

Hadoop vs Spark: Main Big Data Tools Explained
AltexSoft
JUNE 7, 2021
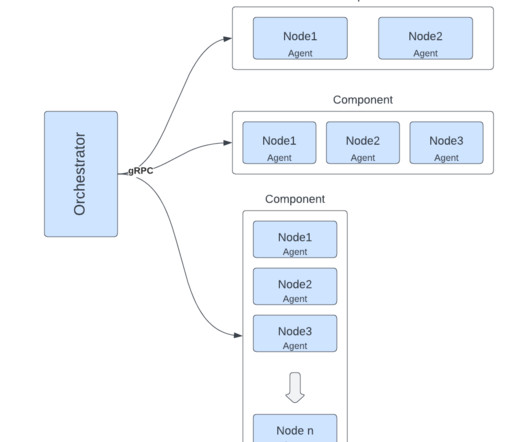
Hadoop and Spark are the two most popular platforms for Big Data processing. To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop? To come to the right decision, we need to divide this big question into several smaller ones — namely: What is Hadoop? scalability.















































Let's personalize your content