This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Enabling Stakeholder dataaccess with RAGs 3.1. Loading: Read rawdata and convert them into LlamaIndex data structures 3.2.1. Read data from structured and unstructured sources 3.2.2. Transform data into LlamaIndex data structures 3.3. Introduction 2. Set up 3.1.1. Pre-requisite 3.1.2.
Here we explore initial system designs we considered, an overview of the current architecture, and some important principles Meta takes into account in making dataaccessible and easy to understand. Users have a variety of tools they can use to manage and access their information on Meta platforms. What are data logs?
(Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today. A data lake!
This architecture is valuable for organizations dealing with large volumes of diverse data sources, where maintaining accuracy and accessibility at every stage is a priority. It sounds great, but how do you prove the data is correct at each layer? How do you ensure data quality in every layer ?
Speaker: Donna Laquidara-Carr, PhD, LEED AP, Industry Insights Research Director at Dodge Construction Network
However, the sheer volume of tools and the complexity of leveraging their data effectively can be daunting. That’s where data-driven construction comes in. It integrates these digital solutions into everyday workflows, turning rawdata into actionable insights.
A big challenge is to support and manage multiple semantically enriched data models for the same underlying data, e.g., into a graph data model to trace value flow or into a MapReduce-compatible data model of the UTXO-based Bitcoin blockchain. Why does on-chain data matter? On our API instances, we use Socket.IO
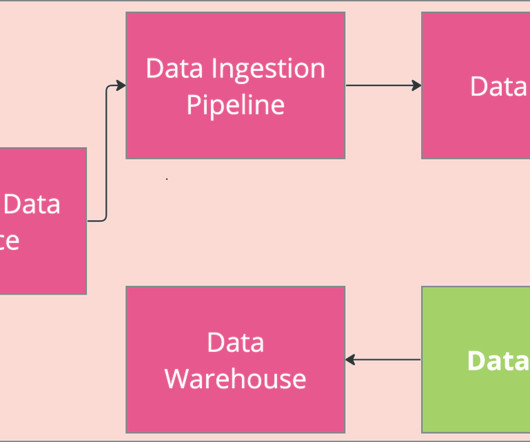
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform rawdata into valuable insights.
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. Additionally, we launched cross-region inference , allowing you to access preferred LLMs even if they aren’t available in your primary region.
The startup was able to start operations thanks to getting access to an EU grant called NGI Search grant. As always, I have not been paid to write about this company and have no affiliation with it – see more in my ethics statement. Funding and team size The company got started thanks to a €150K ($165K) EU grant.
Google Analytics, a tool widely used by marketers, provides invaluable insights into website performance, user behavior and critical analytic data that helps marketers understand the customer journey and improve marketing ROI. In the case of rawdata, it replicates it directly from the BigQuery storage layer.
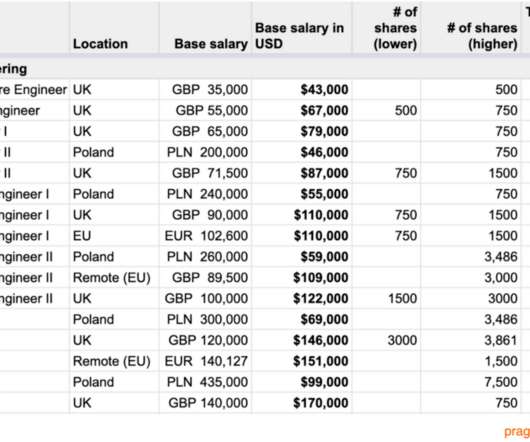
In this week’s The Scoop, I analyzed this information and dissected it, going well beyond the rawdata. Here are a few details from the data points, focusing on software engineering compensation. How can you use this data in budgeting, and what are the caveats to be aware of?
What is Data Transformation? Data transformation is the process of converting rawdata into a usable format to generate insights. It involves cleaning, normalizing, validating, and enriching data, ensuring that it is consistent and ready for analysis.
Gone are the days of just dumping everything into a single database; modern data architectures typically use a combination of data lakes and warehouses. Think of your data lake as a vast reservoir where you store rawdata in its original form—great for when you’re not quite sure how you’ll use it yet.
As you do not want to start your development with uncertainty, you decide to go for the operational rawdata directly. Accessing Operational Data I used to connect to views in transactional databases or APIs offered by operational systems to request the rawdata. Does it sound familiar?
The data industry has a wide variety of approaches and philosophies for managing data: Inman data factory, Kimball methodology, s tar schema , or the data vault pattern, which can be a great way to store and organize rawdata, and more. Data mesh does not replace or require any of these.
What times of the day are busy in the area, and are roads accessible? Data enrichment helps provide a 360 o view which informs better decisions around insuring, purchasing, financing, customer targeting, and more. Together, data validation and enrichment form a powerful combination that delivers even bigger results for your business.
You can utilize Snowflake-managed Iceberg tables to be a full participant in your data lake and take advantage of features like automated table maintenance, Automatic Clustering , transformation with Snowpark and much more. Supporting Iceberg as a storage format for Dynamic Tables will simplify data processing for data lakes and lakehouses.
