This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Cloudera, together with Octopai, will make it easier for organizations to better understand, access, and leverage all their data in their entire data estate – including data outside of Cloudera – to power the most robust data, analytics and AI applications.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making data accessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. feature on Facebook.
Meta’s vast and diverse systems make it particularly challenging to comprehend its structure, meaning, and context at scale. We discovered that a flexible and incremental approach was necessary to onboard the wide variety of systems and languages used in building Metas products. We believe that privacy drives product innovation.
The world we live in today presents larger datasets, more complex data, and diverse needs, all of which call for efficient, scalable data systems. These systems are built on open standards and offer immense analytical and transactional processing flexibility. These formats are transforming how organizations manage large datasets.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There
Data fabric is a unified approach to data management, creating a consistent way to manage, access, and share data across distributed environments. With data volumes skyrocketing, and complexities increasing in variety and platforms, traditional centralized data management systems often struggle to keep up.
The data warehouse solved for performance and scale but, much like the databases that preceded it, relied on proprietary formats to build vertically integrated systems. Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage.
By Ko-Jen Hsiao , Yesu Feng and Sudarshan Lamkhede Motivation Netflixs personalized recommender system is a complex system, boasting a variety of specialized machine learned models each catering to distinct needs including Continue Watching and Todays Top Picks for You. Refer to our recent overview for more details).
We are committed to building the data control plane that enables AI to reliably access structured data from across your entire data lineage. Both AI agents and business stakeholders will then operate on top of LLM-driven systems hydrated by the dbt MCP context. What is MCP? Why does this matter? MCP addresses this challenge.
It is a critical and powerful tool for scalable discovery of relevant data and data flows, which supports privacy controls across Metas systems. It enhances the traceability of data flows within systems, ultimately empowering developers to swiftly implement privacy controls and create innovative products. Hack, C++, Python, etc.)
Summary The majority of blog posts and presentations about data engineering and analytics assume that the consumers of those efforts are internal business users accessing an environment controlled by the business. Atlan is the metadata hub for your data ecosystem. How is everyone going to find the data they need, and understand it?
And for that future to be a reality, data teams must shift their attention to metadata, the new turf war for data. The need for unified metadata While open and distributed architectures offer many benefits, they come with their own set of challenges. Data teams actually need to unify the metadata. Open data is the future.
ThoughtSpot prioritizes the high availability and minimal downtime of our systems to ensure a seamless user experience. In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadataaccess and management are critical for optimal system performance.
For years, an essential tenet of digital transformation has been to make data accessible, to break down silos so that the enterprise can draw value from all of its data. Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
Next, look for automatic metadata scanning. This basically means the tool updates itself by pulling in changes to data structures from your systems. Finally, access control helps keep things organized. OpenMetadata Source: DataHub Then theres OpenMetadata , which is kind of like the Swiss Army knife of metadata tools.
ConsoleMe: A Central Control Plane for AWS Permissions and Access By Curtis Castrapel , Patrick Sanders , and Hee Won Kim At AWS re:Invent 2020, we open sourced two new tools for managing multi-account AWS permissions and access. Groups beyond software engineering teams are standing up their own systems and automation.
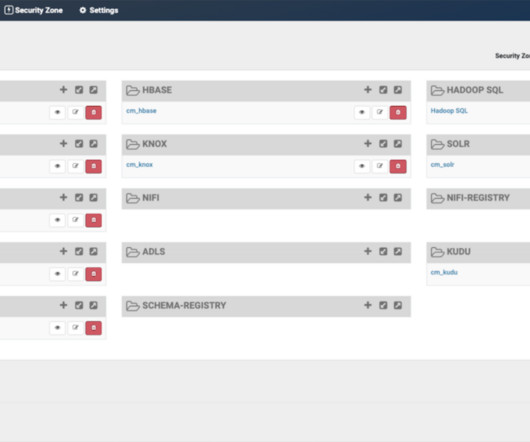
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. In a good data governance strategy, it is important to define roles that allow the business to limit the level of access that users can have to their strategic data assets.
ERP and CRM systems are designed and built to fulfil a broad range of business processes and functions. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the raw data. Accessibility : I could easily request access to these data products.
You can observe your pipelines with built in metadata search and column level lineage. Your host is Tobias Macey and today I’m interviewing Guy Yachdav, Director of Software Engineering at Immunai, about his work at Immunai to wrangle biological data for advancing research into the human immune system. regulatory, security, etc.)
In this blog post, we will talk about a single Ozone cluster with the capabilities of both Hadoop Core File System (HCFS) and Object Store (like Amazon S3). A unified storage architecture that can store both files and objects and provide a flexible, scalable, and high-performance system. Bucket types. release version.
Ransomware is a type of malicious software that encrypts a victim's data or locks their device, demanding a ransom to restore access or to not expose the data. Prevention Access controls Access to Snowflake infrastructure is protected by multiple layers of security (defense in depth and zero trust ).
Hadoop achieved this through distributed processing and storage, using a framework called MapReduce and the Hadoop Distributed File System (HDFS). This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., If not handled correctly, managing this metadata can become a bottleneck.
With the surge of new tools, platforms, and data types, managing these systems effectively is an ongoing challenge. Ultimately, they are trying to serve data in their marketplace and make it accessible to business and data consumers,” Yoğurtçu says. Focus on metadata management. Cloud modernization presents challenges.
These enhancements improve data accessibility, enable business-friendly governance, and automate manual processes. Many businesses face roadblocks within their critical enterprise data, including struggles to achieve greater accessibility, business-friendly governance, and automation.
