOps Observability (Monitoring, Test Automation) Data Governance (Catalogs, Lineage, Stewardship) Data Privacy (Access and Compliance) Data Team Management (Projects, Tickets, Documentation, Value Stream Management) What are the drivers of this consolidation?
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Rawdata store section. Transformation section.
Now that we have understood how much significant role data plays, it opens the way to a set of more questions like How do we acquire or extract rawdata from the source? How do we transform this data to get valuable insights from it? Where do we finally store or load the transformed data?
Keeping data in data warehouses or data lakes helps companies centralize the data for several data-driven initiatives. While data warehouses contain transformed data, data lakes contain unfiltered and unorganized rawdata. What is a Big Data Pipeline?
In that case, ThoughtSpot also leverages ELT/ETLtools and Mode, a code-first AI-powered data solution that gives data teams everything they need to go from rawdata to the modern BI stack. The intuitive interface requires minimal training, enabling business users to quickly adopt the tool at any level.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Hadoop technology is the buzz word these days but most of the IT professionals still are not aware of the key components that comprise the Hadoop Ecosystem. Pig is SQL like but varies to a great extent.
Tableau Prep has brought in a new perspective where novice IT users and power users who are not backward faithfully can use drag and drop interfaces, visual data preparation workflows, etc., simultaneously making rawdata efficient to form insights. BigQuery), or another data storage solution. Excel), a cloud server (e.g.,
For example, a retail company might use EMR to process high volumes of transaction data from hundreds or thousands of different sources (point-of-sale systems, online sales platforms, and inventory databases). Arranging the rawdata could composite a 360-degree view of your sales customer integration across all channels.
Business intelligence (BI) is the collective name for a set of processes, systems, and technologies that turn rawdata into knowledge that can be used to operate enterprises profitably. Business intelligence solutions comBIne technology and strategy for gathering, analyzing, and interpreting data from internal and external sources.
Big Data Engineer identifies the internal and external data sources to gather valid data sets and deals with multiple cloud computing environments. Basic knowledge of ML technologies and algorithms will enable you to collaborate with the engineering teams and the Data Scientists.
You need all this data, some fragments of which are locked in silos in separate databases only certain groups of people have access to. This is something known as the “data silo problem,” meaning no team or department has a unified view of data. A newer way to integrate data into a centralized location is ELT.
Hence, learning and developing the required data engineer skills set will ensure a better future and can even land you better salaries in good companies anywhere in the world. After all, data engineer skills are required to collect data, transform it appropriately, and make it accessible to data scientists.
The rawdata is right there, ready to be reprocessed. All this rawdata goes into your persistent stage. Then, if you later refine your definition of what constitutes an “engaged” customer, having the rawdata in persistent staging allows for easy reprocessing of historical data with the new logic.
You may add new data regularly, but once you add the data, it does not change very frequently. Data is regularly updated. Data warehouses are optimized to handle complex queries, which can access multiple rows across many tables. There is a large amount of data involved. The amount of data is usually less.
The growing number of disparate sources that business analysts and data scientists need access to further complicates efforts. Unfortunately, a lot of enterprise data is underutilized. Underutilized data often leads to lost opportunities as data loses its value, or decays, over time.
Companies are drowning in a sea of rawdata. As data volumes explode across enterprises, the struggle to manage, integrate, and analyze it is getting real. Thankfully, with serverless data integration solutions like Azure Data Factory (ADF), data engineers can easily orchestrate, integrate, transform, and deliver data at scale.
What is Databricks Databricks is an analytics platform with a unified set of tools for data engineering, data management , data science, and machine learning. It combines the best elements of a data warehouse, a centralized repository for structured data, and a data lake used to host large amounts of rawdata.
A 2023 Salesforce study revealed that 80% of business leaders consider data essential for decision-making. However, a Seagate report found that 68% of available enterprise data goes unleveraged, signaling significant untapped potential for operational analytics to transform rawdata into actionable insights.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content