This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
(Not to mention the crazy stories about Gen AI making up answers without the data to back it up!) Are we allowed to use all the data, or are there copyright or privacy concerns? These are all big questions about the accessibility, quality, and governance of data being used by AI solutions today.
However, scaling LLM data processing to millions of records can pose data transfer and orchestration challenges, easily addressed by the user-friendly SQL functions in Snowflake Cortex. Traditionally, SQL has been limited to structureddata neatly organized in tables.
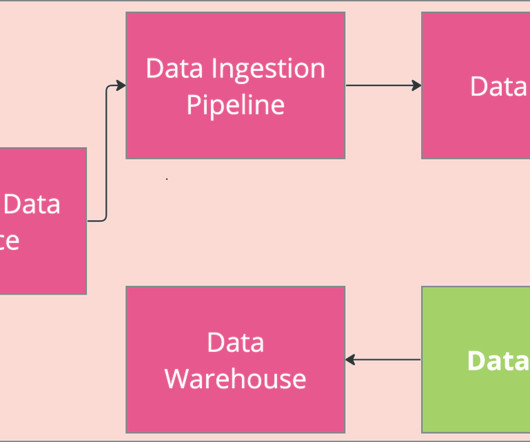
Collecting, cleaning, and organizing data into a coherent form for business users to consume are all standard data modeling and data engineering tasks for loading a data warehouse. Based on Tecton blog So is this similar to data engineering pipelines into a data lake/warehouse?
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your rawdata and transformed datasets optimized for AI-powered analytics with ThoughtSpot. Set refresh schedules as needed.
Understanding the essential components of data pipelines is crucial for designing efficient and effective data architectures. Third-Party Data: External data sources that your company does not collect directly but integrates to enhance insights or support decision-making.
Multiple levels: Rawdata is accepted by the input layer. What follows is a list of what each neuron does: Input Reception: Neurons receive inputs from other neurons or rawdata. There is a distinct function for each layer in the processing of data: Input Layer: The first layer of the network.
Dataform enables the application of software engineering best practices such as testing, environments, version control, dependencies management, orchestration and automated documentation to data pipelines. Dataform requires credentials to access GitHub when checking out the code stored on a remote repository.
In today's data-driven world, where information reigns supreme, businesses rely on data to guide their decisions and strategies. However, the sheer volume and complexity of rawdata from various sources can often resemble a chaotic jigsaw puzzle.
We will also address some of the key distinctions between platforms like Hadoop and Snowflake, which have emerged as valuable tools in the quest to process and analyze ever larger volumes of structured, semi-structured, and unstructured data. They may want to look at those numbers on a daily or weekly basis.
Structuringdata refers to converting unstructured data into tables and defining data types and relationships based on a schema. Autonomous data warehouse from Oracle. . What is Data Lake? . Essentially, a data lake is a repository of rawdata from disparate sources. Flexibility .
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
The Data Lake: A Reservoir of Unstructured Potential A data lake is a centralized repository that stores vast amounts of rawdata. It can store any type of data — structured, unstructured, and semi-structured — in its native format, providing a highly scalable and adaptable solution for diverse data needs.
What is unstructured data? Definition and examples Unstructured data , in its simplest form, refers to any data that does not have a pre-defined structure or organization. It can come in different forms, such as text documents, emails, images, videos, social media posts, sensor data, etc.
Understanding data warehouses A data warehouse is a consolidated storage unit and processing hub for your data. Teams using a data warehouse usually leverage SQL queries for analytics use cases. This same structure aids in maintaining data quality and simplifies how users interact with and understand the data.
In today's world, where data rules the roost, data extraction is the key to unlocking its hidden treasures. As someone deeply immersed in the world of data science, I know that rawdata is the lifeblood of innovation, decision-making, and business progress. What is data extraction?
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structureddata? Consider whether you need a solution that supports one or multiple data formats.
The spectrum of sources from which data is collected for the study in Data Science is broad. These data have been accessible to us because of the advanced and latest technologies which are used in the collection of data. What is the role of a Data Engineer?
The term was coined by James Dixon , Back-End Java, Data, and Business Intelligence Engineer, and it started a new era in how organizations could store, manage, and analyze their data. This article explains what a data lake is, its architecture, and diverse use cases. Data sources can be broadly classified into three categories.
As the magnitude and role of data in society has changed, so have the tools for dealing with it. While a +3500 year data retention capability for data stored on clay tablets is impressive, the access latency and forward compatibility of clay tablets fall a little short. Book a Demo!
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structureddata? Consider whether you need a solution that supports one or multiple data formats.
To choose the most suitable data management solution for your organization, consider the following factors: Data types and formats: Do you primarily work with structured, unstructured, or semi-structureddata? Consider whether you need a solution that supports one or multiple data formats.
