This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary Streaming data processing enables new categories of data products and analytics. Unfortunately, reasoning about stream processing engines is complex and lacks sufficient tooling. Support Data Engineering Podcast Summary Streaming data processing enables new categories of data products and analytics.
Once it is running, the next challenge is figuring out how to address release management for all of the different component parts. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management This episode is supported by Code Comments, an original podcast from Red Hat.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. feature on Facebook.
Summary Data processing technologies have dramatically improved in their sophistication and raw throughput. Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Data lakes are notoriously complex. What are the open questions today in technical scalability of data engines?
Speaker: Donna Laquidara-Carr, PhD, LEED AP, Industry Insights Research Director at Dodge Construction Network
In today’s construction market, owners, construction managers, and contractors must navigate increasing challenges, from cost management to project delays. Fortunately, digital tools now offer valuable insights to help mitigate these risks. That’s where data-driven construction comes in.
In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. After Zynga, he rejoined Amazon, and was the General Manager (GM) for Compute services at AWS, and later chief of staff, and advisor to AWS executives like Charlie Bell and Andy Jassy (Amazon’s current CEO.)
I am pleased to announce that Cloudera has achieved FedRAMP “In Process”, a significant milestone that underscores our commitment to providing the public sector with secure and reliable data management solutions across on-prem, hybrid and multi-cloud environments.
When most people think of master data management, they first think of customers and products. The business must also manage locations, including warehouses, offices, and subsidiaries, not to mention the various addresses associated with virtually every data element the business manages. Four main challenges make MDM complex.
Other shipped things include DALL·E 3 (image generation,) GPT-4 (an advanced model,) and the OpenAI API which developers and companies use to integrate AI into their processes. I managed our entire Applied Engineering org from its earliest days through the launch and scaling of ChatGPT.
Snowflake joined forces with Merit to provide an identity verification platform and a set of program delivery services that help run large-scale government programs in areas such as licensing regulations, workforce development, emergency management, and educational grants and scholarships.
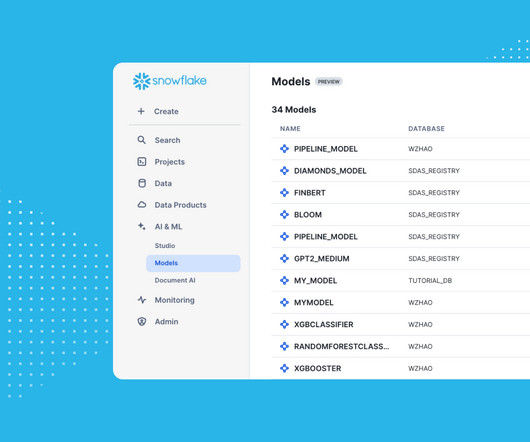
Bringing machine learning (ML) models into production is often hindered by fragmented MLOps processes that are difficult to scale with the underlying data. The friction of having to set up and manage separate environments for features and models creates operational complexity that can be costly to maintain and difficult to use.
In recent years, Meta’s data management systems have evolved into a composable architecture that creates interoperability, promotes reusability, and improves engineering efficiency. A few years ago we embarked on a journey to address these shortcomings by rethinking how our data management systems were designed.
Cloudera, together with Octopai, will make it easier for organizations to better understand, access, and leverage all their data in their entire data estate – including data outside of Cloudera – to power the most robust data, analytics and AI applications.
In every issue, I cover topics related to Big Tech and high-growth startups through the lens of engineering managers and senior engineers. ” I managed to talk to someone in this company’s HR department, who confirmed that the leadership set a goal to improve the business’s Glassdoor rating.
This new convergence helps Meta and the larger community build data management systems that are unified, more efficient, and composable. Meta’s Data Infrastructure teams have been rethinking how data management systems are designed. An introduction to Velox Velox is the first project in our composable data management system program.
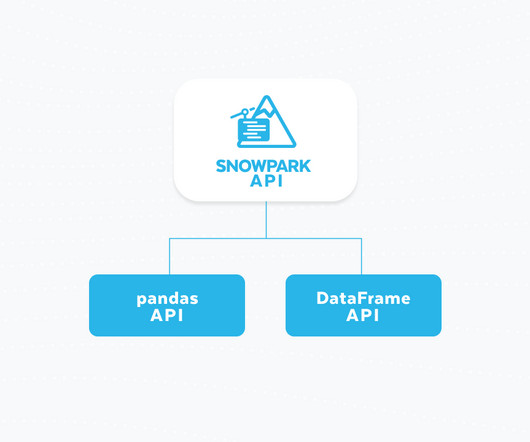
. "Serverless computing" has enabled customers to use cloud capabilities without provisioning, deploying and managing either hardware or software resources. Snowflake has embraced serverless since our founding in 2012, with customers providing their code to load, manage and query data and us taking care of the rest.
Organist is a tool meant to do just that: Provide you with an ergonomic way of managing the complexity of your development environment. Asking contributors to apt get something just to contribute to your project is both a hindrance, and a source of failure and friction in the setup process. As much as possible, it should: Remain local.
Without the backing of management, a large-scale rewrite is likely to fail. My goal was to fix the debt of hardcoded strings, but I learned a lot about the codebase and our process as I did it. In 2004, I was hired by ISO-NE, a non-profit that manages the electric grid in New England. Big rewrites need heavyweight support.
Addressing a lack of in-house AI expertise and simplifying AI processes can make adoption easier. Snowflake Cortex AI is a fully managed service designed to unlock the potential of the technology for everyone within an organization, regardless of their technical expertise. That’s where Snowflake comes in.
In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. Diagnosis: Customers may be unable to access Cloud resources in europe-west9-a Workaround: Customers can fail over to other zones.” We apologize to all who are affected by the disruption.
In every issue, I cover topics related to Big Tech and startups through the lens of engineering managers and senior engineers. Today, full subscribers got access to a comprehensive Senior-and-above tech compensation research. Source: Cognition So far, all we have is video demos, and accounts of those with access to this tool.
Announcements Hello and welcome to the Data Engineering Podcast, the show about modern data management Introducing RudderStack Profiles. What motivated to write a book about how to manage Kafka in production? Can you describe your experiences with Kafka? There are many options now for persistent data queues.
The traditional ways of operations management are over modernization and holistic approaches are now essential. For IT operations (ITOps) teams, 2025 means reassessing technology stacks, processes, and people. Success in tackling modernization of IT operations management starts with assessing where your team is. Whats next?
In this episode Andrew Jefferson explains the complexities of building a robust system for data sharing, the techno-social considerations, and how the Bobsled platform that he is building aims to simplify the process. What are the requirements around governance and auditability of data access that need to be addressed when sharing data?
Summary Stream processing systems have long been built with a code-first design, adding SQL as a layer on top of the existing framework. RisingWave is a database engine that was created specifically for stream processing, with S3 as the storage layer. Can you describe what RisingWave is and the story behind it? Starburst : 
















































Let's personalize your content