Imagine accessing more detail based on each customer’s home address. You need reference data sets from trusted, authoritative sources like Precisely to do that. The post Use Data Enrichment to Supercharge AI appeared first on Precisely.
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
A look inside Snowflake Notebooks: A familiar notebook interface, integrated within Snowflake’s secure, scalable platform Keep all your data and development workflows within Snowflake’s security boundary, minimizing the need for data movement. Access Snowflake platform capabilities and data sets directly within your notebooks.
Furthermore, the same tools that empower cybercrime can drive fraudulent use of public-sector data as well as fraudulent access to government systems. In financial services, another highly regulated, data-intensive industry, some 80 percent of industry experts say artificial intelligence is helping to reduce fraud.
It is seamlessly integrated across Meta’s platforms, increasing user access to AI insights, and leverages a larger dataset to enhance its capacity to handle complex tasks. This is due to the fact that they are not sufficiently refined and that they are trained using publicly available, publicly published rawdata.
Metrics API: It provides a Metrics API that not only gives meaning to your rawdata but also empowers your dev teams across the company to build with a self-service analytics API. Multi-tenant security: It controls access to your data in customer-facing, multi-tenant environments.
Extract and Load This phase includes VDK jobs calling the Europeana REST API to extract rawdata. This example requires an active Internet connection to work correctly to access the Europeana REST API. This operation is a batch process because it downloads data only once and does not require streamlining.
And even when we manage to streamline the data workflow, those insights aren’t always accessible to users unfamiliar with antiquated business intelligence tools. That’s why ThoughtSpot and Fivetran are joining forces to decrease the amount of time, steps, and effort required to go from rawdata to AI-powered insights.
If the data of interest isn’t already available in the structured part of the data warehouse, chances are that the analyst will proceed with a short term solution querying rawdata, while the data engineer may help in properly logging and eventually carrying that data into the warehouse.
Can you provide some examples of the structures that could be created to facilitate data sharing across organizational boundaries? Many companies view their data as a strategic asset and are therefore loathe to provide access to other individuals or organizations.
Multiple levels: Rawdata is accepted by the input layer. What follows is a list of what each neuron does: Input Reception: Neurons receive inputs from other neurons or rawdata. There is a distinct function for each layer in the processing of data: Input Layer: The first layer of the network.
Access — you will be able to namespace models with groups and visibility. Data Engineering at Adyen — "Data engineers at Adyen are responsible for creating high-quality, scalable, reusable and insightful datasets out of large volumes of rawdata" This is a good definition of one of the possible responsibilities of DE.
It looks like this: Data collection This part deals with the collection of rawdata from various resources. All this data needs to be collected and stored in a place which is easy to access while working with the data. Data cleaning This is considered as one of the most important steps in data science.
The CDN manages caching and path optimization from the customer to Agoda, mitigating some common local access problems of remote locations. It also utilizes this distributed platform for security purposes, enriching data sent to the on-prem fraud detection platform. For its data platform , Agoda builds on top of Spark.
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your rawdata and transformed datasets optimized for AI-powered analytics with ThoughtSpot. Set refresh schedules as needed.
The data and the techniques presented in this prototype are still applicable as creating a PCA feature store is often part of the machine learning process. . The process followed in this prototype covers several steps that you should follow: Data Ingest – move the rawdata to a more suitable storage location.
The greatest data processing challenge of 2024 is the lack of qualified data scientists with the skill set and expertise to handle this gigantic volume of data. Inability to process large volumes of data Out of the 2.5 quintillion data produced, only 60 percent workers spend days on it to make sense of it.
Digital marketing is ideally suited for precise targeting and rapid feedback, provided that business users have access to the detailed demographic and geospatial data they need. To learn more read our eBook Validation and Enrichment: Harnessing Insights from RawData.
Data teams can use uniqueness tests to measure their data uniqueness. Uniqueness tests enable data teams to programmatically identify duplicate records to clean and normalize rawdata before entering the production warehouse.
SaaS Software as a Service is a cloud hosting model where users subscribe to gain access to services instead of purchasing software or equipment. Informatica Informatica is a leading industry tool used for extracting, transforming, and cleaning up rawdata.
Aside from this asset, some of the advantages are as follows: Increased flexibility: As more people work online, HR departments and workers are searching for ways to monitor data from a distance. An HR analytics dashboard allows for real-time HR-to-employee communication and access to critical information.
Dataform enables the application of software engineering best practices such as testing, environments, version control, dependencies management, orchestration and automated documentation to data pipelines. Dataform requires credentials to access GitHub when checking out the code stored on a remote repository.
constraints on data manipulation, security, privacy concerns, etc.) How does Unomi help with the new third party data restrictions ? Why is access to rawdata so important ? constraints on data manipulation, security, privacy concerns, etc.) How does Unomi help with the new third party data restrictions ?
In the real world, data is not open source , as it is confidential and may contain very sensitive information related to an item , user or product. But rawdata is available as open source for beginners and learners who wish to learn technologies associated with data.
Placing responsibility for all the data sets on one data engineering team creates bottlenecks. Let’s consider how to break up our architecture into data mesh domains. In figure 4, we see our rawdata shown on the left. First, the data is mastered, usually by a centralized data engineering team or IT.
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content