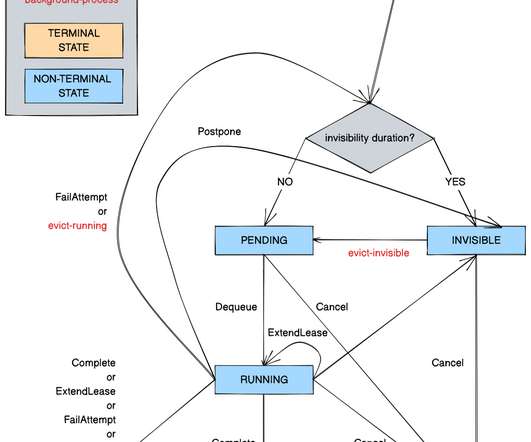
Timestone: Netflix’s High-Throughput, Low-Latency Priority Queueing System with Built-in Support for Non-Parallelizable Workloads by Kostas Christidis Introduction Timestone is a high-throughput, low-latency priority queueing system we built in-house to support the needs of Cosmos , our media encoding platform. Over the past 2.5
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems.
AI agents, autonomous systems that perform tasks using AI, can enhance business productivity by handling complex, multi-step operations in minutes. Agents need to access an organization's ever-growing structured and unstructured data to be effective and reliable. text, audio) and structured (e.g.,
It serves as a vital protective measure, ensuring proper data access while managing risks like data breaches and unauthorized use. Strong data governance also lays the foundation for better model performance, cost efficiency, and improved data quality, which directly contributes to regulatory compliance and more secure AI systems.
What are the other systems that feed into and rely on the Trino/Iceberg service? what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? Email hosts@dataengineeringpodcast.com with your story.
Instead of maintaining separate systems for structured data and image processing, data analysts and scientists can now work within the familiar Snowflake environment, using simple SQL to explore correlations between traditional metrics and visual intelligence. Sonnet, Mistral AIs Pixtral Large , and the upcoming Anthropics Claude 3.7
Metadata is the information that provides context and meaning to data, ensuring it’s easily discoverable, organized, and actionable. Imagine a library with millions of books but no catalog system to organize them. This is what managing data without metadata feels like. What is Metadata? Chaos, right?
Ingest data more efficiently and manage costs For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
On average, engineers spend over half of their time maintaining existing systems rather than developing new solutions. Are your tools simple to implement and accessible to users with diverse skill sets? Create a Plan for Integration: Automation tools need to work seamlessly with existing systems to be effective.
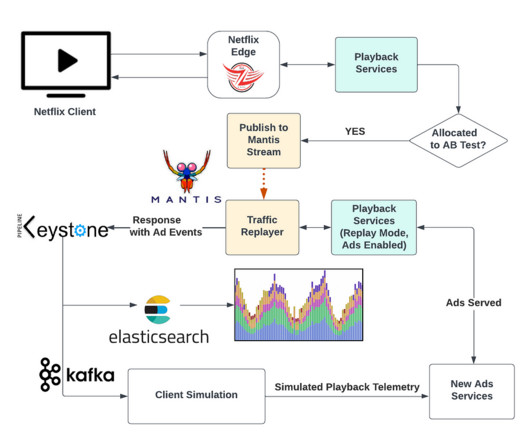
In this blog post, we’ll discuss the methods we used to ensure a successful launch, including: How we tested the system Netflix technologies involved Best practices we developed Realistic Test Traffic Netflix traffic ebbs and flows throughout the day in a sinusoidal pattern. Basic with ads was launched worldwide on November 3rd.
We accomplish this by paving the path to: Accessing and processing media data (e.g. Media Access: Jasper In the early days of media ML efforts, it was very hard for researchers to access media data. Training Performance Media model training poses multiple system challenges in storage, network, and GPUs.
The commonly-accepted best practice in database system design for years is to use an exhaustive search strategy to consider all the possible variations of specific database operations in a query plan. Metadata Caching. Impala’s planner simplifies planning in several ways. More on this below.
We are pleased to announce that Cloudera has been named a Leader in the 2022 Gartner ® Magic Quadrant for Cloud Database Management Systems. Many of our customers use multiple solutions—but want to consolidate data security, governance, lineage, and metadata management, so that they don’t have to work with multiple vendors.
Snowflake Horizon is Snowflake’s built-in governance solution with a unified set of compliance, security, privacy, interoperability, and access capabilities. Snowflake continues to advance Snowflake Horizon with additional capabilities for compliance, security, privacy, interoperability, and access.
It requires a state-of-the-art system that can track and process these impressions while maintaining a detailed history of each profiles exposure. In this multi-part blog series, we take you behind the scenes of our system that processes billions of impressions daily.
At the same time, organizations must ensure the right people have access to the right content, while also protecting sensitive and/or Personally Identifiable Information (PII) and fulfilling a growing list of regulatory requirements. Additional built-in UI’s and privacy enhancements make it even easier to understand and manage sensitive data.
In medicine, lower sequencing costs and improved clinical access to NGS technology has been shown to increase diagnostic yield for a range of diseases, from relatively well-understood Mendelian disorders, including muscular dystrophy and epilepsy , to rare diseases such as Alagille syndrome.
Kafka is designed to be a black box to collect all kinds of data, so Kafka doesn't have built-in schema and schema enforcement; this is the biggest problem when integrating with schematized systems like Lakehouse. This capability, termed Union Read, allows both layers to work in tandem for highly efficient and accurate data access.
Application Logic: Application logic refers to the type of data processing, and can be anything from analytical or operational systems to data pipelines that ingest data inputs, apply transformations based on some business logic and produce data outputs. Data and Metadata: Data inputs and data outputs produced based on the application logic.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content