Focus Exploration and discovery of hidden patterns and trends in data. Reporting, querying, and analyzing structureddata to generate actionable insights. Data Sources Diverse and vast data sources, including structured, unstructured, and semi-structureddata.
Data integration with ETL has evolved from structureddata stores with high computing costs to natural state storage with read operation alterations thanks to the agility of the cloud. Data integration with ETL has changed in the last three decades. This ensures that companies' data is always protected and secure.
The insights derived from the data in hand are then turned into impressive business intelligence visuals such as graphs or charts for the executive management to make strategic decisions. In this post, we will discuss the top power BI developer skills required to access Microsoft’s power business intelligence software.
When it comes to storing large volumes of data, a simple database will be impractical due to the processing and throughput inefficiencies that emerge when managing and accessing big data. This article looks at the options available for storing and processing big data, which is too large for conventional databases to handle.
That’s why some MDS tools are commercial distributions designed to be low-code or even no-code, making them accessible to data practitioners with minimal technical expertise. This means that companies don’t necessarily need a large data engineering team. Data democratization. Data storage component in a modern data stack.
Cleaning Bad data can derail an entire company, and the foundation of bad data is unclean data. Therefore it’s of immense importance that the data that enters a data warehouse needs to be cleaned. Data Transformation Rawdata ingested into a data warehouse may not be suitable for analysis.
Organisations and businesses are flooded with enormous amounts of data in the digital era. Rawdata, however, is frequently disorganised, unstructured, and challenging to work with directly. Data processing analysts can be useful in this situation.
Get FREE Access to Data Analytics Example Codes for Data Cleaning, Data Munging, and Data Visualization Hadoop technology is the buzz word these days but most of the IT professionals still are not aware of the key components that comprise the Hadoop Ecosystem. Pig is SQL like but varies to a great extent.
You have probably heard the saying, "data is the new oil". It is extremely important for businesses to process data correctly since the volume and complexity of rawdata are rapidly growing. However, the vast volume of data will overwhelm you if you start looking at historical trends. Well, it surely is!
Data collection revolves around gathering rawdata from various sources, with the objective of using it for analysis and decision-making. It includes manual data entries, online surveys, extracting information from documents and databases, capturing signals from sensors, and more.
At the same time, it brings structure to data and empowers data management features similar to those in data warehouses by implementing the metadata layer on top of the store. Traditional data warehouse platform architecture. Another type of data storage — a data lake — tried to address these and other issues.
More importantly, we will contextualize ELT in the current scenario, where data is perpetually in motion, and the boundaries of innovation are constantly being redrawn. Extract The initial stage of the ELT process is the extraction of data from various source systems. What Is ELT? So, what exactly is ELT?
Data Validation : Perform quality checks to ensure the data meets quality and accuracy standards, guaranteeing its reliability for subsequent analysis. Data Storage : Store validated data in a structured format, facilitating easy access for analysis. Used for identifying and cataloging data sources.
Business Intelligence and Artificial Intelligence are popular technologies that help organizations turn rawdata into actionable insights. While both BI and AI provide data-driven insights, they differ in how they help businesses gain a competitive edge in the data-driven marketplace. PREVIOUS NEXT <
In broader terms, two types of data -- structured and unstructured data -- flow through a data pipeline. The structureddata comprises data that can be saved and retrieved in a fixed format, like email addresses, locations, or phone numbers. What is a Big Data Pipeline?
When the business intelligence needs change, they can go query the rawdata again. ELT: source Data Lake vs Data Warehouse Data lake stores rawdata. The purpose of the data is not determined. The data is easily accessible and is easy to update.
4 Purpose Utilize the derived findings and insights to make informed decisions The purpose of AI is to provide software capable enough to reason on the input provided and explain the output 5 Types of Data Different types of data can be used as input for the Data Science lifecycle.
The Data Lake Pattern Emerging in contrast to the structured world of warehousing, data lakes cater to the dynamic and diverse nature of modern internet-based applications. These fluid conditions require unstructured data environments that natively operate with constantly changing formats, datastructures, and data semantics.
Reading Time: 8 minutes In the world of data engineering, a mighty tool called DBT (Data Build Tool) comes to the rescue of modern data workflows. Imagine a team of skilled data engineers on an exciting quest to transform rawdata into a treasure trove of insights.
To work with the VCF data, we first need to define an ingestion and parsing function in Snowflake to apply to the rawdata files. All other variable elements in these semi-structured columns can be queried in a similar way. Still it is useful for illustrating the joining of genomes to properties of the samples.
This means that a data warehouse is a collection of technologies and components that are used to store data for some strategic use. Data is collected and stored in data warehouses from multiple sources to provide insights into business data. Data from data warehouses is queried using SQL.
By accommodating various data types, reducing preprocessing overhead, and offering scalability, data lakes have become an essential component of modern data platforms , particularly those serving streaming or machine learning use cases. AWS is one of the most popular data lake vendors.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content